# 机器学习网格
# 1.机器学习网格
# 1.1.概述
Ignite的机器学习(ML)是一组简单的、可扩展以及高效的工具,在不需要成本高昂的数据转换的前提下,就可以构建可预测的机器学习模型。
将机器和深度学习加入Ignite的原理是很简单的,当前,如果要想让机器学习成为主流,数据科学家要解决两个主要的问题:
- 首先,模型是在不同的系统中训练和部署(训练结束之后)的,数据科学家需要等待ETL或者其它的数据传输过程,来将数据移至比如Apache Mahout或者Apache Spark这样的系统进行训练,然后还要等待这个过程结束并且将模型部署到生产环境。在系统间移动TB级的数据可能花费数小时的时间,此外,训练部分通常发生在旧的数据集上;
- 第二个问题和扩展性有关。机器学习和深度学习需要处理的数据量不断增长,已经无法放在单一的服务器上。这促使数据科学家要么提出更复杂的解决方案,要么切换到比如Spark或者TensorFlow这样的分布式计算平台上。但是这些平台通常只能解决模型训练的一部分问题,这给开发者之后的生产部署带来了很多的困难。
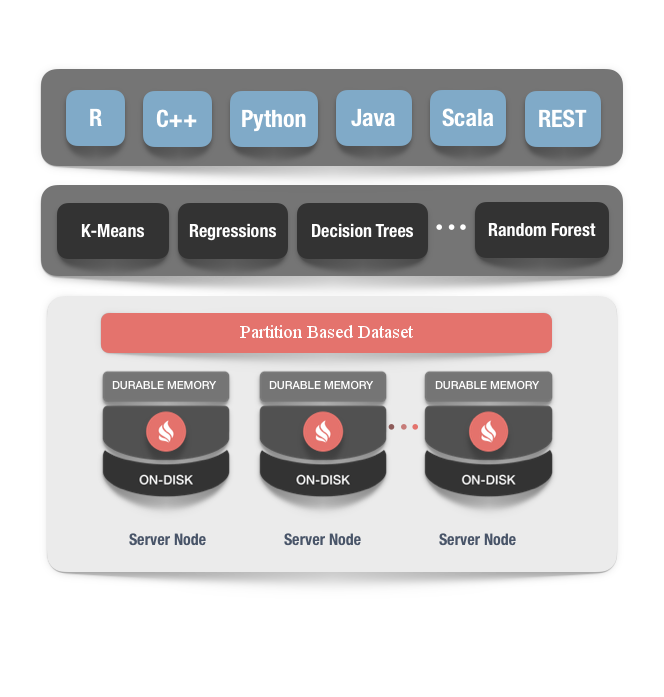
无ETL和大规模可扩展性
Ignite的机器学习依赖于Ignite基于内存的存储,这给机器学习和深度学习任务带来了大规模的扩展性,并且取消了在不同系统间进行ETL产生的等待。比如,在Ignite集群的内存和磁盘中存储的数据上,开发者可以直接进行深度学习和机器学习的训练和推理,然后,Ignite提供了一系列的机器学习和深度学习算法,对Ignite的分布式并置处理进行优化,这样在处理大规模的数据集或者不断增长的输入数据流时,这样的实现提供了内存级的速度和近乎无限的扩展性,而不需要将数据移到另外的存储。通过消除数据的移动以及长时间的处理等待,Ignite的机器学习可以持续地进行学习,可以在最新数据到来之时实时地对决策进行改进。
容错和持续学习
Ignite的机器学习能够对节点的故障容错。这意味着如果在学习期间节点出现故障,所有的恢复过程对用户是透明的,学习过程不会被中断,就像所有节点都正常那样获得结果。
# 1.2.算法和适用性
分类
根据训练的数据集,对标的的种类进行标识。
适用领域:垃圾邮件检测、图像识别、信用评分、疾病识别。
算法:支持向量机(SVM)、最近邻、决策树分类和神经网络。
回归
对因变量y与一个或多个解释变量(或自变量)x之间的关系进行建模。
适用领域:药物反应,股票价格,超市收入。
算法:线性回归、决策树回归、最近邻和神经网络。
聚类
对对象进行分组的方式,即在同一个组(叫做簇)中的对象(某种意义上)比其它簇中的对象更相似。
适用领域:客户细分、实验结果分组、购物项目分组。
算法:K均值
预处理
特征提取和归一化。
适用领域:对比如文本这样的输入数据进行转换,以便用于机器学习算法,然后提取需要拟合的特征,对数据进行归一化。
算法:Ignite的机器学习支持使用分区化的数据集自定义预处理,同时也有默认的预处理器。
# 1.3.入门
机器学习入门的最快方式是构建和运行示例代码,学习它的输出和代码,机器学习的的示例代码位于Ignite二进制包的examples文件夹中。
下面是相关的步骤:
- 下载Ignite的2.4及以后的版本;
- 在比如IntelliJ IDEA或者Eclipse这样的IDE中打开
examples工程; - 在IDE中打开
src/main/java/org/apache/ignite/examples/ml文件夹然后运行ML或者DL的示例。
这些示例不需要特别的配置,所有的ML或者DL示例在没有人为干预的情况下,都可以正常地启动、运行、停止,然后在控制台中输出有意义的信息。另外,还支持一个跟踪器API示例,它会启动一个Web浏览器然后生成一些HTML输出。
通过Maven获取
在工程中像下面这样添加Maven依赖后,就可以使用Ignite提供的机器学习功能:
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-ml</artifactId>
<version>${ignite.version}</version>
</dependency
将${ignite-version}替换为实际使用的Ignite版本。
从源代码构建
Ignite机器学习最新版的jar包已经上传到Maven仓库,如果需要获取该jar包然后部署到特定的环境中,那么要么从Maven仓库中进行下载,或者从源代码进行构建,如果要从源代码进行构建,按照如下步骤进行操作:
- 下载Ignite最新版的源代码;
- 清空Maven的本地仓库(这个是避免旧版本的可能影响);
- 从工程的根目录构建并安装Ignite;
mvn clean install -DskipTests -Dmaven.javadoc.skip=true
- 在本地仓库的
{user_dir}/.m2/repository/org/apache/ignite/ignite-ml/{ignite-version}/ignite-ml-{ignite-version}.jar中找到机器学习的jar包; - 如果要从源代码构建ML或者DL的示例,执行如下的命令:
cd examples
mvn clean package -DskipTests
如果必要,可以参考项目根目录的DEVNOTES.txt文件以及ignite-ml模块的README文件,以了解更多的信息。
# 2.预处理
# 2.1.概述
预处理是将存储于Ignite中的原始数据转换为特征向量,以便于机器学习算法的进一步使用,这个过程可以被视为一个转换链。正常流程是从Ignite数据中提取特征,对特征进行转换然后进行归一化,相关的转换代码如下:
// Define feature extractor.
IgniteBiFunction<Integer, double[], double[]> extractor = (k, v) -> v;
// Define feature transformer on top of extractor.
IgniteBiFunction<Integer, double[], double[]> extractorTransformer =
extractor.andThen(v -> transform(v));
// Define feature normalizer on top of transformer and extractor.
IgniteBiFunction<Integer, double[], double[]> extractorTransformerNormalizer =
normalizationTrainer.fit(ignite, upstreamCache, transformer);
# 2.2.归一化预处理器
除了可以自定义预处理器之外,Ignite还提供了一个内置的归一化预处理器,它会根据如下的函数对间隔的[0,1]进行归一化。
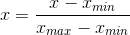 为了归一化,需要创建一个
为了归一化,需要创建一个NormalizationTrainer,然后将其与归一化预处理器进行匹配:
基于缓存的数据集:
// Create normalization trainer.
NormalizationTrainer<Integer, double[]> normalizationTrainer =
new NormalizationTrainer<>();
// Train normalization preprocessor.
IgniteBiFunction<Integer, double[], double[]> preprocessor =
normalizationTrainer.fit(
ignite,
upstreamCache,
(k, pnt) -> pnt.coordinates
);
// Create linear regression trainer.
LinearRegressionLSQRTrainer trainer = new LinearRegressionLSQRTrainer();
// Train model.
LinearRegressionModel mdl = trainer.fit(
ignite,
upstreamCache,
preprocessor,
(k, pnt) -> pnt.label
);
// Make a prediction.
double prediction = mdl.apply(preprocessor.apply(coordinates));
本地数据集:
// Create normalization trainer.
NormalizationTrainer<Integer, double[]> normalizationTrainer =
new NormalizationTrainer<>();
// Train normalization preprocessor.
IgniteBiFunction<Integer, double[], double[]> preprocessor =
normalizationTrainer.fit(
upstreamMap,
10, // Number of partitions.
(k, pnt) -> pnt.coordinates
);
// Create linear regression trainer.
LinearRegressionLSQRTrainer trainer = new LinearRegressionLSQRTrainer();
// Train model.
LinearRegressionModel mdl = trainer.fit(
upstreamMap,
10, // Number of partitions.
preprocessor,
(k, pnt) -> pnt.label
);
// Make a prediction.
double prediction = mdl.apply(coordinates);
# 2.3.示例
要了解归一化预处理器在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
# 3.分区化的数据集
# 3.1.概述
分区化的数据集是在Ignite的计算和存储能力之上构建的抽象层,可以在遵循无ETL和容错的原则下,进行算法运算。
分区化的数据集的主要原理是Ignite的计算网格实现的经典MapReduce范式。
MapReduce的主要优势在于,可以在分布于整个集群的数据上执行运算,而不需要大量的网络数据传输,这个想法对应于分区化的数据集,采用如下的方式:
- 每个数据集都是分区的;
- 分区在每个节点的本地,持有持久化的训练上下文以及可恢复的训练数据;
- 在一个数据集上执行的计算,会被拆分为Map操作和Reduce操作,Map操作负责在每个分区上执行运算,而Reduce操作会将Map操作的结果汇总为最终的结果。
训练上下文(分区上下文) 是Ignite分区中的持久化部分,因此在分区化的数据集关闭之前,对应于这部分的变更都会被一直维护,训练上下文不用担心节点故障,但是需要额外的时间进行读写,因此只有在无法使用分区数据的时候才使用它。
训练数据(分区数据) 是分区的一部分,可以在任何时候从上游数据以及上下文中恢复,因此没必要在持久化存储中维护分区数据,而是在每个节点的本地存储(堆内、堆外甚至GPU存储)中持有,如果节点故障,可以从其它节点的上游数据以及上下文中恢复。
为什么选择分区而不是节点作为数据集和学习的构建单元呢?
Ignite中的一个基本思想是,分区是原子化的,这意味着分区无法在多个节点上进行拆分(具体可以看分区和复制相关的章节)。在再平衡或者节点故障的情况下,分区在其它节点恢复时,数据和它在原来节点时保持一致。
而在机器学习算法中,这很重要,因为大多数机器学习算法是迭代的,并且需要在迭代之间保持一定的上下文,该上下文无法被拆分或者合并,并且应该在整个学习期间保持一致的状态。
# 3.2.使用
要构造一个分区化的数据集,可以这么做:
- 有一个上游的数据源,可以是Ignite的缓存或者仅仅是一个数据的Map;
- 分区上下文生成器,它定义了如何从对应于该分区的上游数据构建分区上下文;
- 分区数据生成器,它定义了如何从对应于该分区的上游数据构建分区数据;
基于缓存的数据集:
Dataset<MyPartitionContext, MyPartitionData> dataset =
new CacheBasedDatasetBuilder<>(
ignite, // Upstream Data Source
upstreamCache
).build(
new MyPartitionContextBuilder<>(), // Training Context Builder
new MyPartitionDataBuilder<>() // Training Data Builder
);
本地数据集:
Dataset<MyPartitionContext, MyPartitionData> dataset =
new LocalDatasetBuilder<>(
upstreamMap, // Upstream Data Source
10
).build(
new MyPartitionContextBuilder<>(), // Partition Context Builder
new MyPartitionDataBuilder<>() // Partition Data Builder
);
之后就可以在这个数据集上通过MapReduce的方式执行各种计算了。
int numerOfRows = dataset.compute(
(partitionData, partitionIdx) -> partitionData.getRows(),
(a, b) -> a == null ? b : a + b
);
最后,所有的计算完成后,注意一定要关闭数据集和释放资源。
dataset.close();
# 3.3.示例
要了解分区化的数据集在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite二进制包进行发布。
# 4.线性回归
# 4.1.概述
Ignite支持普通最小二乘线性回归算法,这是最基本也是最强大的机器学习算法之一,本章节会说明该算法的工作方式以及Ignite是如何实现的。
线性回归算法的基本原理是,假定因变量y和自变量x有如下的关系:
 注意,后续的文档中会使用向量x和b的点积,并且明确地避免使用常数项,当向量x由一个等于1的值补充时,在数学上是正确的。
注意,后续的文档中会使用向量x和b的点积,并且明确地避免使用常数项,当向量x由一个等于1的值补充时,在数学上是正确的。
如果向量b已知,上面的假设可以基于特征向量x进行预测,它反映在Ignite中负责预测的LinearRegressionModel类中。
# 4.2.模型
线性回归的模型表示为LinearRegressionModel类,它能够对给定的特征向量进行预测,如下:
LinearRegressionModel model = ...;
double prediction = model.predict(observation);
模型是完全独立的对象,训练之后可以被保存、序列化以及恢复。
# 4.3.训练法
线性回归是一种监督学习算法,这意味着为了找到参数(向量b),需要在训练数据集上进行训练,并且使损失函数最小化。
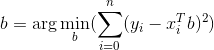 Ignite支持两种线性回归训练法,基于LSQR算法的训练法以及另一个基于随机梯度下降法的训练法。
Ignite支持两种线性回归训练法,基于LSQR算法的训练法以及另一个基于随机梯度下降法的训练法。
LSQR训练法
LSQR算法是为线性方程组找到大的、稀疏的最小二乘解,Ignite实现了这个算法的分布式版本。
基于缓存的数据集:
// Create linear regression trainer.
LinearRegressionLSQRTrainer trainer = new LinearRegressionLSQRTrainer();
// Train model.
LinearRegressionModel mdl = trainer.fit(
ignite,
upstreamCache,
(k, pnt) -> pnt.coordinates,
(k, pnt) -> pnt.label
);
// Make a prediction.
double prediction = mdl.apply(coordinates);
本地数据集:
// Create linear regression trainer.
LinearRegressionLSQRTrainer trainer = new LinearRegressionLSQRTrainer();
// Train model.
LinearRegressionModel mdl = trainer.fit(
upstreamMap,
10, // Number of partitions.
(k, pnt) -> pnt.coordinates,
(k, pnt) -> pnt.label
);
// Make a prediction.
double prediction = mdl.apply(coordinates);
SGD训练法
另一个线性回归训练法会使用随机梯度下降法来寻找损失函数的最小值。该训练法的配置类似于多层感知训练法的配置,可以指定更新类型(Nesterov的SGD,RProp)、最大迭代次数、批量大小、局部迭代次数和种子。
基于缓存的数据集:
// Create linear regression trainer.
LinearRegressionSGDTrainer<?> trainer = new LinearRegressionSGDTrainer<>(
new UpdatesStrategy<>(
new RPropUpdateCalculator(),
RPropParameterUpdate::sumLocal,
RPropParameterUpdate::avg
),
100000, // Max iterations.
10, // Batch size.
100, // Local iterations.
123L // Random seed.
);
// Train model.
LinearRegressionModel mdl = trainer.fit(
ignite,
upstreamCache,
(k, pnt) -> pnt.coordinates,
(k, pnt) -> pnt.label
);
// Make a prediction.
double prediction = mdl.apply(coordinates);
本地数据集:
// Create linear regression trainer.
LinearRegressionSGDTrainer<?> trainer = new LinearRegressionSGDTrainer<>(
new UpdatesStrategy<>(
new RPropUpdateCalculator(),
RPropParameterUpdate::sumLocal,
RPropParameterUpdate::avg
),
100000, // Max iterations.
10, // Batch size.
100, // Local iterations.
123L // Random seed.
);
// Train model.
LinearRegressionModel mdl = trainer.fit(
upstreamMap,
10, // Number of partitions.
(k, pnt) -> pnt.coordinates,
(k, pnt) -> pnt.label
);
// Make a prediction.
double prediction = mdl.apply(coordinates);
# 4.4.示例
要了解线性回归在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
# 5.K-均值聚类
在Ignite的机器学习组件中,提供了一个K-均值聚类算法的实现。
# 5.1.模型
K-均值聚类的目标是,将n个待观测值分为k个簇,这里每个观测值和所属的簇都有最近的均值,这被称为簇的原型。
该模型持有一个k中心向量以及距离指标,这些由比如欧几里得、海明或曼哈顿这样的机器学习框架提供。
通过如下的方式,可以预测给定的特征向量:
MeansModel mdl = ...;
double prediction = model.predict(observation);
# 5.2.训练法
K均值是一种无监督学习算法,它解决了将对象分组的聚类问题,即在同一个组(叫做簇)中的对象(某种意义上)比其它簇中的对象更相似。
K均值是一种参数化的迭代算法,在每个迭代中,计算每个簇中的新的均值,作为观测值的质心。
目前,Ignite为K均值分类算法支持若干个参数:
k:可能的簇的数量;maxIterations:终止条件(另一个是ε);- ε-δ收敛(新旧质心值之间的增量);
- 距离:机器学习框架提供的距离指标之一,例如欧几里得、海明或曼哈顿;
- 种子:一个初始化参数,有助于重现模型(该训练法有一个随机初始化步骤,以获得第一个质心)。
// Set up the trainer
KMeansTrainer trainer = new KMeansTrainer()
.withDistance(new EuclideanDistance())
.withK(AMOUNT_OF_CLUSTERS)
.withMaxIterations(MAX_ITERATIONS)
.withEpsilon(PRECISION);
// Build the model
KMeansModel knnMdl = trainer.fit(
datasetBuilder,
featureExtractor,
labelExtractor
);
# 5.3.示例
要了解线性回归在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
训练数据集是鸢尾花数据集的一个子集(具有标签1和标签2,它们是线性可分离的两类数据集),可以从UCL机器学习库加载。
# 6.遗传算法
# 6.1.概述
Ignite的机器学习组件包括一组遗传算法(GA),它是一种通过模拟生物进化过程来解决优化问题的一种方法。 遗传算法非常适合于以最优的方式检索大量复杂的数据集,在现实世界中,遗传算法的应用包括:汽车设计、计算机游戏、机器人、投资、交通和运输等等。
所有的遗传操作,比如适应度计算、交叉和变异,都会被建模为分布式的ComputeTask。此外,这些ComputeTask会通过Ignite的关联并置,将ComputeJob分发到染色体实际存储的节点。
下图是遗传算法的架构:
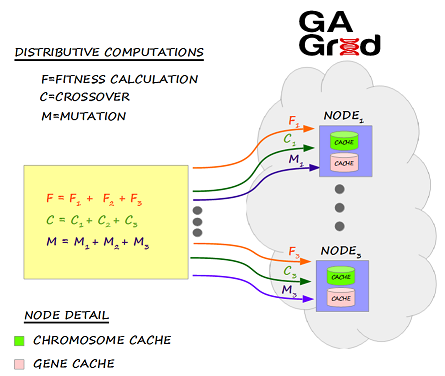 下图是遗传算法的执行步骤:
下图是遗传算法的执行步骤:
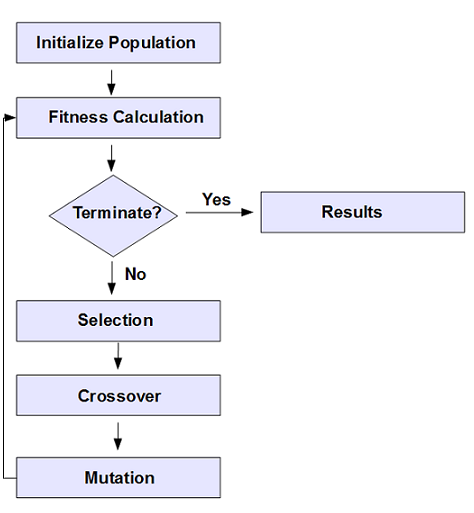
# 6.2.使用
下面会使用HelloWorldGAExample进行演示,一步步讲解遗传算法如何使用,目标是得到“HELLO WORLD”这个短语。
创建一个GAConfiguration
开始,需要创建一个GAConfiguration对象,这个类可以定义遗传算法的行为。
ignite = Ignition.start("examples/config/example-ignite.xml");
// Create GAConfiguration
gaConfig = new GAConfiguration();
定义基因和染色体
下一步,需要定义Gene,对于本示例对应的问题域,"HELLO WORLD"短语,因为离散部分都是字母,所以使用Character来对Gene建模,接下来,使用Character定义有27个Gene的基因库,下面的代码描述了这个过程:
List<Gene> genePool = new ArrayList();
char[] chars = { 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', ' ' };
for (int i = 0; i < chars.length; i++) {
Gene gene = new Gene(new Character(chars[i]));
genePool.add(gene);
}
gaConfig.setGenePool(genePool);
下一步,需要定义染色体,这是遗传算法的核心,因为它要对最优解进行建模。染色体由Gene构成,它表示了特定解的离散部分。
对于本示例来说,因为目标是包含“HELLO WORLD”的短语,所以染色体应该有11个基因(即字符),从代码上来说,需要将GAConfiguration的染色体长度设定为11。
// Set the Chromosome Length to '11' since 'HELLO WORLD' contains 11 characters.
gaConfig.setChromosomeLength(11);
在遗传算法的执行过程中,染色体通过交叉和变异的过程演化为最优解,然后,根据一个适应度得分,会选择一个最优解。
遗传算法从内部来说,会将染色体存储在染色体缓存中。
最优解:

实现适应度函数
遗传算法可以智能地执行自然选择的大部分过程,但是遗传算法是不了解具体的问题域的,因此需要定义一个适应度函数,它需要扩展自遗传算法的IFitnessFunction类,然后为每个染色体计算适应度得分,这个适应度得分用于决定各个解之间的优化程度,下面的代码会演示这个适应度函数:
public class HelloWorldFitnessFunction implements IFitnessFunction {
private String targetString = "HELLO WORLD";
@Override
public double evaluate(List<Gene> genes) {
double matches = 0;
for (int i = 0; i < genes.size(); i++) {
if (((Character) (genes.get(i).getValue())).equals(targetString.charAt(i))) {
matches = matches + 1;
}
}
return matches;
}
}
下一步,在GAConfiguration中配置HelloWorldFitnessFunction:
// Create and set Fitness function
HelloWorldFitnessFunction function = new HelloWorldFitnessFunction();
gaConfig.setFitnessFunction(function);
定义终止条件
下一步需要为遗传算法指定一个合适的终止条件,终止条件依赖于问题域,对于本示例来说,当染色体的适应度得分为11时,遗传算法就应该终止了。终止条件是通过实现ITerminateCriteria接口实现的,它只有一个方法isTerminateConditionMet()。
public class HelloWorldTerminateCriteria implements ITerminateCriteria {
private IgniteLogger igniteLogger = null;
private Ignite ignite = null;
public HelloWorldTerminateCriteria(Ignite ignite) {
this.ignite = ignite;
this.igniteLogger = ignite.log();
}
public boolean isTerminationConditionMet(Chromosome fittestChromosome, double averageFitnessScore, int currentGeneration) {
boolean isTerminate = true;
igniteLogger.info("##########################################################################################");
igniteLogger.info("Generation: " + currentGeneration);
igniteLogger.info("Fittest is Chromosome Key: " + fittestChromosome);
igniteLogger.info("Chromsome: " + fittestChromosome);
printPhrase(GAGridUtils.getGenesInOrderForChromosome(ignite, fittestChromosome));
igniteLogger.info("Avg Chromsome Fitness: " + averageFitnessScore);
igniteLogger.info("##########################################################################################");
if (!(fittestChromosome.getFitnessScore() > 10)) {
isTerminate = false;
}
return isTerminate;
}
/**
* Helper to print Phrase
*
* @param genes
*/
private void printPhrase(List<Gene> genes) {
StringBuffer sbPhrase = new StringBuffer();
for (Gene gene : genes) {
sbPhrase.append(((Character) gene.getValue()).toString());
}
igniteLogger.info(sbPhrase.toString());
}
}
下一步,需要为GAConfiguration配置HelloWorldTerminateCriteria:
// Create and set TerminateCriteria
HelloWorldTerminateCriteria termCriteria = new HelloWorldTerminateCriteria(ignite);
gaConfig.setTerminateCriteria(termCriteria);
种群的进化
最后一步就是通过GAConfiguration初始化一个GAGrid实例和Ignite实例,然后就可以调用GAGrid.evolve()执行种群的进化。
// Initialize GAGrid
gaGrid = new GAGrid(gaConfig, ignite);
// Evolve the population
Chromosome fittestChromosome = gaGrid.evolve();
# 6.3.启动
如果要使用遗传算法,打开命令终端,转到IGNITE_HOME目录,然后执行下面的脚本:
$ bin/ignite.sh examples/config/example-ignite.xml
在集群的每个节点中重复这个步骤。
然后打开另一个命令终端,转到IGNITE_HOME目录,然后输入:
mvn exec:java -Dexec.mainClass="org.apache.ignite.examples.ml.genetic.helloworld.HelloWorldGAExample"
启动之后,集群中的每个节点会看到类似下面的输出:
[21:41:49,327][INFO][main][GridCacheProcessor] Started cache [name=populationCache, mode=PARTITIONED]
[21:41:49,365][INFO][main][GridCacheProcessor] Started cache [name=geneCache, mode=REPLICATED]
下一步,在若干代之后,会看到下面的输出:
[19:04:17,307][INFO][main][] Generation: 208
[19:04:17,307][INFO][main][] Fittest is Chromosome Key: Chromosome [fitnessScore=11.0, id=319, genes=[8, 5, 12, 12, 15, 27, 23, 15, 18, 12, 4]]
[19:04:17,307][INFO][main][] Chromosome: Chromosome [fitnessScore=11.0, id=319, genes=[8, 5, 12, 12, 15, 27, 23, 15, 18, 12, 4]]
[19:04:17,310][INFO][main][] HELLO WORLD
[19:04:17,311][INFO][main][] Avg Chromosome Fitness: 5.252
[19:04:17,311][INFO][main][]
Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 53.883 sec
# 6.4.Apache Zeppelin集成
Apache Zeppelin是一个基于Web的笔记本,可以进行交互式的数据分析。下面会介绍如何利用Zeppelin的可视化特性来显示由遗传算法生成的优化解。
下面的步骤,对所有遗传算法的示例都有效。
Zeppelin的安装和配置
步骤如下:
- 从这里下载最新版的Zeppelin安装包;
- 将压缩包解压到一个目录中,该目录就作为
ZEPPELIN_HOME; - 将
ignite-core-2.5.0.jar从IGNITE_HOME/libs目录中复制到ZEPPELIN_HOME/interpreter/jdbc目录中,该包中包含Ignite的JDBC Thin模式驱动,Zeppelin会使用这个驱动从遗传算法网格中获取优化后的数据;
Zeppelin安装配置好后,可以通过如下命令启动:
./bin/zeppelin-daemon.sh start
Zeppelin启动之后,会看到下面的首页:
 下一步,选择
下一步,选择Interpreter菜单项:
 这个页面中包含了所有已配置的解释器的配置项。
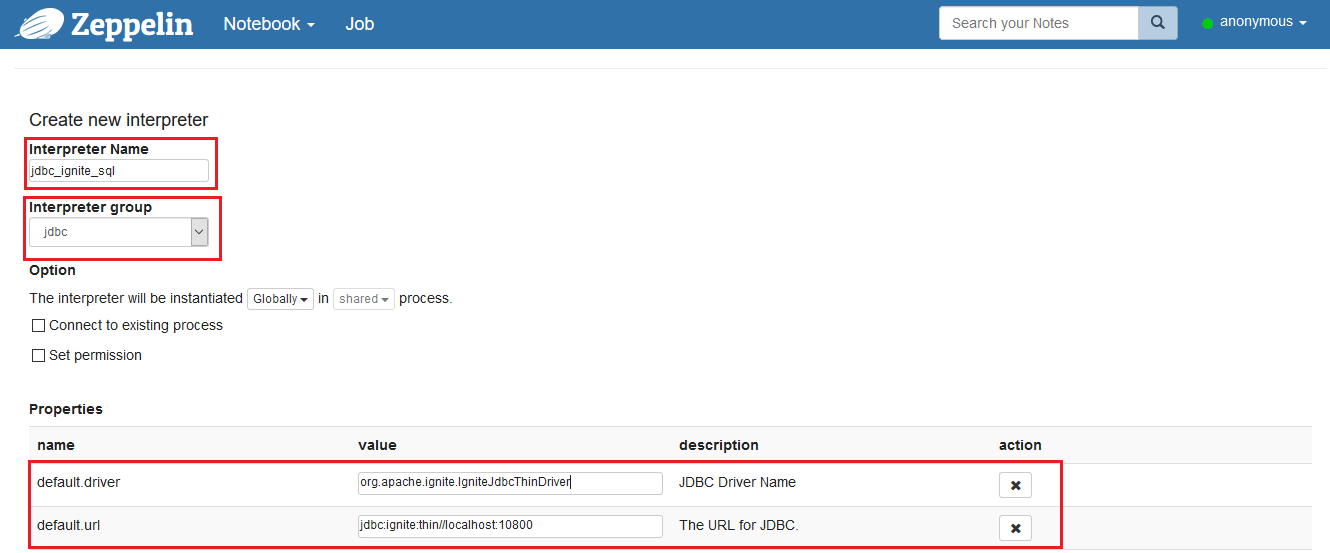
下一步,点击
这个页面中包含了所有已配置的解释器的配置项。
下一步,点击Create按钮,配置一个新的JDBC解释器,使用下表中的配置参数配置这个JDBC解释器:
| 配置项 | 值 |
|---|---|
| Interpreter Name | jdbc_ignite_sql |
| Interpreter group | jdbc |
| default.driver | org.apache.ignite.IgniteJdbcThinDriver |
| default.url | jdbc:ignite:thin//localhost:10800 |
 点击
点击Save按钮对变更的配置进行更新,配置变更后要记得重启解释器。
创建新的记事本
在Notebook标签页中,点击Create new note菜单项可以创建一个新的记事本:
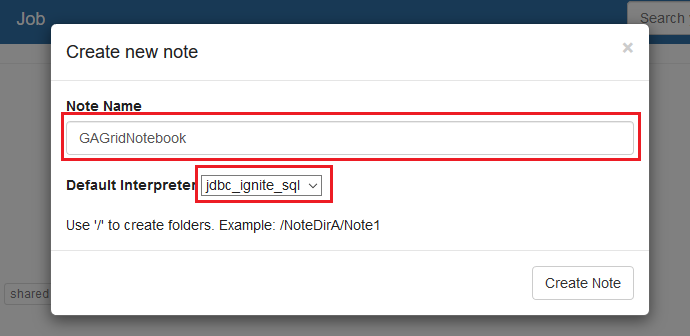
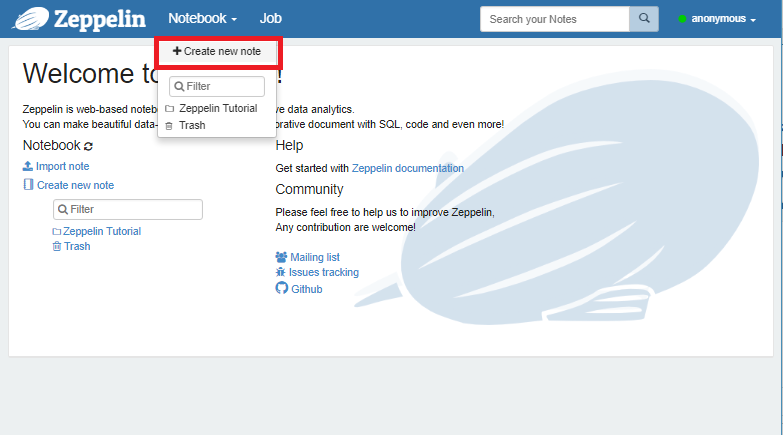 给记事本命名为
给记事本命名为GAGridNotebook,然后选中jdbc_ignite_sql作为默认的解释器,如下图所示,点击Create Note继续:
 到目前为止,新创建的笔记本如下图所示,如果要执行SQL查询,需要添加
到目前为止,新创建的笔记本如下图所示,如果要执行SQL查询,需要添加%jdbc_ignite_sql前缀:

记事本的使用
通过自定义SQL函数改进遗传的优化结果,可以改进遗传算法的知识发现,结果集中的列是由单个遗传样本的染色体大小动态驱动的。
自定义SQL函数
在遗传算法的分布式缓存geneCache中,如下的SQL函数可以用:
| 函数名 | 描述 |
|---|---|
getSolutionsDesc() | 获得优化解,按照适应度得分倒序排列。 |
getSolutionsAsc() | 获得优化解,按照适应度得分升序排列。 |
getSolutionById(key) | 通过染色体键获取优化解。 |
要使用GAGridNotebook,可以启动一个独立的Ignite节点:
$ bin/ignite.sh IGNITE_HOME/examples/config/example-config.xml
运行HelloWorldGAExample这个示例:
mvn exec:java -Dexec.mainClass="org.apache.ignite.examples.ml.genetic.helloworld.HelloWorldGAExample"
当遗传算法为第一代生成最优解后,就可以进行数据查询了。
第一代
##########################################################################################
[13:55:22,589][INFO][main][] Generation: 1
[13:55:22,596][INFO][main][] Fittest is Chromosome Key: Chromosome [fitnessScore=3.0, id=460, genes=[8, 3, 21, 5, 2, 22, 1, 19, 18, 12, 9]]
[13:55:22,596][INFO][main][] Chromosome: Chromosome [fitnessScore=3.0, id=460, genes=[8, 3, 21, 5, 2, 22, 1, 19, 18, 12, 9]]
[13:55:22,598][INFO][main][] HCUEBVASRLI
[13:55:22,598][INFO][main][] Avg Chromosome Fitness: 0.408
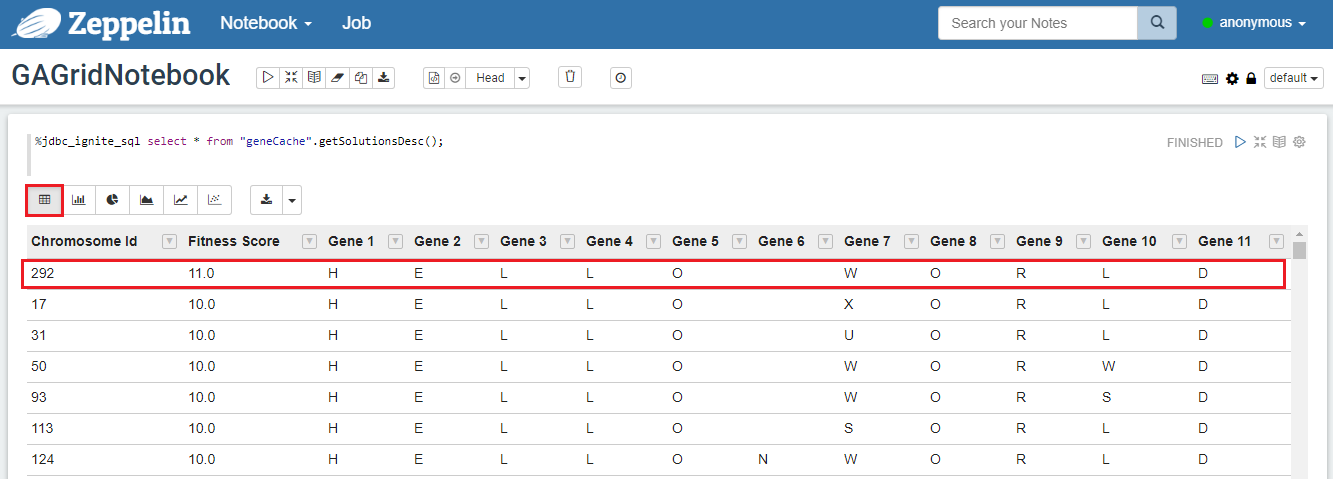
在Zeppelin的窗口中,输入下面的SQL然后点击execute按钮:
%jdbc_ignite_sql select * from "geneCache".getSolutionsDesc();
若干代之后,会发现解已经演变到最后的短语"HELLO WORLD",对于HellowWorldGAExample这个示例,遗传算法会为每一代维护一个500个解的种群,另外,本示例的解会包含总共11个基因,适应度得分最高的,会被认为是“最适合”。
# 6.5.词汇表
染色体:是一系列基因,一个染色体代表一个潜在的解;
交叉:是染色体内的基因结合以获得新染色体的过程;
适应度得分:是一个数值评分,测量一个特定染色体(即:解)相对于种群中其它染色体的价值;
基因:是组成染色体的离散构建块;
遗传算法(GA):是通过模拟生物进化过程来求解优化问题的一种方法。遗传算法持续增强种群潜在的解。在每次迭代中,遗传算法从当前种群中选择最合适的个体,为下一代创造后代。在随后的世代中,遗传算法将种群进化为最优解;
变异:是染色体内的基因被随机更新以产生新特性的过程;
种群:是潜在的解或染色体的集合;
选择:是为下一代选择候选解(染色体)的过程。
# 7.多层感知
# 7.1.概述
多层感知(MLP)是神经网络的基本形式,它由一个输入层和0或多个转换层组成,每个转换层都通过如下的方程依赖于前一个转换层:
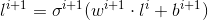 在上面的方程中,点运算符是两个向量的点积,由σ表示的函数称为激活函数,
在上面的方程中,点运算符是两个向量的点积,由σ表示的函数称为激活函数,w表示的向量称为权重,b表示的向量成为偏差。每个转换层都和权重、激活以及可选的偏差有关,MLP中中所有权重和偏差的集合,就被称为MLP的参数集。
# 7.2.模型
神经网络的模型由MultilayerPerceptron类表示,它可以对给定的特征向量通过如下方式进行预测:
MultilayerPerceptron mlp = ...
Matrix prediction = mlp.apply(coordinates);
模型是完全独立的对象,训练后可以保存、序列化和恢复。
# 7.3.训练法
批量训练是监督模型训练的常用方法之一。在这种方法中,训练是迭代进行的,在每次迭代中,提取标记数据的subpart(batch)(由近似函数的输入和该函数的相应值组成的数据,通常称为“地面实况”),在这里使用这个子部分训练和更新模型参数,进行更新以使批处理中的损失函数最小化。
Ignite的MLPTrainer就是用于分布式批量训练的,它运行于MapReduce模式,每个迭代(称为全局迭代)由若干个并行迭代组成,这些迭代又相应地由若干局部步骤组成,每个局部迭代由它自己的工作进程来执行,并执行指定数量的本地步骤(成为同步周期)来计算模型参数的更新,然后会在发起训练的节点上累计所有的更新,并将其转换为全局更新,全局更新会被反馈给所有的工作进程,在达到标准之前,这个过程会一直持续。
MLPTrainer是参数化的,其中包括神经网络架构、损失函数、更新策略(SGD、RProp、Nesterov)、最大迭代数量、批处理大小、本地迭代和种子数量。
基于缓存的数据集、
// Define a layered architecture.
MLPArchitecture arch = new MLPArchitecture(2).
withAddedLayer(10, true, Activators.RELU).
withAddedLayer(1, false, Activators.SIGMOID);
// Define a neural network trainer.
MLPTrainer<SimpleGDParameterUpdate> trainer = new MLPTrainer<>(
arch,
LossFunctions.MSE,
new UpdatesStrategy<>(
new SimpleGDUpdateCalculator(0.1),
SimpleGDParameterUpdate::sumLocal,
SimpleGDParameterUpdate::avg
),
3000, // Max iterations.
4, // Batch size.
50, // Local iterations.
123L // Random seed.
);
// Train model.
MultilayerPerceptron mlp = trainer.fit(
ignite,
upstreamCache,
(k, pnt) -> pnt.coordinates,
(k, pnt) -> pnt.label
);
// Make a prediction.
Matrix prediction = mlp.apply(coordinates);
本地数据集:
// Define a layered architecture.
MLPArchitecture arch = new MLPArchitecture(2).
withAddedLayer(10, true, Activators.RELU).
withAddedLayer(1, false, Activators.SIGMOID);
// Define a neural network trainer.
MLPTrainer<SimpleGDParameterUpdate> trainer = new MLPTrainer<>(
arch,
LossFunctions.MSE,
new UpdatesStrategy<>(
new SimpleGDUpdateCalculator(0.1),
SimpleGDParameterUpdate::sumLocal,
SimpleGDParameterUpdate::avg
),
3000, // Max iterations.
4, // Batch size.
50, // Local iterations.
123L // Random seed.
);
// Train model.
MultilayerPerceptron mlp = trainer.fit(
upstreamMap,
10, // Number of partitions.
(k, pnt) -> pnt.coordinates,
(k, pnt) -> pnt.label
);
// Make a prediction.
Matrix prediction = mlp.apply(coordinates);
# 7.4.示例
要了解多层感知在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
# 8.决策树
# 8.1.概述
决策树是监督学习中一个简单而强大的模型。其主要思想是将特征空间分割成区域,每个区域中的值变化不大。一个区域中的值变化的度量被称为区域的纯度。
Ignite对于行数据存储,提供了一种优化算法,具体可以看15.3.分区化的数据集。
拆分是递归进行的,每次拆分创建的区域又可以进一步拆分,因此,整个过程可以用二叉树来描述,其中每个节点都代表一个特定的区域,其子节点为由另一个拆分派生出来的区域。
让一个训练集的每个样本独属于一些空间S,并且让p_i成为具有指数i的特征的一个预测,然后通过具有指数i的连续特征进行拆分:
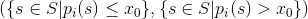 由分类特征和某些集合
由分类特征和某些集合x的值进行拆分:
 这里
这里X_0是x的一个子集。
该模型的工作方式为,当算法达到配置的最大深度时,拆分过程停止,或者任何区域的拆分没有导致明显的纯度损失。从S预测点s的值是将树向下遍历,直到节点对应的区域包含s,并返回与该叶子相关联的值。
# 8.2.模型
决策树分类的模型由DecisionTreeNode表示,对于给定的特征向量进行预测,如下所示:
DecisionTreeNode mdl = ...
double prediction = mdl.apply(observation);
模型是完全独立的对象,训练之后可以保存、序列化以及恢复。
# 8.3.训练法
决策树算法可用于基于纯度度量和节点实例化方法的分类和回归。
分类
分类决策树可用于Gini纯度度量,使用方法如下:
基于缓存的数据集:
// Create decision tree classification trainer.
DecisionTreeClassificationTrainer trainer = new DecisionTreeClassificationTrainer(
4, // Max deep.
0 // Min impurity decrease.
);
// Train model.
DecisionTreeNode mdl = trainer.fit(
ignite,
upstreamCache,
(k, pnt) -> pnt.coordinates,
(k, pnt) -> pnt.label
);
// Make a prediction.
double prediction = mdl.apply(coordinates);
本地数据集:
// Create decision tree classification trainer.
DecisionTreeClassificationTrainer trainer = new DecisionTreeClassificationTrainer(
4, // Max deep.
0 // Min impurity decrease.
);
// Train model.
DecisionTreeNode mdl = trainer.fit(
upstreamMap,
10, // Number of partitions.
(k, pnt) -> pnt.coordinates,
(k, pnt) -> pnt.label
);
// Make a prediction.
double prediction = mdl.apply(coordinates);
回归
回归决策树使用MSE纯度度量,使用方法如下:
基于缓存的数据集:
// Create decision tree classification trainer.
DecisionTreeRegressionTrainer trainer = new DecisionTreeRegressionTrainer(
4, // Max deep.
0 // Min impurity decrease.
);
// Train model.
DecisionTreeNode mdl = trainer.fit(
ignite,
upstreamCache,
(k, pnt) -> pnt.x,
(k, pnt) -> pnt.y
);
// Make a prediction.
double prediction = mdl.apply(x);
本地数据集:
// Create decision tree classification trainer.
DecisionTreeRegressionTrainer trainer = new DecisionTreeRegressionTrainer(
4, // Max deep.
0 // Min impurity decrease.
);
// Train model.
DecisionTreeNode mdl = trainer.fit(
upstreamMap,
10, // Number of partitions.
(k, pnt) -> pnt.x,
(k, pnt) -> pnt.y
);
// Make a prediction.
double prediction = mdl.apply(x);
# 8.4.示例
要了解决策树在实践中是如何使用的,可以看这个分类示例和回归示例,这些示例也会随着每个Ignite版本进行发布。
# 9.k-NN分类
对于广泛使用的k-NN(k-最近邻)算法,Ignite支持它的两个版本,一个是分类任务,另一个是回归任务。
本章节会描述k-NN作为分类任务的解决方案。
# 9.1.模型
K-NN算法是一种非参数方法,其输入由特征空间中的K-最近训练样本组成。
另外,k-NN分类的输出表示为类的成员。一个对象按其邻居的多数票进行分类。该对象会被分配为K近邻中最常见的一个特定类。k是正整数,通常很小,当k为1时是一个特殊的情况,该对象会简单地分配给该单近邻的类。
目前,Ignite为k-NN分类算法提供了若干参数:
k:最近邻数量;distanceMeasure:ML框架提供的距离度量之一,例如欧几里得、海明或曼哈顿;KNNStrategy:可以为SIMPLE或者WEIGHTED(开启加权k-NN算法);dataCache:持有一组已知分类的对象的训练集。
// Create trainer
KNNClassificationTrainer trainer = new KNNClassificationTrainer();
// Train model.
KNNClassificationModel knnMdl = trainer.fit(
ignite,
dataCache,
(k, v) -> Arrays.copyOfRange(v, 0, v.length - 1),
(k, v) -> v[2]
)
.withK(3)
.withDistanceMeasure(new EuclideanDistance())
.withStrategy(KNNStrategy.SIMPLE);
// Make a prediction.
double prediction = knnMdl.apply(vectorizedData);
# 9.2.示例
要了解k-NN分类在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
训练数据集是可以从UCI机器学习库加载的鸢尾花数据集。
# 10.k-NN回归
对于广泛使用的k-NN(k-最近邻)算法,Ignite支持它的两个版本,一个是分类任务,另一个是回归任务。
本章节会描述k-NN作为回归任务的解决方案。
# 10.1.模型
K-NN算法是一种非参数方法,其输入由特征空间中的K-最近训练样本组成。每个训练样本具有与给定的训练样本相关联的数值形式的属性值。
K-NN算法使用所有训练集来预测给定测试样本的属性值,这个预测的属性值是其k近邻值的平均值。如果k是1,那么测试样本会被简单地分配给单个最近邻的属性值。
目前,Ignite为k-NN分类算法提供了若干参数:
k:最近邻数量;distanceMeasure:ML框架提供的距离度量之一,例如欧几里得、海明或曼哈顿;KNNStrategy:可以为SIMPLE或者WEIGHTED(开启加权k-NN算法);datasetBuilder:帮助访问已知类的对象的训练集。
// Create trainer
KNNRegressionTrainer trainer = new KNNRegressionTrainer();
// Train model.
KNNRegressionModel knnMdl = (KNNRegressionModel) trainer.fit(
datasetBuilder,
(k, v) -> Arrays.copyOfRange(v, 1, v.length),
(k, v) -> v[0])
.withK(5)
.withDistanceMeasure(new ManhattanDistance())
.withStrategy(KNNStrategy.WEIGHTED);
// Make a prediction.
double prediction = knnMdl.apply(vectorizedData);
# 10.2.示例
要了解k-NN回归在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
训练数据集是可以从UCI机器学习库加载的鸢尾花数据集。
# 11.SVM二元分类
支持向量机(SVM)是相关数据分析学习算法中的监督学习模型,用于分类和回归分析。
给定一组训练样本,每一个被标记为属于两个类别中的一个,SVM训练算法会建立一个模型,该模型将新的样本分配给其中一个类别,使其成为非概率二元线性分类器。
Ignite机器学习模块只支持线性支持向量机。更多信息请参见维基百科中的支持向量机。
# 11.1.模型
SVM的模型表示为SVMLinearBinaryClassificationModel,它通过如下的方式对给定的特征向量进行预测:
SVMLinearBinaryClassificationModel model = ...;
double prediction = model.predict(observation);
目前,对于SVMLinearBinaryClassificationModel,Ignite支持一组参数:
isKeepingRawLabels:-1,和+1,分别对应false值和从分离超平面的原始距离(默认值false);threshold:如果原始值大于该阈值(默认值:0.0),则向观察者分配1个标签。
SVMLinearBinaryClassificationModel model = ...;
double prediction = model
.withRawLabels(true)
.withThreshold(5)
.predict(observation);
# 11.2.训练法
基于具有铰链损失函数的高效通信分布式双坐标上升算法(COCOA),提供软余量SVM线性分类训练法的基类。该训练法将输入作为具有-1和+1两个分类的标签化数据集,并进行二元分类。
关于这个算法的论文可以在这里找到。
目前,Ignite为SVMLinearBinaryClassificationTrainer支持如下参数:
amountOfIterations:外部SDCA算法的迭代量。(默认值:200);amountOfLocIterations:本地SDCA算法的迭代量。(默认值:100);lambda:正则化参数(默认值:0.4)。
// Set up the trainer
SVMLinearBinaryClassificationTrainer trainer = new SVMLinearBinaryClassificationTrainer()
.withAmountOfIterations(AMOUNT_OF_ITERATIONS)
.withAmountOfLocIterations(AMOUNT_OF_LOC_ITERATIONS)
.withLambda(LAMBDA);
// Build the model
SVMLinearBinaryClassificationModel mdl = trainer.fit(
datasetBuilder,
featureExtractor,
labelExtractor
);
# 11.3.示例
要了解SVM线性分类器在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
训练数据集可以从UCI机器学习库加载,其是鸢尾花数据集的子集(具有标签1和标签2的分类,它们是线性可分离的两类数据集)。
# 12.SVM多类分类
多类SVM的目的是通过使用支持向量机将标签分配给样本,其中标签是从多个元素的有限集合中提取的。
这个实现方法是通过一对所有的方法将单个多类问题总结成多个二元分类问题。
一对所有的方法是建立二元分类器的过程,它将一个标签和其余的区分开。
# 12.1.模型
该模型持有<ClassLabel, SVMLinearBinaryClassificationModel>对,它通过如下的方式对给定的特征向量进行预测:
SVMLinearMultiClassClassificationModel model = ...;
double prediction = model.predict(observation);
# 12.2.训练法
目前,Ignite为SVMLinearMultiClassClassificationTrainer支持如下的参数:
amountOfIterations:外部SDCA算法的迭代量。(默认值:200);amountOfLocIterations:本地SDCA算法的迭代量。(默认值:100);lambda:正则化参数(默认值:0.4)。
所有属性都会被传播到一对所有SVMLinearBinaryClassificationTrainer的每个对。
// Set up the trainer
SVMLinearMultiClassClassificationTrainer trainer = new SVMLinearMultiClassClassificationTrainer()
.withAmountOfIterations(AMOUNT_OF_ITERATIONS)
.withAmountOfLocIterations(AMOUNT_OF_LOC_ITERATIONS)
.withLambda(LAMBDA);
// Build the model
SVMLinearMultiClassClassificationModel mdl = trainer.fit(
datasetBuilder,
featureExtractor,
labelExtractor
);
# 12.3.示例
要了解SVM线性多类分类器在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
预处理的分类数据集可以从UCI机器学习库加载。
共有三个带标签的分类:1 (building_windows_float_processed),3 (vehicle_windows_float_processed),7 (headlamps) 以及特征名:'Na-Sodium','Mg-Magnesium','Al-Aluminum','Ba-Barium','Fe-Iron'。