# 配置内存
# 1.内存架构
# 1.1.概述
Ignite内存架构通过可以同时在内存和磁盘上存储和处理数据及索引,得到了支持磁盘持久化的内存级性能。

多层存储的运行方式类似于操作系统(例如Linux)的虚拟内存。但是这两种类型架构之间的主要区别是,多层存储始终将磁盘视为数据的超集(如果启用了持久化),在故障或者重启后仍然可以保留数据,而传统的虚拟内存仅将磁盘作为交换扩展,一旦进程停止,数据就会被清除。
# 1.2.内存架构
多层架构是一种基于固定大小页面的内存架构,这些页面存储在内存(Java堆外)的托管非堆区中,并按磁盘上的特定层次结构进行组织。
Ignite在内存和磁盘上都维护相同的二进制数据表示形式,这样在内存和磁盘之间移动数据时就不需要进行昂贵的序列化。
下图说明了多层存储架构:
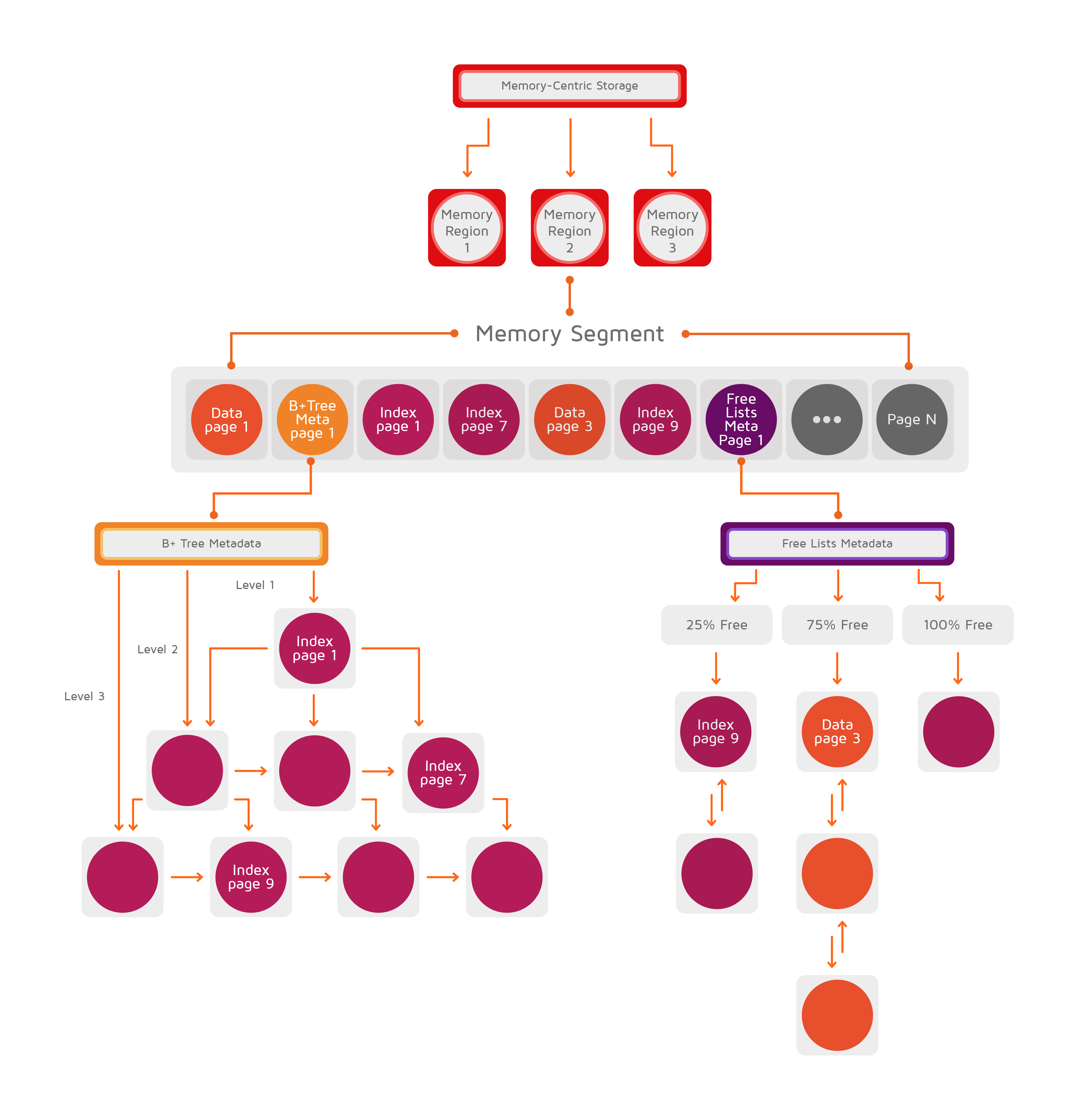
# 1.2.1.内存段
每个数据区均以初始大小开始,并具有可以增长到的最大大小。该区域通过分配连续的内存段扩展到其最大大小。
内存段是从操作系统分配的物理内存的连续字节数组,该数组被拆分为固定大小的页面。该段中可以存在几种类型的页面,如下图所示。

# 1.2.2.数据页面
数据页面存储从应用端写入缓存的条目。
通常每个数据页面持有多个键值条目,以便尽可能高效地使用内存并避免内存碎片。将新条目添加到缓存后,Ignite会寻找一个适合整个键-值条目的最佳页面。
但是如果一个条目的总大小超过了DataStorageConfiguration.setPageSize(..)属性配置的页面大小,则该条目将占用多个数据页面。
提示
如果有许多缓存条目无法容纳在单个页面中,那么增加页面大小配置参数是有必要的。
如果在更新期间条目大小扩大并超过了其数据页面的剩余可用空间,则Ignite会搜索新的空间足够的数据页面,并将其移到那里。
# 1.2.3.内存碎片整理
Ignite自动执行内存碎片整理,不需要用户干预。
随着时间的推移,每个数据页面可能会通过不同的CRUD操作多次更新,这会导致页面和整体内存碎片化。为了最大程度地减少内存碎片,只要页面碎片过多,Ignite都会使用页面压缩。
压缩的数据页面如下图所示:
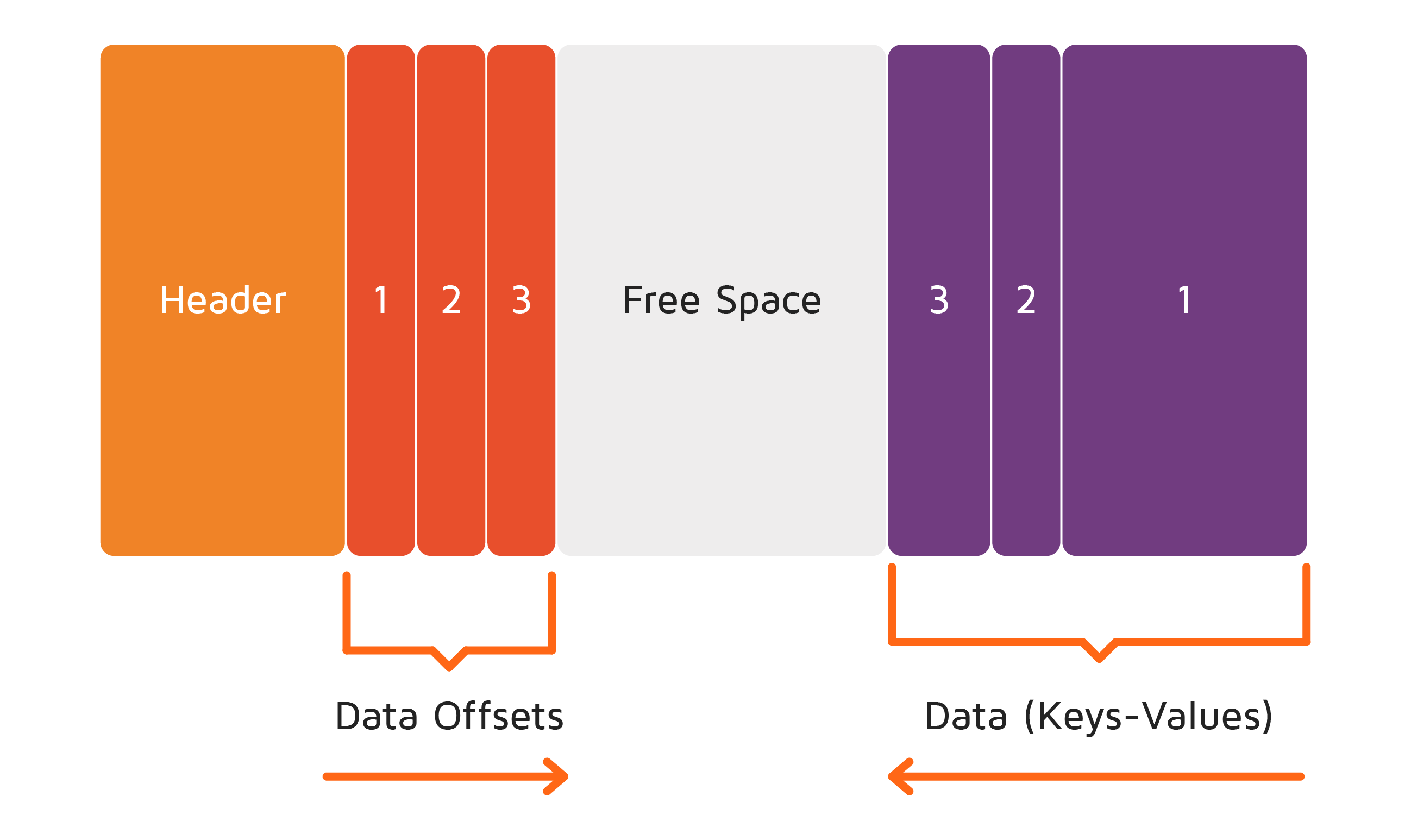
页面具有一个头部,其存储内部使用所需的元信息。所有键-值条目总是从右到左添加。在上图中,页面中存储了三个条目(分别为1、2和3)。这些条目可能具有不同的大小。
页面内条目位置的偏移量(或引用)从左到右存储,并且始终为固定大小。偏移量用于在页面中查找键-值条目的指针。
中间的空间是可用空间,每当将更多数据推入集群时,该空间就会被填充。
接下来,假设随着时间的推移,条目2被删除,这导致页面中的非连续可用空间:

这就是碎片化页面的样子。
但是,当需要页面的整个可用空间或达到某个碎片阈值时,压缩过程会对页面进行碎片整理,使其变为上面第一张图片中所示的状态,其中该连续空间是连续的。此过程是自动的,不需要用户干预。
# 1.3.持久化
Ignite提供了许多功能,可以将数据持久化磁盘上,同时还保持一致性。可以在不丢失数据的前提下重启集群,可以应对故障,并在内存不足时为数据提供存储。启用原生持久化后,Ignite会将所有数据保存在磁盘上,并将尽可能多的数据加载到内存中进行处理。更多信息请参考Ignite持久化章节的内容。
# 2.配置数据区
# 2.1.概述
Ignite使用数据区的概念来控制可用于缓存的内存数量,数据区是缓存数据存储在内存中的逻辑可扩展区域。可以控制数据区的初始值及其可以占用的最大值,除了大小之外,数据区还控制缓存的持久化配置。
Ignite有一个默认的数据区最多可占用该节点20%的内存,并且创建的所有缓存均位于该数据区中,但是也可以添加任意多个数据区,创建多个数据区的原因有:
- 可以通过不同数据区分别配置缓存对应的可用内存量;
- 持久化参数是按数据区配置的。如果要同时具有纯内存缓存和持久化缓存,则需要配置两个(或多个)具有不同持久化参数的数据区:一个用于纯内存缓存,一个用于持久化缓存;
- 部分内存参数,比如退出策略,是按照数据区进行配置的。
下面的章节会演示如何更改默认数据区的参数或配置多个数据区。
# 2.2.配置默认数据区
新的缓存默认会添加到默认的数据区中,可以在数据区配置中更改默认数据区的属性:
# 2.3.添加自定义数据区
除了默认的数据区,还可以使用自定义配置定义更多个数据区,在下面的示例中,配置了一个数据区占用40MB空间然后使用了Random-2-LRU退出策略,注意在进一步的缓存配置中,在该数据区中创建了一个缓存。
# 2.4.缓存预热策略
集群启动组网成功之后,Ignite本身并不需要对内存进行预热,应用就可以在其上执行计算和查询。但是对于需要低延迟的系统,还是希望在查询数据之前先将数据加载到内存中的。
当前,Ignite的预热策略是从索引开始,将数据加载到所有或者指定的数据区,直到用完可用空间为止。可以为所有的数据区进行配置(默认),也可以单独为某个数据区进行配置。
要预热所有数据区,需将配置参数LoadAllWarmUpStrategy传递给DataStorageConfiguration#setDefaultWarmUpConfiguration,如下所示:
要预热某个数据区,需将配置参数LoadAllWarmUpStrategy传递给DataStorageConfiguration#setWarmUpConfiguration,如下所示:
要停止预热所有数据区,请将配置参数NoOpWarmUpStrategy传递给DataStorageConfiguration#setDefaultWarmUpConfiguration,如下所示:
要停止预热某个数据区,请将配置参数NoOpWarmUpStrategy传递给DataStorageConfiguration#setWarmUpConfiguration,如下所示:
还可以使用control.sh和JMX停止缓存预热过程。
要使用control.sh停止预热:
要使用JMX停止预热,可使用下面的方法:
org.apache.ignite.mxbean.WarmUpMXBean#stopWarmUp
# 3.退出策略
如果关闭了Ignite原生持久化,Ignite会在堆外内存中存储所有的缓存条目,当有新的数据注入,会进行页面的分配。如果达到了内存的限制,Ignite无法分配页面时,部分数据就必须从内存中删除以避免内存溢出,这个过程叫做退出,退出保证系统不会内存溢出,但是代价是内存数据丢失以及如果需要数据还需要重新加载。
退出策略用于下面的场景:
如果开启了原生持久化,当Ignite无法分配新的页面时,会有一个叫做页面替换的简单过程来进行堆外内存的释放,不同点在于数据并没有丢失(因为其存储于持久化存储),因此不用担心数据丢失,而要关注效率。关于页面替换策略的更多信息,可以参见替换策略章节的内容。
# 3.1.堆外内存退出
堆外内存退出的实现方式如下:
当内存使用超过预设限制时,Ignite使用预配置的算法之一来选择最适合退出的内存页面。然后将页面中的每个缓存条目从页面中删除,但是会保留被事务锁定的条目。因此,整个页面或大块页面都是空的,可以再次使用。
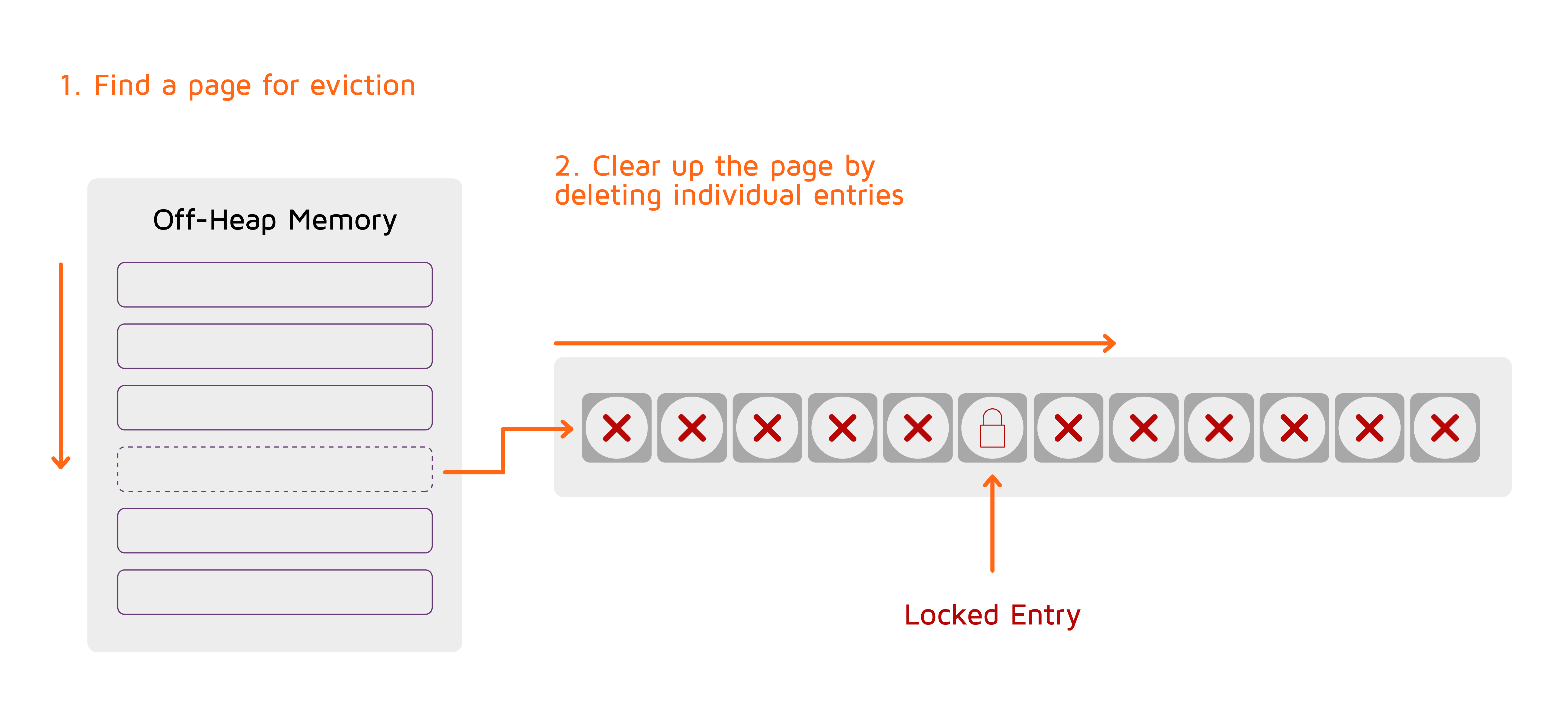
堆外内存的退出默认是关闭的,这意味着内存使用量会一直增长直到达到限值。如果要开启退出,需要在数据区配置中指定页面退出模式。注意堆外内存退出是数据区级的,如果没使用数据区,那么需要给默认的数据区显式地增加参数来配置退出。
默认情况下,当某个数据区的内存消耗量达到90%时,退出就开始了,如果希望更早或者更晚地发起退出,可以配置DataRegionConfiguration.setEvictionThreshold(...)参数。
Ignite支持两种页面选择算法:
- Random-LRU
- Random-2-LRU
两者的不同下面会说明。
# 3.1.1.Random-LRU
要启用Random-LRU退出算法,配置方式如下所示;
Random-LRU算法工作方式如下:
- 当一个数据区配置了内存策略时,就会分配一个堆外数组,它会跟踪每个数据页面的
最后使用时间戳; - 当数据页面被访问时,跟踪数组的时间戳就会被更新;
- 当到了退出页面时间时,算法会从跟踪数组中随机地选择5个索引,然后退出最近的时间戳对应的页面,如果部分索引指向非数据页面(索引或者系统页面),算法会选择其它的页面。
# 3.1.2.Random-2-LRU
Random-2-LRU退出算法是Random-LRU算法的抗扫描版,配置方式如下所示:
在Random-2-LRU算法中,每个数据页面会存储两个最近访问时间戳,退出时,算法会随机地从跟踪数组中选择5个索引值,然后两个最近时间戳中的最小值会被用来和另外4个候选页面中的最小值进行比较。
Random-2-LRU比Random-LRU要好,因为它解决了昙花一现的问题,即一个页面很少被访问,但是偶然地被访问了一次,然后就会被退出策略保护很长时间。
# 3.2.堆内缓存退出
关于如何为堆内缓存配置退出策略的介绍,请参见堆内缓存配置退出策略章节的内容。
# 4.替换策略
当开启原生持久化并且Ignite磁盘上存储的数据量大于为数据区分配的堆外内存量时,应将另一个页面从堆外内存移出到磁盘,才能将一个页面从磁盘预加载到全满的堆外内存。这个过程称为页面替换。
当原生持久化关闭时,会使用退出代替页面替换,具体请参见退出策略章节。
页面替换的实现如下:
当Ignite需要一个页面时,它会尝试在堆外内存中找到这个页面。如果该页面当前不在堆外内存中,则会从磁盘预加载该页面。这时如果堆外内存已满,则应选择另一个页面进行替换(存储到磁盘并退出)。
Ignite支持三种算法来查找要替换的页面:
- Random-LRU算法;
- Segmented-LRU算法;
- CLOCK算法。
可以通过DataRegionConfiguration的pageReplacementMode属性配置页面替换算法,默认使用CLOCK算法。
算法的选择取决于工作负载,对于大多数场景来说,CLOCK算法(默认)是一个好的选项,但是某些场景其他算法可能更好。
# 4.1.Random-LRU算法
每次访问页面时,都会更新其时间戳。当发生缺页需要替换一些页面时,算法从页面内存中随机选择5个页面,退出时间戳最新的页面。
该算法的维护成本为零,但在寻找下一个替换页面方面并不是很有效。建议在不需要页面替换(使用足够大的数据区以存储所有数据量时)或很少发生页面替换的环境中使用该算法。
# 4.2.Segmented-LRU算法
Segmented-LRU算法是最近最少使用 (LRU) 算法的抗扫描变体。Segmented-LRU页面列表分为两个部分:试用段和保护段。每个段中的页面按从最少到最近访问的顺序排列。新页面被添加到试用段的最近访问的末尾(尾部)。现有页面从它们当前驻留的任何地方删除,并添加到保护段的最近访问端。因此保护段中的页面至少被访问过两次。保护段是有限的,因此从试用段到保护段的页面迁移可能会强制将保护段中的LRU页迁移到试用段的最近使用端。这给了页面在被替换之前被访问的另一个机会。从试用段的最近最少访问的端(头)轮询要替换的页面。
该算法需要额外的内存来存储页面列表,该列表在每次访问页面时也需要更新。同时该算法具有接近最优的页面替换选择策略。因此,对于没有页面替换的环境(与Random-LRU和CLOCK相比),性能可能会略有下降,但是对于具有高页面替换率和大量一次性扫描的环境,Segmented-LRU可以胜过Random-LRU和CLOCK。
# 4.3.CLOCK算法
CLOCK算法在内存中维护一个循环页面列表,有一个指针指向列表中最后检查的页面。当发生缺页并且空间不足时,在指针的位置检查页面的命中标志。如果命中标志为0,则将新页面放在指针指向的页面的位置,并且指针再前进一个位置。否则清除命中标志,然后时钟指针增加并且重复该过程直到页面被替换。
该算法在Random-LRU和Segmented-LRU之间具有接近于零的维护成本和替换策略效率。
18624049226
