# Ignite与Spark
# 1.Ignite与Spark
Ignite作为一个分布式的内存数据库和缓存平台,对于Spark用户可以实现如下的功能:
- 获得真正的可扩展的内存级性能,避免数据源和Spark工作节点和应用之间的数据移动;
- 提升DataFrame和SQL的性能;
- 在Spark作业之间更容易地共享状态和数据。
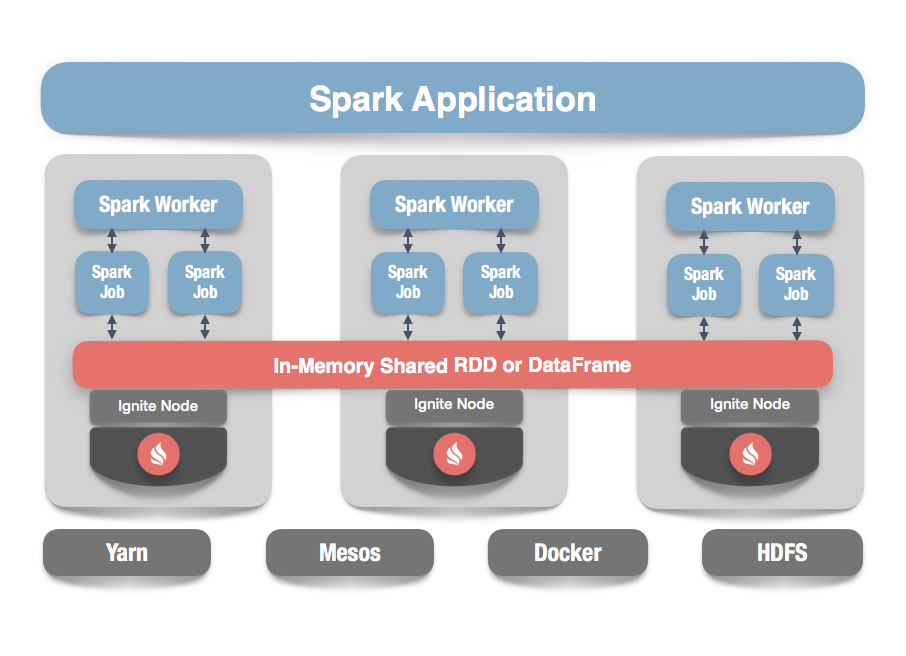
# 1.1.IgniteRDD
Ignite提供了一个Spark RDD抽象的实现,它可以容易地在内存中跨越多个Spark作业共享状态,在跨越不同Spark作业、工作节点或者应用时,IgniteRDD为内存中的相同数据提供了一个共享的、可变的视图,而原生的SparkRDD无法在Spark作业或者应用之间进行共享。
IgniteRDD实现的方式是作为一个分布式的Ignite缓存(或者表)的视图,它可以作为一个节点部署在Spark执行进程内部,或者Spark 工作节点上或者它自己的集群中。这意味着根据选择的不同的部署模型,共享状态可能只存在于一个Spark应用的生命周期内(嵌入式模式),或者可能存在于Spark应用外部(独立模式),这时状态可以在多个Spark应用之间共享。
虽然SparkSQL支持丰富的SQL语法,但是它没有实现索引。从结果上来说,即使在普通的较小的数据集上,Spark查询也可能花费几分钟的时间,因为需要进行全表扫描。如果使用Ignite,Spark用户可以配置主索引和二级索引,这样可以带来上千倍的性能提升。
# 1.2.Ignite DataFrames
Spark DataFrame API引入了描述数据的模式的概念,这样Ignite就可以管理模式并且将数据组织成表格的形式。简单来说,DataFrame就是一个将数据组织成命名列的分布式集合,它在概念上等价于关系数据库中的表,Spark会利用催化剂查询优化器的优势,生成一个比RDD更高效的查询执行计划,而RDD只是一个集群范围的、分区化的元素的集合。
Ignite扩展了DataFrame,简化了开发,并且如果Ignite用作Spark的内存存储,还会改进数据访问的时间,好处包括:
- 通过在Ignite中读写DataFrame,可以在Spark作业间共享数据和状态;
- 使用Ignite的SQL引擎,包括高级索引以及避免Ignite和Spark之间的网络数据移动,可以优化Spark的查询执行计划,从而实现更快的SparkSQL查询。
# 2.IgniteContext和IgniteRDD
# 2.1.IgniteContext
IgniteContext是Spark和Ignite集成的主要入口点。要创建一个Ignite上下文的实例,必须提供一个SparkContext的实例以及创建IgniteConfiguration的闭包(配置工厂)。Ignite上下文会确保Ignite服务端或者客户端节点存在于所有参与的作业实例中。或者,一个XML配置文件的路径也可以传入IgniteContext构造器,它会用于配置启动的节点。
当创建一个IgniteContext实例时,一个可选的booleanclient参数(默认为true)可以传入上下文构造器,这个通常用于一个共享部署安装,当client设为false时,上下文会操作于嵌入式模式然后在上下文创建期间在所有的工作节点上启动服务端节点。可以参照安装与部署章节了解有关部署配置的信息。
嵌入式模式已被弃用
嵌入式模式意味着需要在Spark执行器中启动Ignite服务端节点,这可能导致意外的再平衡甚至数据丢失,因此该模式目前已被弃用并且最终会被废弃。可以考虑启动一个单独的Ignite集群然后使用独立模式来避免数据的一致性和性能问题。
一旦创建了IgniteContext,IgniteRDD的实例可以通过fromCache方法获得,当RDD创建之后请求的缓存在Ignite集群中是否存在不是必要的,如果指定名字的缓存不存在,会用提供的配置或者模板配置创建它。
比如,下面的代码会用默认的Ignite配置创建一个Ignite上下文:
val igniteContext = new IgniteContext(sparkContext,
() => new IgniteConfiguration())
下面的代码会从example-shared-rdd.xml的配置创建一个Ignite上下文:
val igniteContext = new IgniteContext(sparkContext,
"examples/config/spark/example-shared-rdd.xml")
# 2.2.IgniteRDD
IgniteRDD是一个SparkRDD抽象的实现,它表示Ignite的缓存的活动视图。IgniteRDD不是一成不变的,Ignite缓存的所有改变(不论是它被另一个RDD或者缓存的外部改变触发)对于RDD用户都会立即可见。
IgniteRDD利用Ignite缓存的分区性质然后向Spark执行器提供分区信息。IgniteRDD中分区的数量会等于底层Ignite缓存的分区数量,IgniteRDD还通过getPrefferredLocations方法向Spark提供了关联信息使RDD计算可以使用本地的数据。
从Ignite中读取数据
因为IgniteRDD是Ignite缓存的一个活动视图,因此不需要从Ignite向Spark应用显式地加载数据,在IgniteRDD实例创建之后所有的RDD方法都会立即可用。
比如,假定一个名为partitioned的Ignite缓存包含字符值,下面的代码会查找包含单词Ignite的所有值:
val cache = igniteContext.fromCache("partitioned")
val result = cache.filter(_._2.contains("Ignite")).collect()
向Ignite保存数据
因为Ignite缓存操作于键-值对,因此向Ignite缓存保存数据的最明确的方法是使用Spark数组RDD以及savePairs方法,如果可能,这个方法会利用RDD分区的优势然后以并行的方式将数据存入缓存。
也可能使用saveValues方法将只有值的RDD存入Ignite缓存,这时,IgniteRDD会为每个要存入缓存的值生成一个唯一的本地关联键。
比如,下面的代码会使用10个并行存储操作保存从1到10000的整型值对到一个名为partitioned的缓存中:
val cacheRdd = igniteContext.fromCache("partitioned")
cacheRdd.savePairs(sparkContext.parallelize(1 to 10000, 10).map(i => (i, i)))
在Ignite缓存中执行SQL查询
当Ignite缓存配置为启用索引子系统,就可以使用objectSql和sql方法在缓存中执行SQL查询。可以参照缓存查询章节来了解有关Ignite SQL查询的更多信息。
比如,假定名为partitioned的缓存配置了索引整型对,下面的代码会获得 (10, 100)范围内的所有整型值:
val cacheRdd = igniteContext.fromCache("partitioned")
val result = cacheRdd.sql(
"select _val from Integer where val > ? and val < ?", 10, 100)
# 2.3.示例
GitHub上有一些示例,演示了IgniteRDD如何使用:
# 3.Ignite DataFrame
# 3.1.概述
Spark DataFrame API引入了描述数据的模式的概念,这样Ignite就可以管理模式并且将数据组织成表格的形式。简单来说,DataFrame就是一个将数据组织成命名列的分布式集合,它在概念上等价于关系数据库中的表,Spark会利用催化剂查询优化器的优势,生成一个比RDD更高效的查询执行计划,而RDD只是一个集群范围的、分区化的元素的集合。
Ignite扩展了DataFrame,简化了开发,并且如果Ignite用作Spark的内存存储,还会改进数据访问的时间,好处包括:
- 通过在Ignite中读写DataFrame,可以在Spark作业间共享数据和状态;
- 使用Ignite的SQL引擎,包括高级索引以及避免Ignite和Spark之间的网络数据移动,可以优化Spark的查询执行计划,从而实现更快的SparkSQL查询。
SparkSQL在Ignite中的执行
目前,大多数的分组、联接或者排序操作都是在Spark端实现的,在未来的版本中,这些操作会在Ignite端进行优化和处理。
# 3.2.集成
IgniteRelationProvider是SparkRelationProvider和CreatableRelationProvider接口的一个实现,IgniteRelationProvider可以通过SparkSQL接口,直接访问Ignite表。数据通过IgniteSQLRelation进行加载和交换,其在Ignite端执行过滤操作。目前,分组、联接或者排序操作,是在Spark端进行的,在即将发布的版本中,这些操作会在Ignite端进行优化和处理。IgniteSQLRelation利用了Ignite架构的分区特性,并且为Spark提供了分区信息。
# 3.3.Spark会话
如果要使用Spark DataFrame API,需要为Spark编程创建一个入口点,这是通过SparkSession对象实现的,大体如下:
Java:
// Creating spark session.
SparkSession spark = SparkSession.builder()
.appName("Example Program")
.master("local")
.config("spark.executor.instances", "2")
.getOrCreate();
Scala:
// Creating spark session.
implicit val spark = SparkSession.builder()
.appName("Example Program")
.master("local")
.config("spark.executor.instances", "2")
.getOrCreate()
# 3.4.读取DataFrame
要从Ignite中读取数据,需要指定格式以及Ignite配置文件的路径,假定如下名为person的Ignite表已经创建和部署:
CREATE TABLE person (
id LONG,
name VARCHAR,
city_id LONG,
PRIMARY KEY (id, city_id)
) WITH "backups=1, affinityKey=city_id”;
下面的Spark代码可以从person表检索到名字为Mary Major的所有行:
Java:
SparkSession spark = _
String cfgPath = “path/to/config/file”;
Dataset<Row> df = spark.read()
.format(IgniteDataFrameSettings.FORMAT_IGNITE()) //Data source
.option(IgniteDataFrameSettings.OPTION_TABLE(), "person") //Table to read.
.option(IgniteDataFrameSettings.OPTION_CONFIG_FILE(), CONFIG) //Ignite config.
.load();
df.createOrReplaceTempView("person");
Dataset<Row> igniteDF = spark.sql(
"SELECT * FROM person WHERE name = 'Mary Major'");
Scala:
val spark: SparkSession = …
val cfgPath: String = “path/to/config/file”
val df = spark.read
.format(FORMAT_IGNITE) // Data source type.
.option(OPTION_TABLE, "person") // Table to read.
.option(OPTION_CONFIG_FILE, cfgPath) // Ignite config.
.load()
df.createOrReplaceTempView("person")
val igniteDF = spark.sql("SELECT * FROM person WHERE name = 'Mary Major'")
# 3.5.保存DataFrames
实现细节
从内部来说,所有的插入操作都是通过IgniteDataStreamer实现的,内部的流处理器是可以通过参数进行控制的。
Ignite可以作为Spark创建和维护的DataFrame的存储层,下面的保存模式,决定了Ignite中DataFrame的处理方式:
Append:DataFrame会附加到一个已有的表,如果要更新DataFrame中的已有条目,可以配置OPTION_STREAMER_ALLOW_OVERWRITE=true;Overwrite:会执行如下的步骤:- 如果Ignite中的表已经存在,那么会被删除;
- 会使用DataFrame的模式以及参数创建新的表;
- DataFrame的内容会被插入新的表。
ErrorIfExists:(默认),如果表已经存在会抛出异常,表不存在时:- 会使用DataFrame的模式以及参数创建新的表;
- DataFrame的内容会被插入新的表。
Ignore:如果表已经存在会被忽略,表不存在时:- 会使用DataFrame的模式以及参数创建新的表;
- DataFrame的内容会被插入新的表。
保存模式可以通过mode(SaveMode mode)方法指定,具体可以参照Spark的文档,下面是该方法的一个示例:
Java:
SparkSession spark = _
String cfgPath = “path/to/config/file”
Dataset<Row> jsonDataFrame = spark.read().json(“path/to/file.json”);
jsonDataFrame.write()
.format(IgniteDataFrameSettings.FORMAT_IGNITE())
.mode(SaveMode.Append) // SaveMode.
//... other options
.save();
Scala:
val spark: SparkSession = …
val cfgPath: String = “path/to/config/file”
val jsonDataFrame = spark.read.json(“path/to/file.json”)
jsonDataFrame.write
.format(FORMAT_IGNITE)
.mode(SaveMode.Append) // SaveMode.
//... other options
.save()
如果是通过保存DataFrame的途径创建的新表,那么必须定义下面的选项:
OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS:Ignite表的主键,该选项的内容为代表主键的、逗号分隔的字段/列列表;OPTION_CREATE_TABLE_PARAMETERS:用于Ignite表创建的附加参数,该参数为Ignite的CREATE TABLE命令支持的参数。
下面的示例展示了如何将JSON文件的内容写入Ignite:
Java:
SparkSession spark = _
String cfgPath = “path/to/config/file”
Dataset<Row> jsonDataFrame = spark.read().json(“path/to/file.json”);
jsonDataFrame.write()
.format(IgniteDataFrameSettings.FORMAT_IGNITE())
.option(IgniteDataFrameSettings.OPTION_CONFIG_FILE(), TEST_CONFIG_FILE)
.option(IgniteDataFrameSettings.OPTION_TABLE(), "json_table")
.option(IgniteDataFrameSettings.OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS(), "id")
.option(IgniteDataFrameSettings.OPTION_CREATE_TABLE_PARAMETERS(), "template=replicated")
.save();
Scala:
val spark: SparkSession = …
val cfgPath: String = “path/to/config/file”
val jsonDataFrame = spark.read.json(“path/to/file.json”)
jsonDataFrame.write
.format(FORMAT_IGNITE)
.option(OPTION_CONFIG_FILE, TEST_CONFIG_FILE)
.option(OPTION_TABLE, "json_table")
.option(OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS, "id")
.option(OPTION_CREATE_TABLE_PARAMETERS, "template=replicated")
.save()
# 3.6.IgniteSparkSession和IgniteExternalCatalog
针对已知数据源(比如表和视图)的元信息的读取和存储,Spark引入了叫做catalog的实体,关于这个目录,Ignite提供了自己的实现,叫做IgniteExternalCatalog。
IgniteExternalCatalog可以读取部署在Ignite集群中的所有SQL表的元数据信息,如果要构造IgniteSparkSession对象,IgniteExternalCatalog也是必要的。
IgniteSparkSession是正常SparkSession的一个扩展,它存储了IgniteContext,并且在Spark对象中注入了IgniteExternalCatalog。
IgniteSparkSession可以用IgniteSparkSession.builder()进行创建,比如,如果下面的两张表已经创建好:
CREATE TABLE city (
id LONG PRIMARY KEY,
name VARCHAR
) WITH "template=replicated";
CREATE TABLE person (
id LONG,
name VARCHAR,
city_id LONG,
PRIMARY KEY (id, city_id)
) WITH "backups=1, affinityKey=city_id";
然后执行下面的代码,列出表的元数据信息:
Java:
// Using SparkBuilder provided by Ignite.
IgniteSparkSession igniteSession = IgniteSparkSession.builder()
.appName("Spark Ignite catalog example")
.master("local")
.config("spark.executor.instances", "2")
//Only additional option to refer to Ignite cluster.
.igniteConfig("/path/to/ignite/config.xml")
.getOrCreate();
// This will print out info about all SQL tables existed in Ignite.
igniteSession.catalog().listTables().show();
// This will print out schema of PERSON table.
igniteSession.catalog().listColumns("person").show();
// This will print out schema of CITY table.
igniteSession.catalog().listColumns("city").show();
Scala:
// Using SparkBuilder provided by Ignite.
val igniteSession = IgniteSparkSession.builder()
.appName("Spark Ignite catalog example")
.master("local")
.config("spark.executor.instances", "2")
//Only additional option to refer to Ignite cluster.
.igniteConfig("/path/to/ignite/config.xml")
.getOrCreate()
// This will print out info about all SQL tables existed in Ignite.
igniteSession.catalog.listTables().show()
// This will print out schema of PERSON table.
igniteSession.catalog.listColumns("person").show()
// This will print out schema of CITY table.
igniteSession.catalog.listColumns("city").show()
代码输出大体如下:
+------+--------+-----------+---------+-----------+
| name|database|description|tableType|isTemporary|
+------+--------+-----------+---------+-----------+
| CITY| | null| EXTERNAL| false|
|PERSON| | null| EXTERNAL| false|
+------+--------+-----------+---------+-----------+
PERSON table description:
+-------+-----------+--------+--------+-----------+--------+
| name|description|dataType|nullable|isPartition|isBucket|
+-------+-----------+--------+--------+-----------+--------+
| NAME| null| string| true| false| false|
| ID| null| bigint| false| true| false|
|CITY_ID| null| bigint| false| true| false|
+-------+-----------+--------+--------+-----------+--------+
CITY table description:
+----+-----------+--------+--------+-----------+--------+
|name|description|dataType|nullable|isPartition|isBucket|
+----+-----------+--------+--------+-----------+--------+
|NAME| null| string| true| false| false|
| ID| null| bigint| false| true| false|
+----+-----------+--------+--------+-----------+--------+
# 3.7.Ignite DataFrame选项
| 参数 | 描述 |
|---|---|
FORMAT_IGNITE | Ignite数据源的名字 |
OPTION_CONFIG_FILE | 配置文件的路径 |
OPTION_TABLE | 表名 |
OPTION_CREATE_TABLE_PARAMETERS | 新创建表的额外参数,该选项的值用作CREATE TABLE语句的WITH部分。 |
OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS | 逗号分隔的主键字段的列表。 |
OPTION_STREAMER_ALLOW_OVERWRITE | 如果为true,那么已有的行会被DataFrame的内容覆写,如果为false并且表中对应的主键已经存在,那么后续该行会被忽略。 |
OPTION_STREAMER_FLUSH_FREQUENCY | 自动刷新频率,这是流处理器尝试提交所有附加数据到远程节点的时间间隔。 |
OPTION_STREAMER_PER_NODE_BUFFER_SIZE | 每节点的缓冲区大小。每个节点键-值对缓冲区的大小。 |
OPTION_STREAMER_PER_NODE_PARALLEL_OPERATIONS | 每节点的缓冲区大小。每个节点进行并行流处理的最大数量。 |
# 3.8.示例
GitHub上有一些用于演示如何在Ignite中使用Spark DataFrame的示例:
- [DataFrame](This is the time after which the streamer will make an attempt to submit all data added so far to remote nodes See also)
- 保存DataFrame
- Catalog
# 4.安装和部署
# 4.1.共享部署
共享部署意味着Ignite节点的运行独立于Spark应用然后即使Spark作业结束之后也仍然保存状态。类似于Spark,将Ignite部署入集群有两种方式:
独立部署
在独立部署模式,Ignite节点应该与Spark工作节点部署在一起。Ignite安装的介绍可以参照入门章节,在所有的工作节点上安装Ignite之后,通过ignite.sh脚本在每个配置好的Spark workder上启动一个节点。
默认将Ignite库文件加入Spark类路径
Spark应用部署模型可以在应用启动期间动态地发布jar,但是这个模式有一些缺点:
- Spark动态类加载器没有实现
getResource方法,因此无法访问位于jar文件内部的资源; - Java的logger使用应用级类加载器(而不是上下文级类加载器)来加载日志处理器,这会导致在Ignite中使用Java logging时会抛出
ClassNotFoundException;
有一个方法来对每一个启动的应用修改默认的Spark类路径(这个可以在每个Spark集群的机器上实现,包括主节点,工作节点以及驱动节点)。
- 定位到
$SPARK_HOME/conf/spark-env.sh文件,如果该文件不存在,用$SPARK_HOME/conf/spark-env.sh.template这个模板创建它; - 将下面的行加入
spark-env.sh文件的末尾(如果没有全局定义IGNITE_HOME,则需要将设置IGNITE_HOME的行的注释去掉)。
# Optionally set IGNITE_HOME here.
# IGNITE_HOME=/path/to/ignite
IGNITE_LIBS="${IGNITE_HOME}/libs/*"
for file in ${IGNITE_HOME}/libs/*
do
if [ -d ${file} ] && [ "${file}" != "${IGNITE_HOME}"/libs/optional ]; then
IGNITE_LIBS=${IGNITE_LIBS}:${file}/*
fi
done
export SPARK_CLASSPATH=$IGNITE_LIBS
从$IGNITE_HOME/libs/optional文件夹中复制必要的库文件,比如ignite-log4j,到$IGNITE_HOME/libs文件夹。
也可以验证Spark的类路径是否被运行bin/spark-shell所改变,然后输入一个简单的import语句:
scala> import org.apache.ignite.configuration._
import org.apache.ignite.configuration._
MESOS部署
Ignite可以部署在Mesos集群上,具体细节请参见Mesos部署。
# 4.2.嵌入式部署
嵌入式模式已被弃用
嵌入式模式意味着需要在Spark执行器中启动Ignite服务端节点,这可能导致意外的再平衡甚至数据丢失,因此该模式目前已被弃用并且最终会被废弃。可以考虑启动一个单独的Ignite集群然后使用独立模式来避免数据的一致性和性能问题。
嵌入式部署意味着Ignite节点是在Spark作业进程内部启动的,然后当作业结束时就停止了,这时不需要额外的部署步骤。Ignite代码会通过Spark的部署机制分布到workder机器然后作为IgniteContext初始化的一部分在所有的workder上启动节点。
# 4.3.Maven
Ignite的Spark构件已经上传到Maven中心库,根据使用的Scala版本,引入下面的对应的依赖:
Scala 2.11
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spark</artifactId>
<version>${ignite.version}</version>
</dependency>
Scala 2.10
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spark_2.10</artifactId>
<version>${ignite.version}</version>
</dependency>
# 4.4.SBT
如果在Scala应用中使用SBT作为构建工具,那么可以使用下面的一行命令,将Ignite的Spark构件加入build.sbt:
Scala 2.11
libraryDependencies += "org.apache.ignite" % "ignite-spark" % "ignite.version"
Scala 2.10
libraryDependencies += "org.apache.ignite" % "ignite-spark_2.10" % "ignite.version"
# 4.5.类路径配置
当使用IgniteRDD或者Ignite的DataFrame API时,要注意Spark的执行器以及驱动在它们的类路径中所有必需的Ignite的jar包都是可用的,Spark提供了若干种方式来修改驱动或者执行器进程的类路径。
参数配置
通过使用比如spark.driver.extraClassPath以及spark.executor.extraClassPath这样的参数,可以将Ignite的jar包加入Spark,具体可以看Spark的官方文档。
下面的片段演示了如何使用spark.driver.extraClassPath参数:
spark.executor.extraClassPath /opt/ignite/libs/*:/opt/ignite/libs/optional/ignite-spark/*:/opt/ignite/libs/optional/ignite-log4j/*:/opt/ignite/libs/optional/ignite-yarn/*:/opt/ignite/libs/ignite-spring/*
源代码配置
Spark也提供了在源代码中配置额外的库的API,比如像下面的代码片段:
private val MAVEN_HOME = "/home/user/.m2/repository"
val spark = SparkSession.builder()
.appName("Spark Ignite data sources example")
.master("spark://172.17.0.2:7077")
.getOrCreate()
spark.sparkContext.addJar(MAVEN_HOME + "/org/apache/ignite/ignite-core/2.4.0/ignite-core-2.4.0.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/apache/ignite/ignite-spring/2.4.0/ignite-spring-2.4.0.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/apache/ignite/ignite-log4j/2.4.0/ignite-log4j-2.4.0.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/apache/ignite/ignite-spark/2.4.0/ignite-spark-2.4.0.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/apache/ignite/ignite-indexing/2.4.0/ignite-indexing-2.4.0.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/springframework/spring-beans/4.3.7.RELEASE/spring-beans-4.3.7.RELEASE.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/springframework/spring-core/4.3.7.RELEASE/spring-core-4.3.7.RELEASE.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/springframework/spring-context/4.3.7.RELEASE/spring-context-4.3.7.RELEASE.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/springframework/spring-expression/4.3.7.RELEASE/spring-expression-4.3.7.RELEASE.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/javax/cache/cache-api/1.0.0/cache-api-1.0.0.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/com/h2database/h2/1.4.195/h2-1.4.195.jar")
# 5.用Spark-shell测试Ignite
# 5.1.启动集群
这里会简要地介绍Spark和Ignite集群的启动过程,可以参照Spark文档来了解详细信息。
为了测试,需要一个Spark主节点以及至少一个Spark工作节点,通常Spark主节点和Spark工作节点是不同的机器,但是为了测试可以在启动主节点的同一台机器上启动工作节点。
- 下载和解压Spark二进制包到所有节点的同一个位置(将其设为
SPARK_HOME); - 下载和解压Ignite二进制包到所有节点的同一个位置(将其设为
IGNITE_HOME); - 转到
$SPARK_HOME然后执行如下的命令:
sbin/start-master.sh
这个脚本会输出启动过程的日志文件的路径,可以在日志文件中查看master的URL,它的格式是:spark://master_host:master_port。也可以在日志文件中查看WebUI的URL(通常是http://master_host:8080)。
- 转到每个工作节点的
$SPARK_HOME然后执行如下的命令:
bin/spark-class org.apache.spark.deploy.worker.Worker spark://master_host:master_port
这里的spark://master_host:master_port就是从上述的主节点的日志文件中抓取的主节点的URL。在所有的工作节点都启动之后可以查看主节点的WebUI界面,它会显示所有的处于ALIVE状态的已经注册的工作节点。
- 转到每个工作节点的
$IGNITE_HOME目录然后通过运行如下的命令启动一个Ignite节点:
bin/ignite.sh
这时可以看到通过默认的配置Ignite节点会彼此发现对方。如果网络不允许多播通信,那么需要修改默认的配置文件然后配置TCP发现。
# 5.2.使用Spark-Shell
现在,在集群启动运行之后,可以运行spark-shell来验证这个集成:
1.启动spark-shell
- 还可能需要提供Ignite部件的Maven坐标(如果需要,可以使用
--repositories参数,但是它可能会被忽略):
./bin/spark-shell
--packages org.apache.ignite:ignite-spark:1.8.0
--master spark://master_host:master_port
--repositories http://repo.maven.apache.org/maven2/org/apache/ignite
- 或者也可以通过
--jars参数提供指向Ignite的jar文件的路径:
./bin/spark-shell --jars path/to/ignite-core.jar,path/to/ignite-spark.jar,path/to/cache-api.jar,path/to/ignite-log4j.jar,path/to/log4j.jar --master spark://master_host:master_port
这时可以看到Spark shell已经启动了。
注意,如果打算使用Spring的配置进行加载,则需要同时添加ignite-spring的依赖。
./bin/spark-shell
--packages org.apache.ignite:ignite-spark:1.8.0,org.apache.ignite:ignite-spring:1.8.0
--master spark://master_host:master_port
2.通过默认的配置创建一个Ignite上下文的实例
import org.apache.ignite.spark._
import org.apache.ignite.configuration._
val ic = new IgniteContext(sc, () => new IgniteConfiguration())
然后可以看到一些像下面这样的:
ic: org.apache.ignite.spark.IgniteContext = org.apache.ignite.spark.IgniteContext@62be2836
创建一个IgniteContext实例的另一个方式是使用一个配置文件,注意如果指向配置文件的路径是相对形式的,那么IGNITE_HOME环境变量应该是在系统中全局设定的,因为路径的解析是相对于IGNITE_HOME的。
import org.apache.ignite.spark._
import org.apache.ignite.configuration._
val ic = new IgniteContext(sc, "examples/config/spark/example-shared-rdd.xml")
3.通过使用默认配置中的"partitioned"缓存创建一个IgniteRDD的实例
val sharedRDD = ic.fromCache[Integer, Integer]("partitioned")
然后可以看到为partitioned缓存创建了一个RDD的实例:
shareRDD: org.apache.ignite.spark.IgniteRDD[Integer,Integer] = IgniteRDD[0] at RDD at IgniteAbstractRDD.scala:27
注意RDD的创建是一个本地的操作,并不会在Ignite集群上创建缓存。
4.这时可以用RDD让Spark做一些事情,比如,获取值小于10的所有键-值对
sharedRDD.filter(_._2 < 10).collect()
因为缓存还没有数据,因此结果会是一个空的数组:
res0: Array[(Integer, Integer)] = Array()
可以查看远程spark工作节点的日志文件然后可以看到Ignite上下文如何在集群内的所有远程工作节点上启动客户端。也可以启动命令行Visor然后查看partitioned缓存已经创建了。
5.在Ignite中保存一些值
sharedRDD.savePairs(sc.parallelize(1 to 100000, 10).map(i => (i, i)))
运行这个命令后可以通过命令行Visor查看缓存的大小是100000个元素。
6.现在要检查之前创建的状态在作业重启之后如何保持,关闭spark-shell然后重复步骤1-3,这时会再一次为partitioned缓存创建了Ignite上下文和RDD的实例,现在可以查看在RDD中有多少值大于50000的键
sharedRDD.filter(_._2 > 50000).count
因为在缓存中加入了从1到100000的连续数值,那么会得到结果50000:
res0: Long = 50000
# 6.发现并解决的问题
- 在IgniteRDD上调用任何活动时Spark应用或者Spark shell没有响应
如果在客户端模式(默认模式)下创建
IgniteContext然后又没有任何Ignite服务端节点启动时,就会发生这种情况,这时Ignite客户端会一直等待服务端节点启动或者超过集群连接超时时间后失败。当在客户端节点使用IgniteContext时应该启动至少一个服务端节点。 - 当使用IgniteContext时,抛出了
java.lang.ClassNotFoundException和org.apache.ignite.logger.java.JavaLoggerFileHandler在类路径中没有任何日志实现然后Ignite会试图使用标准的Java日志时,这个问题就会发生。Spark默认会使用单独的类加载器加载用户的所有jar文件,而Java日志框架是使用应用级类加载器来初始化日志处理器。要解决这个问题,可以将ignite-log4j模块加入使用的jar列表以使Ignite使用log4J作为日志记录器,或者就像安装与部署章节中描述的那样修改Spark的默认类路径。