# 计算网格
# 1.计算网格
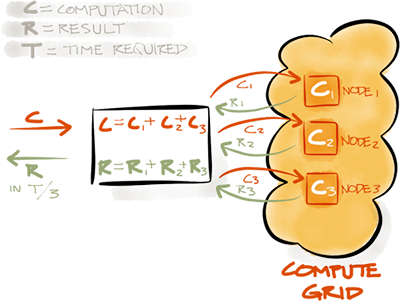
分布式计算以并行方式执行,以获得高性能、低延迟和线性扩展能力。Ignite计算网格提供了一组简单的API,可以在整个集群的多台计算机上执行分布式计算和数据处理,这样就可以利用所有节点的资源,来减少计算任务的整体执行时间。
# 1.1.Compute
Compute接口提供了在集群的所有节点中或者集群组中执行各种类型计算的方法,这些方法会以分布式的方式执行任务或者闭包。
只要集群中有一个节点在线,所有的作业和闭包都会保证执行,如果一个作业因为资源不足被拒绝,则Ignite会有故障转移机制来保障,这时负载平衡器会选择下一个可用的节点来执行作业,下面是获取Compute的方法:
Ignite ignite = Ignition.Get();
// Get compute instance over all nodes in the cluster.
Compute compute = ignite.GetCompute();
# 2.容错
# 2.1.概述
如果节点故障,Ignite支持自动作业故障转移,作业将自动转移到其它的可用节点重新执行。不过在Ignite中,也可以将任何作业结果视为失败,即工作节点仍然处于在线状态,但它可能在CPU、I/O、磁盘空间等方面资源不足。同时有许多情况可以导致应用中的故障,这也可以触发故障转移。此外,因为不同的应用或同一应用中的不同计算可能会有所不同,还可以选择作业应该故障转移到的节点。
对于执行失败的作业,FailoverSpi负责选择新的节点。FailoverSpi负责检查失败的作业以及可以重试作业执行的所有可用节点的列表。它确保作业不会重新映射到故障的同一节点。Ignite内置了许多定制化的故障转移SPI实现。
# 2.2.至少一次保证
只要至少有一个节点在线,就不会丢失任何作业。Ignite默认会自动从停止或故障的节点转移所有作业。
# 2.3.AlwaysFailOverSpi
为了加快处理速度,Ignite会将任务拆分为作业然后将其分配给多个节点。如果节点故障,AlwaysFailoverSpi会将失败的作业重新路由到另一个节点。具体做法是,在同一个任务对应的节点列表中,首先尝试将该作业重新路由到尚未执行任何其它作业的节点,如果找不到,则尝试将其重新路由到可能正在运行其它作业的节点之一,如果上述尝试均未成功,则作业将不会进行故障转移,并返回null。
可以使用以下配置参数配置AlwaysFailoverSpi:
| 属性 | 描述 | 默认值 |
|---|---|---|
maximumFailoverAttempts(int) | 设置故障转移的最大尝试次数 | 5 |
<bean id="grid.custom.cfg" class="org.apache.ignite.IgniteConfiguration" singleton="true">
...
<bean class="org.apache.ignite.spi.failover.always.AlwaysFailoverSpi">
<property name="maximumFailoverAttempts" value="5"/>
</bean>
...
</bean>
# 3.负载平衡
# 3.1.概述
负载平衡组件将作业在集群节点之间平衡分配。Ignite中负载平衡是通过LoadBalancingSpi实现的,它控制所有节点的负载以及确保集群中的每个节点负载水平均衡。对于同质化环境中的同质化任务,负载平衡采用的是随机或者轮询的策略。不过在很多其它场景中,特别是在一些不均匀的负载下,就需要更复杂的自适应负载平衡策略。
LoadBalancingSpi采用前负载技术,即在将其发送到集群之前就对作业在某个节点的执行进行了调度。
# 3.2.轮询式负载平衡
RoundRobinLoadBalancingSpi以轮询的方式在节点间迭代,然后选择下一个连续的节点。轮询式负载平衡支持两种操作模式:每任务以及全局,全局模式为默认模式。
每任务模式
如果配置成每任务模式,当任务开始执行时实现会随机地选择一个节点,然后会顺序地迭代拓扑中所有的节点,对于任务拆分的大小等同于节点的数量时,这个模式保证所有的节点都会参与任务的执行。
全局模式
如果配置成全局模式,对于所有的任务都会维护一个节点的单一连续队列然后每次都会从队列中选择一个节点。这个模式中(不像每任务模式),当多个任务并发执行时,即使任务的拆分大小等同于节点的数量,同一个任务的某些作业仍然可能被赋予同一个节点:
<bean id="grid.custom.cfg" class="org.apache.ignite.IgniteConfiguration" singleton="true">
...
<property name="loadBalancingSpi">
<bean class="org.apache.ignite.spi.loadbalancing.roundrobin.RoundRobinLoadBalancingSpi">
<!-- Set to per-task round-robin mode (this is default behavior). -->
<property name="perTask" value="true"/>
</bean>
</property>
...
</bean>
# 3.3.随机和加权负载平衡
WeightedRandomLoadBalancingSpi会为作业的执行随机选择一个节点。也可以选择为节点赋予权值,这样有更高权重的节点最终会使将作业分配给它的机会更多。所有节点的权重默认值都是10:
<bean id="grid.custom.cfg" class="org.apache.ignite.IgniteConfiguration" singleton="true">
...
<property name="loadBalancingSpi">
<bean class="org.apache.ignite.spi.loadbalancing.weightedrandom.WeightedRandomLoadBalancingSpi">
<property name="useWeights" value="true"/>
<property name="nodeWeight" value="10"/>
</bean>
</property>
...
</bean>
# 3.4.作业窃取
通常集群由很多计算机组成,这就可能存在配置不均衡的情况,这时开启JobStealingCollisionSpi就会有助于避免作业聚集在过载的节点,因为它们将被未充分利用的节点窃取。
JobStealingCollisionSpi支持将作业从高负载节点移动到低负载节点,当部分作业完成得很快,而其它的作业还在高负载节点中排队时,这个SPI就会非常有用。这种情况下,等待作业就会被移动到低负载的节点。
JobStealingCollisionSpi采用的是后负载技术,它可以在任务已经被调度在节点A执行后重新分配到节点B。
下面是配置JobStealingCollisionSpi的示例:
<bean class="org.apache.ignite.IgniteConfiguration" singleton="true">
<!-- Enabling the required Failover SPI. -->
<property name="failoverSpi">
<bean class="org.apache.ignite.spi.failover.jobstealing.JobStealingFailoverSpi"/>
</property>
<!-- Enabling the JobStealingCollisionSpi for late load balancing. -->
<property name="collisionSpi">
<bean class="org.apache.ignite.spi.collision.jobstealing.JobStealingCollisionSpi">
<property name="activeJobsThreshold" value="50"/>
<property name="waitJobsThreshold" value="0"/>
<property name="messageExpireTime" value="1000"/>
<property name="maximumStealingAttempts" value="10"/>
<property name="stealingEnabled" value="true"/>
<property name="stealingAttributes">
<map>
<entry key="node.segment" value="foobar"/>
</map>
</property>
</bean>
</property>
...
</bean>
必要的配置
注意org.apache.ignite.spi.failover.jobstealing.JobStealingFailoverSpi和IgniteConfiguration.getMetricsUpdateFrequency()都要开启,这样这个SPI才能正常工作,JobStealingCollisionSpi的其它配置参数都是可选的。
# 4.作业调度
# 4.1.概述
Ignite中,作业是在客户端侧的任务拆分初始化或者闭包执行阶段被映射到集群节点上的。不过一旦作业到达被分配的节点,就需要有序地执行。作业默认是被提交到一个线程池然后随机地执行,如果要对作业执行顺序进行细粒度控制,需要启用CollisionSpi。
# 4.2.FIFO排序
FifoQueueCollisionSpi可以使一定数量的作业无中断地以先入先出的顺序执行,所有其它的作业都会被放入一个等待列表,直到轮到它。
并行作业的数量是由parallelJobsNumber配置参数控制的,默认值为2.
一次一个
注意如果将parallelJobsNumber设置为1,可以保证所有作业同时只会执行一个,这样就没有任何两个作业并发执行:
<bean class="org.apache.ignite.IgniteConfiguration" singleton="true">
...
<property name="collisionSpi">
<bean class="org.apache.ignite.spi.collision.fifoqueue.FifoQueueCollisionSpi">
<!-- Execute one job at a time. -->
<property name="parallelJobsNumber" value="1"/>
</bean>
</property>
...
</bean>
# 5.分布式闭包
# 5.1.概述
Ignite计算网格可以对集群或者集群组内的任何闭包进行广播和负载平衡,包括runnables和callables。
# 5.2.计算作业
计算作业是从igniet::copmute::ComputeFunc<R>类模板继承的类,其中R是作业的返回类型(void为没有返回的作业)。它们应该是允许创建默认的构造函数、复制构造函数以及复制运算符,并且要实现Call方法,下面是一个示例:
// Simple job that prints "Hello world"
class HelloWorldJob : ComputeFunc<void>
{
public:
HelloWorldJob() = default;
HelloWorldJob(const HelloWorldJob&) = default;
HelloWorldJob& operator=(const HelloWorldJob&) = default;
virtual void Call()
{
std::cout << "Hello World!" << std::endl;
}
}
// Job that prints words of the provided text one-per-line.
class PrintWords : public compute::ComputeFunc<void>
{
friend struct ignite::binary::BinaryType<PrintWords>;
public:
PrintWords() = default;
PrintWords(const PrintWords&) = default;
PrintWords& operator=(const PrintWords&) = default;
PrintWords(const std::string& text) : text(text) { }
virtual void Call()
{
std::stringstream buf(text);
std::string word;
while (buf >> word)
std::cout << word << std::endl;
}
private:
std::string text;
};
// Job that counts number of words in a text.
class CountWords : public compute::ComputeFunc<int32_t>
{
friend struct ignite::binary::BinaryType<CountWords>;
public:
CountWords() = default;
CountWords(const CountWords&) = default;
CountWords& operator=(const CountWords&) = default;
CountWords(const std::string& text) : text(text) { }
virtual int32_t Call()
{
std::stringstream buf(text);
std::string word;
int32_t wordsCount = 0;
while (buf >> word)
++wordsCount;
return wordsCount;
}
private:
std::string text;
};
注意
为了传递给其它的节点,作业要被序列化和反序列化,因此需要为它们限定BinaryType<T>模板。具体内容可以参见序列化章节。
与远程过滤器一样,作业可以在随机节点上执行。为此,要确保在集群的所有节点上使用IgniteBinding::RegisterComputeFunc()注册作业:
// This callback called by Ignite on node startup and could be
// used to register code, that needs to be called remotely.
IGNITE_EXPORTED_CALL void IgniteModuleInit(ignite::IgniteBindingContext& context)
{
IgniteBinding binding = context.GetBingding();
binding.RegisterComputeFunc<HelloWorldJob>();
binding.RegisterComputeFunc<PrintWords>();
binding.RegisterComputeFunc<CountWords>();
}
// Alternatively you can register it manually.
// Note, that you should only register every user class once, so choose one method.
void SomeUserFunction()
{
//...
Ignite node = Ignition::Get("SomeNode");
IgniteBinding binding = node.GetBingding();
binding.RegisterComputeFunc<HelloWorldJob>();
binding.RegisterComputeFunc<PrintWords>();
binding.RegisterComputeFunc<CountWords>();
//...
}
# 5.3.Broadcast方法
所有的Broadcast(...)方法都会将作业广播到所有的集群节点上:
# 5.4.Call和Run方法
所有的Call(...)和Run(...)方法都是在集群上执行单个作业:
18624049226
