# 介绍
# 1.概述
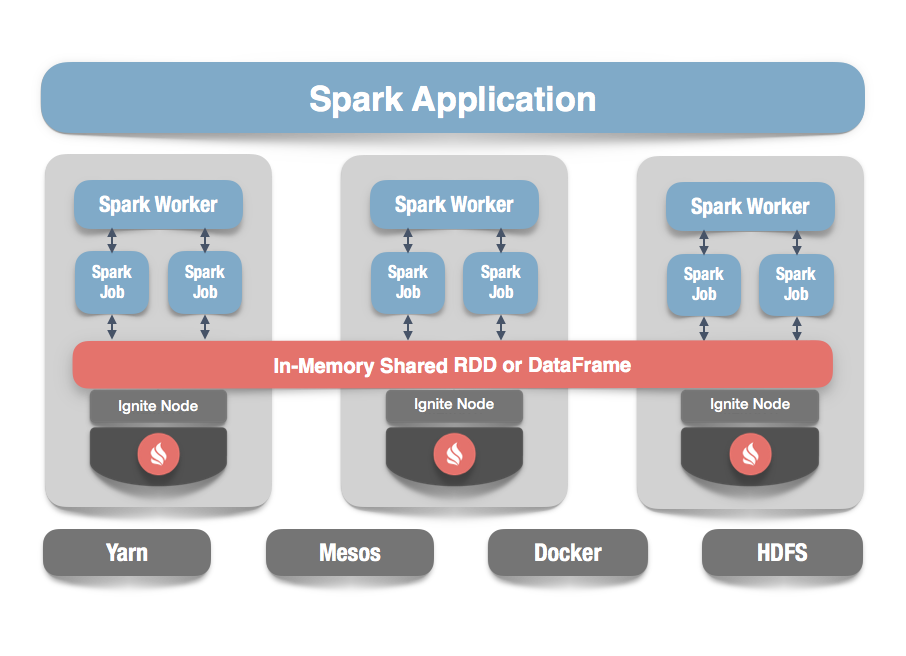
Ignite可以无缝地与Hadoop和Spark集成,其中Ignite与Hadoop的集成可以将IGFS(Ignite文件系统)作为存储于HDFS中的数据的主要缓存层,Ignite与Spark的集成可以使用一个Spark RDD和DataFrames的实现在内存中跨多个Spark作业共享状态。
Ignite与Spark
Ignite作为一个分布式的内存数据库和缓存平台,对于Spark用户可以实现如下的功能:
- 获得真正的可扩展的内存级性能,避免数据源和Spark工作节点和应用之间的数据移动;
- 提升DataFrame和SQL的性能;
- 在Spark作业之间更容易地共享状态和数据。
内存文件系统
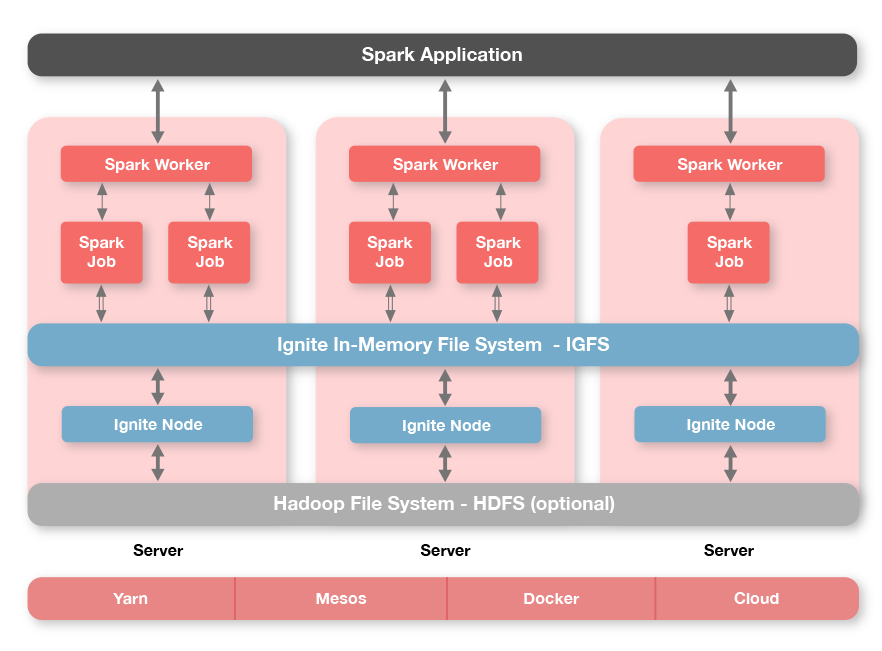
Ignite的一个独特功能是它有一个分布式的内存文件系统,叫做Ignite文件系统(IGFS),IGFS的功能类似于Hadoop的HDFS,但是仅仅保存在内存中。事实上,除了它本身的API,IGFS还实现了Hadoop文件系统API,因此可以将其轻易地嵌入Hadoop或者Spark应用。
内存MapReduce
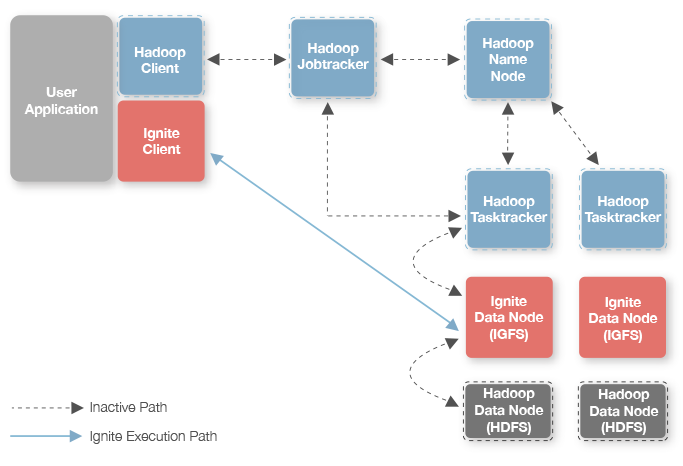
Ignite的内存MapReduce可以高效地对存储于任何Hadoop文件系统中的数据进行并行处理。当进行低延迟、HPC模式的分布式处理时,它消除了标准Hadoop架构中与作业跟踪器和任务跟踪器有关的开销。
Hadoop加速器
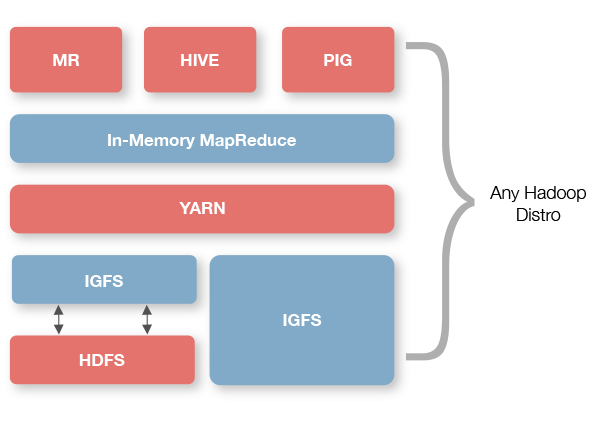
Ignite的Hadoop加速器提供了一组在内存中进行Hadoop作业执行以及文件系统操作的组件。它可以用于组合Ignite文件系统以及内存MapReduce,也可以轻易地将其嵌入任何Hadoop发行版。
内存文件系统 →