# 计算网格
# 1.计算网格
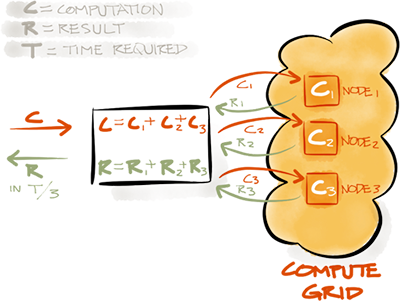
Ignite的计算网格可以将比如一个计算这样的逻辑片段,可选地拆分为多个部分,然后在不同的节点并行地执行,这样就可以并行地利用所有节点的资源,来减少计算任务的整体执行时间。并行执行的最常见设计模式就是MapReduce。但是,即使不需要对计算进行拆分或者并行执行,计算网格也会非常有用,因为它可以通过将计算负载放在多个可用节点上,提高整个系统的扩展性和容错能力。
计算网格的API非常简单,可以将计算和数据处理发布到集群的多个节点上,还可以配置失败策略来控制特定作业失败时的行为。
计算网格的关键特性包括:
- 自动部署:可以自动化地部署执行某个任务所必需的类和资源;
- 拓扑分解:可以根据节点的特性或者指定的配置来供应资源,比如,希望只在Linux节点上执行,或者在特定的时间窗口中只希望在某些节点上执行,还可能希望只在CPU负载在50%以下的节点中执行,或者希望有至少2G的可用堆内存等等;
- 冲突解决:可以控制哪些任务可以执行,哪些任务会被拒绝,多少任务并行执行以及执行的顺序等等;
- 负载平衡:可以正确地在集群中平衡负载,常见的包括轮询、随机和自适应,Ignite还提供基于关联的负载平衡,即任务根据其关联键,在该关联键所对应的节点上执行,这意味着代码的执行更接近其数据,即并置处理;
- 故障转移:可以配置自动或者手工的故障转移,这样在节点故障或者出现其它错误时,任务会自动地转移到其它的节点。
# 1.1.IgniteCompute
IgniteCompute接口提供了在集群节点或者一个集群组中运行很多种类型计算的方法,这些方法可以以一个分布式的形式执行任务或者闭包。
只要至少有一个节点有效,所有的作业和闭包就会保证得到执行,如果一个作业的执行由于资源不足被踢出,它会提供一个故障转移的机制。如果发生故障,负载平衡器会选择下一个有效的节点来执行该作业,下面的代码显示了如何获得IgniteCompute实例:
Ignite ignite = Ignition.ignite();
// Get compute instance over all nodes in the cluster.
IgniteCompute compute = ignite.compute();
也可以通过集群组来限制执行的范围,这时,计算只会在集群组内的节点上执行。
Ignite ignite = Ignitition.ignite();
ClusterGroup remoteGroup = ignite.cluster().forRemotes();
// Limit computations only to remote nodes (exclude local node).
IgniteCompute compute = ignite.compute(remoteGroup);
# 2.分布式闭包
# 2.1.概述
Ignite计算网格可以对集群或者集群组内的任何闭包进行广播和负载平衡,包括纯Java的runnables和callables。
# 2.2.broadcast方法
所有的broadcast(...)方法会将一个给定的作业广播到所有的集群节点或者集群组。
# 2.3.call和run方法
所有的call(...)和run(...)方法都可以在集群或者集群组内既可以执行单独的作业也可以执行作业的集合。
# 2.4.apply方法
闭包是一个代码块,它是把代码体和任何外部变量包装起来然后以一个函数对象的形式在内部使用它们,然后可以在任何传入一个变量的地方传递这样一个函数对象,然后执行。所有的apply方法都可以在集群内执行闭包。
# 3.Executor Service
IgniteCompute提供了一个方便的API以在集群内执行计算。虽然也可以直接使用JDK提供的标准ExecutorService接口,但是Ignite还提供了一个ExecutorService接口的分布式实现然后可以在集群内自动以负载平衡的模式执行所有计算。该计算具有容错性以及保证只要有一个节点处于活动状态就能保证计算得到执行,可以将其视为一个分布式的集群化线程池。
// Get cluster-enabled executor service.
ExecutorService exec = ignite.executorService();
// Iterate through all words in the sentence and create jobs.
for (final String word : "Print words using runnable".split(" ")) {
// Execute runnable on some node.
exec.submit(new IgniteRunnable() {
@Override public void run() {
System.out.println(">>> Printing '" + word + "' on this node from grid job.");
}
});
也可以限制作业在一个集群组中执行:
// Cluster group for nodes where the attribute 'worker' is defined.
ClusterGroup workerGrp = ignite.cluster().forAttribute("ROLE", "worker");
// Get cluster-enabled executor service for the above cluster group.
ExecutorService exec = ignite.executorService(workerGrp);
# 4.MapReduce和ForkJoin
# 4.1.概述
ComputeTask是Ignite对于简化内存内MapReduce的抽象,这个也非常接近于ForkJoin范式,纯粹的MapReduce从来不是为了性能而设计,只适用于处理离线的批量业务处理(比如Hadoop MapReduce)。不过当对内存内的数据进行计算时,实时性低延迟和高吞吐量通常具有更高的优先级。同样,简化API也变得非常重要。考虑到这一点,Ignite推出了ComputeTask API,它是一个轻量级的MapReduce(或ForkJoin)实现。
注意
只有当需要对作业到节点的映射做细粒度控制或者对故障转移进行定制的时候,才使用ComputeTask。对于所有其它的场景,都需要使用分布式闭包中介绍的集群内闭包执行来实现。
# 4.2.ComputeTask
ComputeTask定义了要在集群内执行的作业以及这些作业到节点的映射,它还定义了如何处理作业的返回值(Reduce)。所有的IgniteCompute.execute(...)方法都会在集群上执行给定的任务,应用只需要实现ComputeTask接口的map(...)和reduce(...)方法即可。
任务是通过实现ComputeTask接口的2或者3个方法定义的。
map方法
map(...)方法将作业实例化然后将它们映射到工作节点,这个方法收到任务要运行的集群节点的集合还有任务的参数,该方法会返回一个map,作业为键,映射的工作节点为值。然后作业会被发送到工作节点上并且在那里执行。
注意
关于map(...)方法的简化实现,可以参照下面的ComputeTaskSplitAdapter。
result方法
result(...)方法在每次作业在集群节点上执行时都会被调用,它接收计算作业返回的结果,以及迄今为止收到的作业结果的列表。该方法会返回一个ComputeJobResultPolicy的实例,说明下一步要做什么。
WAIT:等待所有剩余的作业完成(如果有)REDUCE:立即进入Reduce阶段,丢弃剩余的作业和还未收到的结果FAILOVER:将作业转移到另一个节点(参照容错章节),所有已经收到的作业结果也会在reduce(...)方法中有效
reduce方法
当所有作业完成后(或者从result(...)方法返回REDUCE结果策略),reduce(...)方法在Reduce阶段被调用。该方法接收到所有计算结果的一个列表然后返回一个最终的计算结果。
# 4.3.计算任务适配器
定义计算时每次都实现ComputeTask的所有三个方法并不是必须的,有一些帮助类使得只需要描述一个特定的逻辑片段即可,剩下的交给Ignite自动处理。
ComputeTaskAdapter
ComputeTaskAdapter定义了一个默认的result(...)方法实现,它在当一个作业抛出异常时返回一个FAILOVER策略,否则会返回一个WAIT策略,这样会等待所有的作业完成,并且有结果。
ComputeTaskSplitAdapter
ComputeTaskSplitAdapter继承了ComputeTaskAdapter,它增加了将作业自动分配给节点的功能。它隐藏了map(...)方法然后增加了一个新的split(...)方法,其只需要一个待执行的作业集合(这些作业到节点的映射会被适配器以负载平衡的方式自动处理)。
这个适配器对于所有节点都适于执行作业的同质化环境是非常有用的,这样映射阶段就可以隐式地完成。
# 4.4.ComputeJob
任务触发的所有作业都实现了ComputeJob接口,这个接口的execute()方法定义了作业的逻辑然后返回一个结果。cancel()方法定义了当一个作业被丢弃时的逻辑(比如,当任务决定立即进入Reduce阶段或者被取消)。
ComputeJobAdapter
这是一个提供了无操作的cancel()方法的方便的适配器类。
# 4.5.示例
下面是一个ComputeTask和ComputeJob的示例:
# 4.6.分布式任务会话
每个任务执行时都会创建分布式任务会话,它是由ComputeTaskSession接口定义的。任务会话对于任务和其产生的所有作业都是可见的,因此一个作业或者一个任务设置的属性也可以被其它的作业访问。任务会话也可以在属性设置或者等待属性设置时接收通知。
在任务及其相关的所有作业之间会话属性设置的顺序是一致的,不会出现一个作业发现属性A在属性B之前,而另一个作业发现属性B在属性A之前的情况。
在下面的例子中,让所有的作业在步骤1移动到步骤2之前是同步的:
@ComputeTaskSessionFullSupport注解
注意由于性能的原因分布式任务会话默认是禁用的,可以任务类上加注@ComputeTaskSessionFullSupport注解启用。
IgniteCompute compute = ignite.commpute();
compute.execute(new TaskSessionAttributesTask(), null);
/**
* Task demonstrating distributed task session attributes.
* Note that task session attributes are enabled only if
* @ComputeTaskSessionFullSupport annotation is attached.
*/
@ComputeTaskSessionFullSupport
private static class TaskSessionAttributesTask extends ComputeTaskSplitAdapter<Object, Object>() {
@Override
protected Collection<? extends GridJob> split(int gridSize, Object arg) {
Collection<ComputeJob> jobs = new LinkedList<>();
// Generate jobs by number of nodes in the grid.
for (int i = 0; i < gridSize; i++) {
jobs.add(new ComputeJobAdapter(arg) {
// Auto-injected task session.
@TaskSessionResource
private ComputeTaskSession ses;
// Auto-injected job context.
@JobContextResource
private ComputeJobContext jobCtx;
@Override
public Object execute() {
// Perform STEP1.
...
// Tell other jobs that STEP1 is complete.
ses.setAttribute(jobCtx.getJobId(), "STEP1");
// Wait for other jobs to complete STEP1.
for (ComputeJobSibling sibling : ses.getJobSiblings())
ses.waitForAttribute(sibling.getJobId(), "STEP1", 0);
// Move on to STEP2.
...
}
}
}
}
@Override
public Object reduce(List<ComputeJobResult> results) {
// No-op.
return null;
}
}
# 5.节点内状态共享
# 5.1.概述
通常来说在不同的计算作业或者服务之间共享状态是很有用的,为此Ignite在每个节点上提供了一个共享并发node-local-map。
IgniteCluster cluster = ignite.cluster();
ConcurrentMap<String, Integer> nodeLocalMap = cluster.nodeLocalMap();
节点局部变量类似于非分布式的线程局部变量,它只会保持在本地节点上。节点局部变量可以用于计算任务在不同的执行中共享状态,也可以用于部署的服务。
# 5.2.示例
作为一个示例,创建一个作业,每次当它在某个节点上执行时都会使节点局部的计数器增加,这样,每个节点的节点局部计数器都会通知某作业在那个节点上执行了多少次。
IgniteCallable<Long> job = new IgniteCallable<Long>() {
@IgniteInstanceResource
private Ignite ignite;
@Override
public Long call() {
// Get a reference to node local.
ConcurrentMap<String, AtomicLong> nodeLocalMap = ignite.cluster().nodeLocalMap();
AtomicLong cntr = nodeLocalMap.get("counter");
if (cntr == null) {
AtomicLong old = nodeLocalMap.putIfAbsent("counter", cntr = new AtomicLong());
if (old != null)
cntr = old;
}
return cntr.incrementAndGet();
}
};
现在在同一个节点上执行这个作业2次然后确保计数器的值为2:
ClusterGroup random = ignite.cluster().forRandom();
IgniteCompute compute = ignite.compute(random);
// The first time the counter on the picked node will be initialized to 1.
Long res = compute.call(job);
assert res == 1;
// Now the counter will be incremented and will have value 2.
res = compute.call(job);
assert res == 2;
# 6.计算和数据的并置
# 6.1.概述
计算和数据的并置可以最小化网络中的数据序列化,以及可以显著地提升应用的性能和可扩展性。只要可能,都应尝试将计算和存储待处理数据的节点并置在一起。
# 6.2.基于关联的call方法和run方法
affinityCall(...)和affinityRun(...)方法使作业和缓存着数据的节点位于一处,换句话说,给定缓存名字和关联键,这些方法会试图在指定的缓存中定位键所在的节点,然后在那里执行作业。
一致性保证
从Ignite1.8版本开始,可以保证在执行由affinityCall(...)或者affinityRun(...)触发的作业时,关联键所属的分区是不会从作业执行所处的节点退出的。而分区的再平衡通常是由拓扑变更事件触发的,比如新节点加入集群或者旧节点离开。
这个保证使得可以执行复杂的业务逻辑,因为作业执行的全过程中让数据一直位于同一个节点至关重要。比如,这个特性可以将执行本地SQL查询作为affinityCall(...)或者affinityRun(...)触发的作业的一部分,不用担心因为数据再平衡导致本地查询返回部分结果集。
注意
affinityCall(...)或者affinityRun(...)方法都有重载的版本,可以锁定分区,避免作业跨多个缓存执行时,分区的退出,要做的仅仅是将缓存的名字传递给上述方法。
# 7.容错
# 7.1.概述
Ignite支持作业的自动故障转移,当一个节点崩溃时,作业会被转移到其它可用节点再次执行。不过在Ignite中也可以将任何作业的结果认为是失败的。工作节点可以仍然是在线的,但是它运行在一个很低的CPU、I/O、磁盘空间等资源上,在很多情况下会导致应用的故障然后触发一个故障的转移。此外,也有选择一个作业故障转移到那个节点的功能,因为同一个应用内部不同的程序或者不同的计算也会是不同的。
FailoverSpi负责选择一个新的节点来执行失败作业。FailoverSpi检查发生故障的作业以及该作业可以尝试执行的所有可用的网格节点的列表。它会确保该作业不会再次映射到出现故障的同一个节点。故障转移是在ComputeTask.result(...)方法返回ComputeJobResultPolicy.FAILOVER策略时触发的。Ignite内置了一些可定制的故障转移SPI实现。
# 7.2.至少一次保证
只要有一个节点是有效的,作业就不会丢失。
Ignite默认会自动对停止或者故障的节点上的所有作业进行故障转移,如果要定制故障转移的行为,需要实现ComputeTask.result()方法。下面的例子显示了当一个作业抛出任何的IgniteException(或者它的子类)时会触发故障转移。
public class MyComputeTask extends ComputeTaskSplitAdapter<String, String> {
...
@Override
public ComputeJobResultPolicy result(ComputeJobResult res, List<ComputeJobResult> rcvd) {
IgniteException err = res.getException();
if (err != null)
return ComputeJobResultPolicy.FAILOVER;
// If there is no exception, wait for all job results.
return ComputeJobResultPolicy.WAIT;
}
...
}
# 7.3.闭包故障转移
闭包的故障转移是被ComputeTaskAdapter管理的,它在一个远程节点或者故障或者拒绝执行闭包时被触发。这个默认的行为可以被IgniteCompute.withNoFailover()方法覆盖,它会创建一个设置了无故障转移标志的IgniteCompute实例,下面是一个示例:
IgniteCompute compute = ignite.compute().withNoFailover();
compute.apply(() -> {
// Do something
...
}, "Some argument");
# 7.4.AlwaysFailOverSpi
Ignite将任务拆分成作业然后为了加快处理的速度将它们分配给多个节点执行,如果一个节点故障了,AlwaysFailoverSpi会将一个故障的作业路由到另一个节点,首先会尝试将故障的作业路由到该任务还没有被执行过的节点上,如果没有可用的节点,然后会试图将故障的作业路由到可能运行同一个任务中其它的作业的节点上,如果上述的尝试都失败了,那么该作业就不会被故障转移然后会返回一个null。
下面的配置参数可以用于配置AlwaysFailoverSpi:
| setter方法 | 描述 | 默认值 |
|---|---|---|
setMaximumFailoverAttempts(int) | 设置尝试将故障作业转移到其它节点的最大次数 | 5 |
# 8.负载平衡
# 8.1.概述
Ignite中负载平衡是通过LoadBalancingSpi实现的,它控制所有节点的负载以及确保集群中的每个节点负载水平均衡。对于同质化环境中的同质化任务,负载平衡采用的是随机或者轮询的策略。不过在很多其它场景中,特别是在一些不均匀的负载下,就需要更复杂的自适应负载平衡策略。
LoadBalancingSpi采用“前”负载技术,即在将其发送到集群之前就对作业在某个节点的执行进行了调度。
数据并置
注意,当作业还没有与数据并置或者还没有在哪个节点上执行的倾向时,负载平衡就已经触发了。如果使用了计算和数据的并置,那么数据的并置优先于负载平衡。
# 8.2.轮询式负载平衡
RoundRobinLoadBalancingSpi以轮询的方式在节点间迭代,然后选择下一个连续的节点。轮询式负载平衡支持两种操作模式:每任务以及全局,全局模式为默认模式。
每任务模式
如果配置成每任务模式,当任务开始执行时实现会随机地选择一个节点,然后会顺序地迭代拓扑中所有的节点,对于任务拆分的大小等同于节点的数量时,这个模式保证所有的节点都会参与任务的执行。
全局模式
如果配置成全局模式,对于所有的任务都会维护一个节点的单一连续队列然后每次都会从队列中选择一个节点。这个模式中(不像每任务模式),当多个任务并发执行时,即使任务的拆分大小等同于节点的数量,同一个任务的某些作业仍然可能被赋予同一个节点。
# 8.3.随机和加权负载平衡
WeightedRandomLoadBalancingSpi会为作业的执行随机选择一个节点。也可以选择为节点赋予权值,这样有更高权重的节点最终会使将作业分配给它的机会更多。所有节点的权重默认值都是10。
# 8.4.作业窃取
通常集群由很多计算机组成,这就可能存在配置不均衡的情况,这时开启JobStealingCollisionSpi就会有助于避免作业聚集在过载的节点,或者远离低利用率的节点。
JobStealingCollisionSpi支持作业从高负载节点到低负载节点的移动,当部分作业完成得很快,而其它的作业还在高负载节点中排队时,这个SPI就会非常有用。这种情况下,等待作业就会被移动到低负载的节点。
JobStealingCollisionSpi采用的是后负载技术,它可以在任务已经被调度在节点A执行后重新分配到节点B。
下面是配置JobStealingCollisionSpi的示例:
必要的配置
注意org.apache.ignite.spi.failover.jobstealing.JobStealingFailoverSpi和IgniteConfiguration.getMetricsUpdateFrequency()都要开启,这样这个SPI才能正常工作,JobStealingCollisionSpi的其它配置参数都是可选的。
# 9.检查点
# 9.1.概述
检查点提供了保存一个作业中间状态的能力,它有助于一个长期运行的作业保存一些中间状态以防节点故障。重启一个故障节点后,一个作业会从保存的检查点载入然后从故障处继续执行。要开启作业检查点状态,实现java.io.Serializable接口即可。
检查点功能可以通过GridTaskSession接口的如下方法启用:
ComputeTaskSession.loadCheckpoint(String)ComputeTaskSession.removeCheckpoint(String)ComputeTaskSession.saveCheckpoint(String, Object)
@ComputeTaskSessionFullSupport注解
注意检查点因为性能的原因默认是禁用的,要启用它需要在任务或者闭包类上加注@ComputeTaskSessionFullSupport注解。
# 9.2.主节点故障保护
检查点的一个重要使用场景是避免“主”节点(发起任务的节点)的故障。当主节点故障时,Ignite不知道将作业的执行结果发送给谁,这样结果就会被丢弃。
这种情况下要恢复,可以先将作业的最终执行结果保存为一个检查点然后在”主”节点故障时有一个逻辑来重新运行整个任务。这时任务的重新运行会非常快因为所有的作业都可以从已保存的检查点启动。
# 9.3.设置检查点
每个计算任务都可以通过调用ComputeTaskSession.saveCheckpoint(...)方法定期地保存检查点。
如果作业确实保存了检查点,那么当它开始执行时,应该检查检查点是否可用然后从最后保存的检查点处开始执行。
IgniteCompute compute = ignite.compute();
compute.run(new CheckpointsRunnable());
/**
* Note that this class is annotated with @ComputeTaskSessionFullSupport
* annotation to enable checkpointing.
*/
@ComputeTaskSessionFullSupport
private static class CheckpointsRunnable implements IgniteCallable<Object> {
// Task session (injected on closure instantiation).
@TaskSessionResource
private ComputeTaskSession ses;
@Override
public Object call() throws GridException {
// Try to retrieve step1 result.
Object res1 = ses.loadCheckpoint("STEP1");
if (res1 == null) {
res1 = computeStep1(); // Do some computation.
// Save step1 result.
ses.saveCheckpoint("STEP1", res1);
}
// Try to retrieve step2 result.
Object res2 = ses.loadCheckpoint("STEP2");
if (res2 == null) {
res2 = computeStep2(res1); // Do some computation.
// Save step2 result.
ses.saveCheckpoint("STEP2", res2);
}
...
}
}
# 9.4.CheckpointSpi
Ignite中,检查点功能是通过CheckpointSpi提供的,它直接支持下面的实现:
| 类 | 描述 |
|---|---|
SharedFsCheckpointSpi | 这个实现通过一个共享的文件系统来保存检查点 |
CacheCheckpointSpi | 这个实现通过缓存来保存检查点 |
JdbcCheckpointSpi | 这个实现通过数据库来保存检查点 |
S3CheckpointSpi | 这个实现通过Amazon S3来保存检查点 |
CheckpointSpi是在IgniteConfiguration中提供的,然后在启动时传递给Ignition类,默认使用一个没有任何操作的检查点SPI。
# 9.5.文件系统检查点配置
下面的配置参数可用于配置SharedFsCheckpointSpi:
| settter方法 | 描述 | 默认值 |
|---|---|---|
setDirectoryPaths(Collection) | 设置检查点要保存的共享文件夹的目录路径。这个路径既可以是绝对的也可以是相对于IGNITE_HOME环境变量或者系统参数指定的路径 | IGNITE_HOME/work/cp/sharedfs |
# 9.6.缓存检查点配置
CacheCheckpointSpi对于检查点SPI来说是一个基于缓存的实现,检查点数据会存储于Ignite数据网格中的一个预定义缓存中。
下面的配置参数可用于配置CacheCheckpointSpi:
| setter方法 | 描述 | 默认值 |
|---|---|---|
setCacheName(String) | 设置用于保存检查点的缓存名 | checkpoints |
# 9.7.数据库检查点配置
JdbcCheckpointSpi通过数据库来保存检查点。所有的检查点都会保存在数据库表中然后对于集群中的所有节点都是可用的。注意每个节点必须访问数据库。一个作业状态可以在一个节点保存然后在另一个节点载入(例如一个作业在节点故障后被另一个节点取代)。
下面的配置参数可用于配置JdbcCheckpointSpi,(所有的都是可选的)
| setter方法 | 描述 | 默认值 |
|---|---|---|
setDataSource(DataSource) | 设置用于数据库访问的数据源 | 无 |
setCheckpointTableName(String) | 设置检查点表名 | CHECKPOINTS |
setKeyFieldName(String) | 设置检查点键字段名 | NAME |
setKeyFieldType(String) | 设置检查点键字段类型,字段应该有相应的SQL字符串类型(比如VARCHAR) | VARCHAR(256) |
setValueFieldName(String) | 设置检查点值字段名 | VALUE |
setValueFieldType(String) | 设置检查点值字段类型,注意,字段需要有相应的SQL BLOB类型,默认值是BLOB,但不是所有数据库都兼容,比如,如果使用HSQL DB,那么类型应该为longvarbinary | BLOB |
setExpireDateFieldName(String) | 设置检查点过期时间字段名 | EXPIRE_DATE |
setExpireDateFieldType(String) | 设置检查点过期时间字段类型,字段应该有相应的DATETIME类型 | DATETIME |
setNumberOfRetries(int) | 任何数据库错误时的重试次数 | 2 |
setUser(String) | 设置检查点数据库用户名,注意只有同时设置了用户名和密码时,认证才会执行 | 无 |
setPwd(String) | 设置检查点数据库密码 | 无 |
Apache DBCP
Apache DBCP项目对于数据源和连接池提供了各种封装,可以通过Spring配置文件或者代码以spring bean的形式使用这些封装类来配置这个SPI,可以参照Apache DBCP来获得更多的信息。
# 9.8.Amazon S3 检查点配置
S3CheckpointSpi使用S3存储来保存检查点,但是前提是要有一个S3 bucket(桶),具体请参见http://aws.amazon.com/。
下面的参数可用于配置S3CheckpointSpi:
| setter方法 | 描述 | 默认值 |
|---|---|---|
setAwsCredentials(AWSCredentials) | 设置要使用的AWS凭证来保存检查点 | 无,但必须提供 |
setClientConfiguration(Client) | 设置AWS客户端配置 | 无 |
setBucketNameSuffix(String) | 设置bucket名字后缀 | default-bucket |
# 10.作业调度
# 10.1.概述
Ignite中,作业是在客户端侧的任务拆分初始化或者闭包执行阶段被映射到集群节点上的。不过一旦作业到达被分配的节点,就需要有序地执行。作业默认是被提交到一个线程池然后随机地执行,如果要对作业执行顺序进行细粒度控制,需要启用CollisionSpi。
# 10.2.FIFO排序
FifoQueueCollisionSpi可以使一定数量的作业无中断地以先入先出的顺序执行,所有其它的作业都会被放入一个等待列表,直到轮到它。
并行作业的数量是由parallelJobsNumber配置参数控制的,默认值为2.
一次一个
注意如果将parallelJobsNumber设置为1,可以保证所有作业同时只会执行一个,这样就没有任何两个作业并发执行。
# 10.3.优先级排序
PriorityQueueCollisionSpi可以为每个作业设置一个优先级,因此高优先级的作业会比低优先级的作业先执行。
任务优先级
任务优先级是通过任务会话中的grid.task.priority属性设置的,如果任务没有被赋予优先级,那么会使用默认值0。
下面是一个如何设置任务优先级的示例:
public class MyUrgentTask extends ComputeTaskSplitAdapter<Object, Object> {
// Auto-injected task session.
@TaskSessionResource
private ComputeTaskSession taskSes = null;
@Override
protected Collection<ComputeJob> split(int gridSize, Object arg) {
...
// Set high task priority.
taskSes.setAttribute("grid.task.priority", 10);
List<ComputeJob> jobs = new ArrayList<>(gridSize);
for (int i = 1; i <= gridSize; i++) {
jobs.add(new ComputeJobAdapter() {
...
});
}
...
// These jobs will be executed with higher priority.
return jobs;
}
}
配置
和FIFO排序一样,并行执行作业的数量是由parallelJobsNumber配置参数控制的。
# 11.任务部署
除了对等类加载之外,Ignite还有一个部署机制,它负责在运行时从不同的源中部署任务和类。
# 11.1.DeploymentSpi
部署的功能是通过DeploymentSpi接口提供的。
类加载器负责加载任务类(或者其它的类),它可以通过调用register(ClassLoader, Class)方法或者SPI自己来直接部署。比如通过异步地扫描一些文件夹来加载新的任务。当系统调用了findResource(String)方法时,SPI必须返回一个与给定的类相对应的类加载器。每次一个类加载器获得(再次)部署或者释放,SPI必须调用DeploymentListener.onUnregistered(ClassLoader)方法。
如果启用了对等类加载,因为通常只会在一个网格节点上部署类加载器,一旦一个任务在集群上开始执行,所有其它的节点都会从发起任务的节点自动加载所有的任务类。对等类加载也支持热部署。每次任务发生变化或者在一个节点上重新部署,所有其它的节点都会侦测到然后重新部署这个任务。注意对等类加载只在任务为非本地部署时才生效,否则本地部署总是具有优先权。
Ignite直接支持如下的DeploymentSpi实现:
- UriDeploymentSpi
- LocalDeploymentSpi
注意
SPI的方法不要直接使用。SPI提供了子系统的内部视图,由Ignite内部使用,需要访问这个SPI的某个实现的场景很少。可以通过Ignite.configuration()方法来获得这个SPI的一个实例,来检查它的配置属性或者调用其它的非SPI方法。再次注意从获得的实例中调用该接口的方法可能导致无法预期的行为,因此Ignite明确不会为此提供支持。
# 11.2.UriDeploymentSpi
这是DeploymentSpi的一个实现,它可以从不同的资源部署任务,比如文件系统文件夹、email和FTP。在集群中有不同的方式来部署任务以及每个部署方法都会依赖于所选的源协议。这个SPI可以配置与一系列的URI一起工作,每个URI都包括有关协议/传输加上配置参数比如凭证、扫描频率以及其它的所有数据。
当SPI建立一个与URI的连接时,为了防止扫描过程中的任何变化它会下载待部署的单元到一个临时目录,通过方法setTemporaryDirectoryPath(String)可以为下载的部署单元设置自定义的临时文件夹。SPI会在该路径下创建一个和本地节点ID名字同名的文件夹。
SPI会跟踪每个给定URI的所有变化。这意味着如果任何文件发生变化或者被删除,SPI会重新部署或者删除相应的任务。注意第一个调用findResource(String)是阻塞的,直到SPI至少一次完成了对所有URI的扫描。
下面是一些支持的可部署单元的类型:
- GAR文件
- 带有未解压GAR文件结构的本地磁盘文件夹
- 只包含已编译的Java类的本地磁盘文件夹
GAR文件
GAR文件是一个可部署的单元,GAR文件基于ZLIB压缩格式,类似简单JAR文件,它的结构类似于WAR包,GAR文件使用.gar扩展名。
GAR文件结构(以.gar结尾的文件或者目录):
META-INF/
|
- ignite.xml
- ...
lib/
|
-some-lib.jar
- ...
xyz.class
...
META-INF:包含任务描述的ignite.xml文件,任务描述XML格式文件的作用是指定所有要部署的任务。这个文件是标准的Spring格式XML定义文件,META-INF/也可以包含其它任何JAR格式规范定义范围内的文件;lib/:包含所有的依赖库jar文件;- 编译过的java类必须放在GAR文件的根目录中。
当然没有描述文件GAR文件也可以部署。如果没有描述文件,SPI会扫描包里的所有类然后实例化其中实现ComputeTask接口的,不过这样所有的任务类必须有一个公开的无参数的构造函数。为了方便,创建任务时也可以使用ComputeTaskAdapter适配器。
所有下载的GAR文件在META-INF文件夹都要有默认待认证的数字签名,然后只有在签名有效时才会被部署。
示例
下面的实例演示了可用的SPI是如何部署的,不同的协议也可以一起使用。
配置
| 属性 | 描述 | 可选 | 默认值 |
|---|---|---|---|
uriList | SPI扫描新任务的URI列表 | 是 | file://${IGNITE_HOME}/work/deployment/file,注意如果要使用默认文件夹,IGNITE_HOME必须设置。 |
scanners | 用于部署资源的UriDeploymentScanner实现的数组 | 是 | UriDeploymentFileScanner和UriDeploymentHttpScanner |
temporaryDirectoryPath | 要扫描的GAR文件和目录要拷贝的目标临时目录路径 | 是 | java.io.tmpdir系统属性值 |
encodeUri | 控制URI中路径部分编码的标志 | 是 | true |
协议
SPI直接支持如下协议:
- file:// - File协议
- http:// - HTTP协议
- https:// - 安全HTTP协议
自定义协议
如果需要可以增加其它的协议的支持,可以通过实现UriDeploymentScanner接口然后通过setScanners(UriDeploymentScanner... scanners)方法将实现加入SPI来做到这一点。
除了SPI配置参数之外,对于选择的URI所有必要的配置参数都应该在URI中定义。不同的协议有不同的配置参数,下面分别做了描述,参数是以分号分割的。
File
对于这个协议,SPI会在文件系统中扫描URI指定的文件夹然后从URI定义的源文件夹中下载任何的GAR文件或者目录中的以.gar结尾的文件。
支持如下的参数:
| 参数 | 描述 | 可选 | 默认值 |
|---|---|---|---|
freq | 扫描频率,以毫秒为单位 | 是 | 5000ms |
File URI示例
下面的示例会在本地每2000毫秒扫描c:/Program files/ignite/deployment文件夹。注意如果path有空格,setEncodeUri(boolean)参数必须设置为true(这也是默认的行为)。
file://freq=2000@localhost/c:/Program files/ignite/deployment
HTTP/HTTPS
URI部署扫描器会试图读取指向的HTML文件的DOM然后解析出所有的<a>标签的href属性 - 这会成为要部署的URL集合(到GAR文件):每个'A'链接都应该是指向GAR文件的URL。很重要的是只有HTTP扫描器会使用URLConnection.getLastModified()方法来检查自从重新部署之前对每个GAR文件的最后一次迭代以来是否有任何变化。
支持如下的参数:
| 参数 | 描述 | 可选 | 默认值 |
|---|---|---|---|
freq | 扫描频率,以毫秒为单位 | 是 | 300000ms |
HTTP URI示例
下面的示例会下载www.mysite.com/ignite/deployment页面,解析它然后每10000毫秒使用username:password进行认证,对从页面的所有a元素的href属性指定的所有GAR文件进行下载和部署。
http://username:password;freq=10000@www.mysite.com:110/ignite/deployment
# 11.3.LocalDeploymentSpi
本地部署SPI只是通过register(ClassLoader, Class)方法实现了在本地节点中的虚拟机进行部署,这个SPI不需要配置。
显式地配置LocalDeploymentSpi是没有意义的,因为它是默认的以及没有配置参数。
# 12.基于Cron的调度
# 12.1.概述
Runnable和Callable的实例可以使用IgniteScheduler.scheduleLocal()方法和Cron语法,在本地节点进行调度用于周期性的执行。
注意
要使用相关的调度功能,项目中需要引入ignite-schedule模块。
下面的示例会在所有的可用节点上触发周期性的发送缓存指标报告。
ignite.compute().broadcast(new IgniteCallable<Object>() {
@IgniteInstanceResource
Ignite ignite;
@Override
public Object call() throws Exception {
ignite.scheduler().scheduleLocal(new Runnable() {
@Override public void run() {
sendReportWithCacheMetrics(cache.metrics());
}
}, "0 0 *");
return null;
}
});
Cron简称
在当前的实现中,Cron简称(@hourly, @daily, @weekly...)还不支持,并且最小的调度时间单元是一分钟。
# 12.2.SchedulerFuture
IgniteScheduler.scheduleLocal()方法返回SchedulerFuture,它有一组有用的方法来监控调度的执行以及获得结果,通过它也可以取消周期性的执行。
SchedulerFuture<?> fut = ignite.scheduler().scheduleLocal(new Runnable() {
@Override public void run() {
...
}
}, "0 0 * * *");
System.out.println("The task will be next executed on " + new Date(fut.nextExecutionTime()));
fut.get(); // Wait for next execution to finish.
fut.cancel(); // Cancel periodic execution.
# 12.3.语法扩展
Ignite引入了一个Cron语法的扩展,它可以指定一个初始化的延迟(秒)和运行的次数。这两个可选的数值用大括号括起来,用逗号分割,放在Cron规范之前。下面的示例中指定了每分钟执行五次,并且有一个初始2秒钟的延迟。
{2, 5} * * * * *
# 13.持续映射
# 13.1.概述
传统的MapReduce范式中,有一个明确且有限的作业集,在Map阶段会处理它们并且整个计算运行期间都不会改变。但是如果有一个作业流会怎么样呢?这时仍然可以使用Ignite的持续映射能力执行MapReduce。通过持续映射,当计算仍然在运行时作业可以动态地生成,新生成的作业同样会被工作节点处理,并且Reducer和通常的MapReduce一样会收到结果。
# 13.2.运行持续的映射任务
如果在任务中要使用持续映射,需要在一个任务实例中注入TaskContinuousMapperResource资源:
@TaskContinuousMapperResource
private TaskContinuousMapper mapper;
之后,新的作业可以异步地生成,并且使用TaskContinuousMapper实例的send()方法加入当前正在运行的计算中:
mapper.send(new ComputeJobAdapter() {
@Override public Object execute() {
System.out.println("I'm a continuously-mapped job!");
return null;
}
});
对于持续映射,有几个约束需要了解:
- 如果最初的
ComputeTask.map()方法返回null,那么在返回之前通过持续映射器要至少发送一个作业; - 在
ComputeTask.result()方法返回REDUCE策略之后持续映射器无法使用; - 如果
ComputeTask.result()方法返回WAIT策略,并且所有的作业都已经结束,那么任务会进入REDUCE阶段并且持续映射器也不再使用。
在其它方面,计算逻辑和正常的MapReduce一样,详情可以参照14.2章节。
# 13.3.示例
下面的示例是基于网站包含的图片对其进行分析。Web搜索引擎会扫描站点上的所有图片,然后Ignite实现的MapReduce引擎会基于一些图片分析算法确定每个图片的种类(“含义”)。然后图片分析的结果会汇总确定站点的种类,这个示例会很好地演示持续映射,因为Web搜索是一个持续的过程,其中MapReduce可以并行地执行,并且分析到来的新的Web搜索结果(新的图片文件)。这会节省大量的时间,而传统的MapReduce,首先需要等待所有的Web搜索结果(一个完整的图片集),然后将它们映射到节点,分析,汇总结果。
假定有一个来自一些扫描站点图片的库的Crawler接口,CrawlerListener接口用于获得异步的后台扫描结果,然后一个Image接口表示一个单个图片文件(类名故意缩短以简化阅读):
interface Crawler {
...
public Image findNext();
public void findNextAsync(CrawlerListener listener);
...
}
interface CrawlerListener {
public void onImage(Crawler c, Image img) throws Exception;
}
interface Image {
...
public byte[] getBytes();
...
}
假定还有一个实现了ComputeJob的ImageAnalysisJob,它的逻辑是分析图片:
class ImageAnalysisJob implements ComputeJob, Externalizable {
...
public ImageAnalysisJob(byte[] imgBytes) {
...
}
@Nullable @Override public Object execute() throws IgniteException {
// Image analysis logic (returns some information
// about the image content: category, etc.).
...
}
}
上面的都准备好后,下面是如何运行Web搜索然后使用持续映射进行并行地分析:
enum SiteCategory {
...
}
// Instantiate a Web search engine for a particular site.
Crawler crawler = CrawlerFactory.newCrawler(siteUrl);
// Execute a continuously-mapped task.
SiteCategory result = ignite.compute().execute(new ComputeTaskAdapter<Crawler, SiteCategory>() {
// Interface for continuous mapping (injected on task instantiation).
@TaskContinuousMapperResource
private TaskContinuousMapper mapper;
// Map step.
@Nullable @Override
public Map<? extends ComputeJob, ClusterNode> map(List<ClusterNode> nodes, @Nullable Crawler c) throws IgniteException {
assert c != null;
// Find a first image synchronously to submit an initial job.
Image img = c.findNext();
if (img == null)
throw new IgniteException("No images found on the site.");
// Submit an initial job.
mapper.send(new ImageAnalysisJob(img.getBytes()));
// Now start asynchronous background Web search and
// submit new jobs as search results come. This call
// will return immediately.
c.findNextAsync(new CrawlerListener() {
@Override public void onImage(Crawler c, Image img) throws Exception {
if (img != null) {
// Submit a new job to analyse image file.
mapper.send(new ImageAnalysisJob(img.getBytes()));
// Move on with search.
c.findNextAsync(this);
}
}
});
// Initial job was submitted, so we can return
// empty mapping.
return null;
}
// Reduce step.
@Nullable @Override public SiteCategory reduce(List<ComputeJobResult> results) throws IgniteException {
// At this point Web search is finished and all image
// files are analysed. Here we execute some logic for
// determining site category based on image content
// information.
return defineSiteCategory(results);
}
}, crawler);
在上面这个示例中,为了简化,假定图片分析作业会比在站点上搜索下一张图片花费更长的时间。换句话说,新的Web搜索结果的到来会快于分析完图片文件。在现实生活中,这不一定是真的,并且可以轻易地获得一个情况,就是过早地完成了分析,因为当前所有的作业都已经完成而新的搜索结果还没有到达(由于网络延迟或者其它的原因)。这时,Ignite会切换至汇总阶段,因此持续映射就不再可能了。
要避免这样的情况,需要考虑提交一个特别的作业,它只是完成接收一些消息,或者使用可用的分布式同步化基本类型之一,比如CountDownLatch,这个做法可以确保在Web搜索结束之前汇总阶段不会启动。
# 14.启用基于AOP的网格
通过面向方面编程,可以隐式地修改任何方法的行为(比如,记录日志或者开启一个方法级的事务等)。在Ignite中,可以将方法加入运行在网格中的一个闭包,这和在一个方法上加注@Gridify注解一样简单。
@Gridify
public void sayHello() {
System.out.println("Hello!");
}
可以使用下面的AOP库:AspectJ、JBoss或者Spring AOP,只需要在主节点(发起执行的节点)上正确配置这些框架中的任何一个。仅仅上述方法的一个调用就会产生集群范围的一次任务执行,它会在拓扑内的所有工作节点上输出"Hello!"。
# 14.1.Gridify注解
@Gridify注解可以用于任何方法,它可以有如下的参数,所有参数都是可选的:
| 属性名称 | 类型 | 描述 | 默认值 |
|---|---|---|---|
taskClass | Class | 自定义任务类 | GridifyDefaultTask.class |
taskName | String | 要启动的自定义任务名 | “” |
timeout | long | 任务执行超时时间,0为没有超时限制 | 0 |
interceptor | Class | 过滤网格化方法的拦截器 | GridifyInterceptor.class |
gridName | String | 要使用的网格名 | “” |
通常,如果调用了一个网格化的方法,会发生如下事情:
- 通过
gridName指定的网格会用于执行(如果未指定网格名,默认会使用没有名字的网格); - 如果指定了,会使用一个拦截器检查方法是否应该启用网格化,如果拦截器返回
false,一个方法会像正常的一样被调用,而不会被网格化; - 通过有效的方法参数,
this对象(如果方法为非静态),会创建并且执行一个网格任务; - 这个网格任务的返回值会通过
网格化的方法返回。
默认的行为
如果使用了没有参数的@Gridify注解,会隐式地使用如下的默认的行为:
- 会创建一个名为
GridifyDefaultTask的任务类,它会生成一个GridifyJobAdapter作业类,然后使用一个默认的负载平衡器选择一个工作节点; - 远程节点的一个作业会通过内置的参数调用一个方法,使用反序列化的这个对象(如果方法为静态则为null),然后返回这个方法的结果作为作业的结果;
- 远程节点上作业的结果会作为调用端任务的结果;
- 任务的结果会返回,作为
网格化方法的返回值。
自定义任务
对于一个网格化的方法也可以自定义任务,用于特定的网格化逻辑。下面的示例会广播网格化的方法到所有有效的工作节点上,然后忽略reduce阶段(意味着这个任务没有返回值):
// Custom task class.
class GridifyBroadcastMethodTask extends GridifyTaskAdapter<Void> {
@Nullable @Override
public Map<? extends ComputeJob, ClusterNode> map(List<ClusterNode> subgrid, @Nullable GridifyArgument arg) throws IgniteException {
Map<ComputeJob, ClusterNode> ret = new HashMap<>(subgrid.size());
// Broadcast method to all nodes.
for (ClusterNode node : subgrid)
ret.put(new GridifyJobAdapter(arg), node);
return ret;
}
@Nullable @Override
public Void reduce(List<ComputeJobResult> list) throws IgniteException {
return null; // No-op.
}
}
public class GridifyHelloWorldTaskExample {
...
// Gridified method.
@Gridify(taskClass = GridifyBroadcastMethodTask.class)
public static void sayHello(String arg) {
System.out.println("Hello, " + arg + '!');
}
...
}
# 14.2.配置AOP
Ignite支持三个AOP框架:
- AspectJ
- JBoss AOP
- Spring AOP
这个章节会描述每个框架的详细配置,假定IGNITE_HOME是Ignite的安装目录。
这些细节只适用于逻辑主节点(初始化该次执行的节点),剩下的都应该是逻辑工作节点。
AspectJ
要启用AspectJ字节码织入,主节点的JVM需要通过如下方式进行配置:
- 启动时需要添加
-javaagent:IGNITE_HOME/libs/aspectjweaver-1.8.9.jar参数; - 类路径需要包含
IGNITE_HOME/config/aop/aspectj文件夹。
JBoss AOP
要启用JBoss的字节码织入,主节点的JVM需要有如下的配置:
- 启动时需要有如下参数:
- -javaagent:[指向jboss-aop-jdk50-4.x.x.jar的路径]
- -Djboss.aop.class.path=[ignite.jar的路径]
- -Djboss.aop.exclude=org,com
- -Djboss.aop.include=[应用的包名]
- 还要在类路径中包含如下的jar文件:
- javassist-3.x.x.jar
- jboss-aop-jdk50-4.x.x.jar
- jboss-aspect-library-jdk50-4.x.x.jar
- jboss-common-4.x.x.jar
- trove-1.0.2.jar
JBoss依赖
Ignite不带有JBoss,因此必要的库需要单独下载(如果已经安装了JBoss,这些都是标准的)。
Spring AOP
Spring AOP框架基于动态代理实现,对于在线织入不需要任何特定的运行时参数,所有的织入都是按需的,对于有加注了@Gridify注解的方法的对象会通过调用GridifySpringEnhancer.enhance()方法执行。
注意这个织入的方法是非常不方便的,推荐使用AspectJ或者JBoss AOP代替。当代码增强是不想要的并且无法使用时,Spring AOP适用于这样的场景,它也可以用于对织入什么进行细粒度的控制。
18624049226
