# 数据流处理
# 1.概述
Ignite提供了一个数据流API,可用于将大量数据注入Ignite集群,流化的目的是高效地快速加载数据。数据流化之后会自组织,并以并行和分区感知的方式在节点间分布。
数据流API设计为可扩展的,并为流式注入Ignite的数据提供至少一次传递语义,这意味着每个条目至少处理一次。
# 2.使用
数据流处理器与某个缓存关联,并提供用于将数据注入缓存的接口。
在典型场景中,拿到数据流处理器之后,就可以使用其中某个方法将数据流式注入缓存中,剩下的就交给Ignite负责了。
拿到某个缓存的数据流处理器的方法如下:
流处理器可以以多线程的方式接收数据。
流式处理的最佳实践是数据预加载。
# 3.限制
数据流处理器无法保证:
- 默认除非全部成功完成,否则无法保证数据一致性;
- 数据立即加载,数据会被持有一段时间;
- 数据的顺序,数据加载到缓存的顺序可能与注入流处理器的顺序不同;
- 默认是用来处理外部存储的数据。
如果allowOverwite属性是false(默认),那么要考虑:
- 流式处理的数据中不应有主键重复的数据;
- 数据流取消或者数据流节点故障可能导致数据不一致;
- 如果加载到持久化缓存中,同时创建快照可能包含不一致的数据,并且可能无法完全恢复。
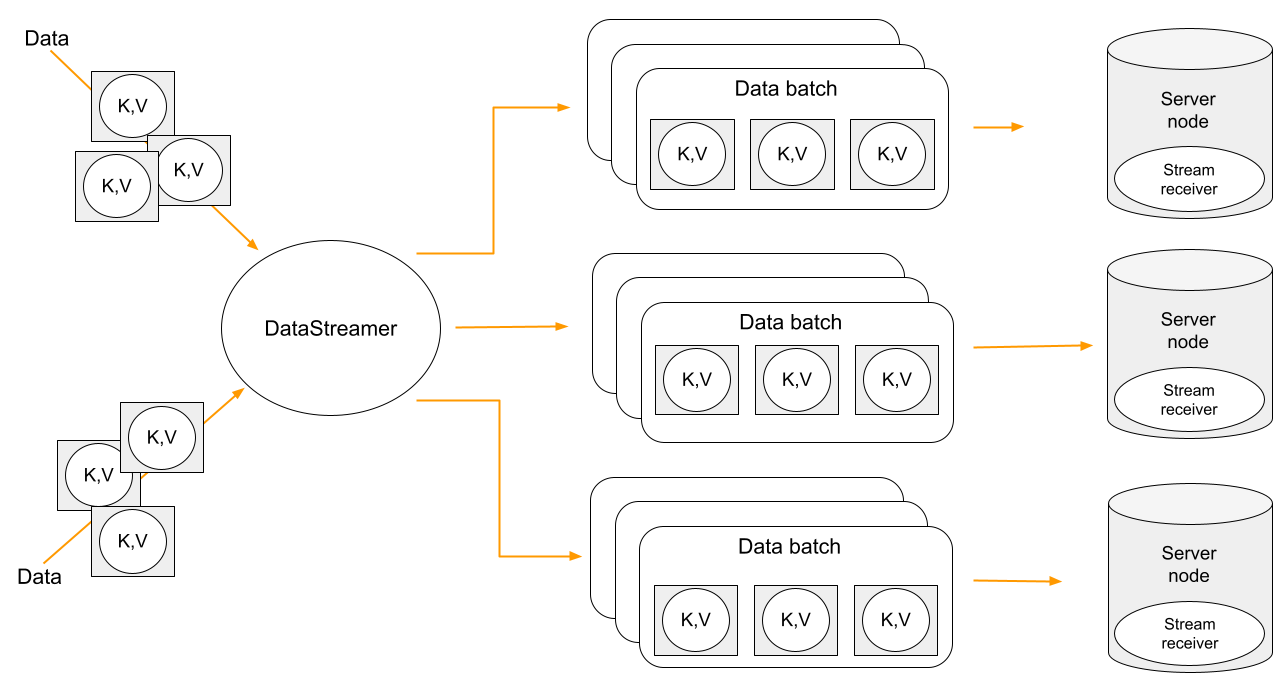
Ignite数据流处理器的关键概念是数据流接收器和allowOverwite参数。
# 4.数据流接收器
Ignite的DataStreamer是一个编排器,它本身不写数据,该动作由StreamerReceiver执行。默认的接收器是为最快的负载和更少的网络请求而设计的,有了这个接收器,流处理器才会专注于主备数据的并行传输。
可以配置自己的接收器,具体参见流转换器和流访问器。在流接收器中实现的逻辑是在存储数据的节点上执行的。
将接收器更改为非默认值会更改数据分发算法。对于非默认接收器,流处理器仅向主节点接收器发送数据批次,并且主节点需要另一个请求来发送备份写入。
提示
流接收器不会自动将数据写入缓存,因此需要显式调用put方法。
# 5.覆写数据
默认是不会覆写现有数据的。可以通过将数据流的allowOverwrite属性设置为true来更改该行为。由于默认接收器不会覆盖数据,因此会自动选择其他的接收器。任何非默认接收器都被视为覆写的,即相当于allowOverwrite属性为true,不过自定义的接收器可以使用putIfAbsent方法来解决这个问题。
提示
当allowOverwrite为false(默认),更新是不会传播到外部存储(如果开启)的。
# 5.1.StreamTransformer
StreamTransformer是StreamReceiver的简单实现,用于更新流中的数据。数据流转换器利用了并置的特性,并在将要存储数据的节点上更新数据。
在下面的示例中,使用StreamTransformer为文本流中找到的每个不同单词增加一个计数:
# 5.2.StreamVisitor
StreamVisitor也是StreamReceiver的一个实现,它会访问流中的每个键-值对。
在下面的示例中,有两个缓存:marketData和instruments,收到market数据的瞬间就会将它们放入marketData缓存的流处理器,映射到某market数据的集群节点上的marketData的流处理器的StreamVisitor就会被调用,在分别收到market数据后就会用最新的市场价格更新instrument缓存。
注意,根本不会更新marketData缓存,它一直是空的,只是直接在数据将要存储的集群节点上简单利用了market数据的并置处理能力。
# 5.配置数据流处理器线程池大小
数据流处理器线程池专用于处理来自数据流处理器的批次数据。
默认池大小为max(8, CPU总核数),使用IgniteConfiguration.setDataStreamerThreadPoolSize(…)可以改变线程池的大小。
18624049226
