# 计算网格
# 1.计算网格
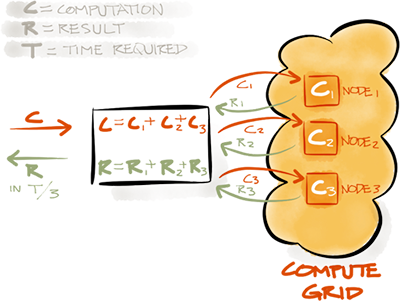
分布式计算通过并行执行来获得高性能、低延迟和线性扩展性。Ignite的计算网格通过一组简单的API,支持在集群中的多台计算机上执行分布式计算和数据处理。
# 1.1.ICompute
ICompute接口提供了在整个集群或集群组中的节点上运行多种类型计算的方法,这些方法可以以分布式方式执行任务或闭包。
只要有一个节点在线,就可以保证执行所有的作业和闭包。如果作业由于资源不足而无法执行,则将由故障转移机制处理。在发生故障时,负载平衡器将选择下一个可用节点来执行作业。下面是获取IgniteCompute实例的方法:
IIgnite ignite = Ignition.Start();
// Get compute instance over all nodes in the cluster.
ICompute compute = ignite.GetCompute();
IIgnite ignite = Ignition.Start();
// Get compute instance over all nodes in the cluster.
ICompute compute = ignite.GetCompute();
还可以将计算的范围限制为集群组,这时计算将仅在集群组内的节点上执行。
IIgnite ignite = Ignition.Start();
// Limit computations only to remote nodes (exclude local node).
ICompute compute = ignite.GetCluster().ForRemotes().GetCompute();
IIgnite ignite = Ignition.Start();
// Limit computations only to remote nodes (exclude local node).
ICompute compute = ignite.GetCluster().ForRemotes().GetCompute();
# 2.分布式闭包
Ignite.NET计算网格可以在整个集群或者集群组中广播以及负载平衡任何闭包代码。
# 2.1.Broadcast方法
所有的Broadcast(...)方法都会将指定的作业广播给整个集群或者集群组。
void Broadcast()
{
using (var ignite = Ignition.Start())
{
var compute = ignite.GetCluster().ForRemotes().GetCompute();
compute.Broadcast(new HelloAction());
// Async mode
compute.BroadcastAsync(new HelloAction())
.ContinueWith(t => Console.WriteLine("Finished sending broadcast job."));
}
}
[Serializable]
class HelloAction : IComputeAction
{
public void Invoke()
{
Console.WriteLine("Hello World!");
}
}
# 2.2.Call、Run和Apply方法
所有的Call(...)(无参数函数)、Run(...)(无动作)和Apply(...)(有参数函数)方法,都可以在整个集群或者集群组上,执行单个作业或者一组作业。
async void Compute()
{
using (var ignite = Ignition.Start())
{
var funcs = "Count characters using compute func".Split(' ')
.Select(word => new ComputeFunc { Word = word });
ICollection<int> res = ignite.GetCompute().Call(funcs);
// Async mode
res = await ignite.GetCompute().CallAsync(funcs);
var sum = res.Sum();
Console.WriteLine(">>> Total number of characters in the phrase is '{0}'.", sum);
}
}
[Serializable]
class ComputeFunc : IComputeFunc<int>
{
public string Word { get; set; }
public int Invoke()
{
return Word.Length;
}
}
# 3.MapReduce和ForkJoin
IComputeTask是Ignite.NET对内存MapReduce的简化抽象,它也非常类似于ForkJoin范式。纯粹的MapReduce并不是为了高性能而设计,仅仅是做离线批量数据处理(例如Hadoop中的MapReduce)时才能更好地发挥作用。不过当对内存中的数据进行计算时,实时低延迟和高吞吐量通常具有最高优先级,同样,API的简单性也变得非常重要,因此Ignite引入了IComputeTaskAPI,它是一种轻量级的MapReduce(或ForkJoin)实现。
提示
如果需要对作业到节点的映射或故障转移逻辑进行细粒度控制,才推荐IComputeTask。其他情况都应该使用更简单的闭包执行,具体细节请参见分布式闭包的相关章节。
# 3.1.IComputeTask
IComputeTask<,,>定义了要在集群上执行的作业,以及这些作业到节点的映射,它还定义了如何处理(汇总)作业的结果,而开发者应该实现IComputeTask接口的的Map(...)和Reduce(...)方法。
通过在IComputeTask接口上实现2或3个方法来定义任务:
Map方法
Map(...)方法会对作业进行实例化并将其映射到工作节点。该方法接收运行任务的节点集合以及任务的参数,并返回一个映射,其中作业为键,映射的工作节点为值,然后将作业发送到映射的节点并在其中执行。
提示
下面的ComputeTaskSplitAdapter有Map(...)方法的简化实现。
OnResult方法
OnResult(...)方法在作业执行完成时都会被调用。它接收该作业返回的结果,以及到目前为止收到的所有作业结果的列表。该方法应返回一个ComputeJobResultPolicy实例,指示下一步要执行的操作:
Wait:等待所有剩余作业完成(如果有);Reduce:立即进入汇总步骤,丢弃所有剩余的作业以及尚未收到的结果;Failover:将作业转移到另一个节点(请参见容错),所有接收到的作业结果在reduce(...)方法中仍然有效。
Reduce方法
Reduce(...)方法在所有作业都已完成(或从该OnResult(...)方法返回了Reduce策略)的汇总步骤被调用。该方法将接收所有完成的结果列表,并返回计算的最终结果。
# 3.2.计算任务适配器
不是每次定义并行计算时都需要实现IComputeTaskAPI的所有3种方法,有一些功能增强的类,开发者只需要实现一小段具体的业务逻辑,而将其余的部分留给Ignite自动处理。
# 3.2.1.ComputeTaskAdapter
ComputeTaskAdapter定义了OnResult(...)方法的默认实现,如果作业抛出异常,则该方法返回Failover策略,否则返回Wait策略,从而等待所有作业完成。
# 3.2.2.ComputeTaskSplitAdapter
ComputeTaskSplitAdapter扩展了ComputeTaskAdapter并添加了自动将作业分配给节点的功能。它隐藏了Map(...)方法,并添加了一个新的Split(...)方法,在该方法中,开发者仅需提供要执行的作业的集合即可(这些作业到节点的映射将由适配器以负载平衡的方式自动进行处理)。
该适配器在同质化环境中特别有用,这时所有节点都同样适合执行作业,因此映射步骤可以隐式完成。
# 3.3.IComputeJob
任务产生的所有作业都是IComputeJob接口的实现。其Execute()方法定义了具体的业务逻辑,并应返回作业结果。其Cancel()方法定义了作业被放弃(例如任务决定立即执行汇总或者取消)时所要执行的业务逻辑。
ComputeJobAdapter
简化适配器,提供了无任何操作的Cancel()方法实现。
# 3.4.示例
下面是IComputeTask和IComputeJob实现的示例:
ComputeTaskSplitAdapter:
void CountChars()
{
using (var ignite = Ignition.Start())
{
int charCount = ignite.GetCompute().Execute(new CharCountTask(), "Hello Grid Enabled World!");
Console.WriteLine(">>> Total number of characters in the phrase is " + charCount);
}
}
class CharCountTask : ComputeTaskSplitAdapter<string, int, int>
{
public override int Reduce(IList<IComputeJobResult<int>> results)
{
return results.Sum(res => res.Data);
}
protected override ICollection<IComputeJob<int>> Split(int gridSize, string arg)
{
// 1. Splits the received string into words
// 2. Creates a job for each word
return arg.Split(' ').Select(word => new CharCountJob {Word = word}).ToList<IComputeJob<int>>();
}
}
class CharCountJob : ComputeJobAdapter<int>
{
public string Word { get; set; }
public override int Execute()
{
return Word.Length;
}
}
ComputeTaskAdapter:
void CountChars()
{
using (var ignite = Ignition.Start())
{
int charCount = ignite.GetCompute().Execute(new CharCountTask(), "Hello Grid Enabled World!");
Console.WriteLine(">>> Total number of characters in the phrase is " + charCount);
}
}
class CharCountTask : ComputeTaskAdapter<string, int, int>
{
public override IDictionary<IComputeJob<int>, IClusterNode> Map(IList<IClusterNode> subgrid, string arg)
{
int nodeIdx = 0;
// 1. Splits the received string into words
// 2. Creates a job for each word
// 3. Distributes created jobs between nodes for processing.
return arg.Split(' ').Select(word => (IComputeJob<int>) new CharCountJob {Word = word}).ToDictionary(job => job, job => subgrid[nodeIdx++ % subgrid.Count]);
}
public override int Reduce(IList<IComputeJobResult<int>> results)
{
return results.Sum(res => res.Data);
}
}
private class CharCountJob : ComputeJobAdapter<int>
{
public string Word { get; set; }
public override int Execute()
{
return Word.Length;
}
}
# 4.数据和计算的并置
将计算与数据并置可以最大程度地减少网络内的数据序列化,并可以显著提高应用的性能和可扩展性,因此应尽量将计算与缓存待处理数据的节点并置在一起。
# 4.1.AffinityCall和AffinityRun方法
AffinityCall(...)和AffinityRun(...)方法将作业与其要处理的数据所在的节点并置,或者指定缓存名和关联键后,这些方法将尝试定位该键所在的节点,然后在该节点执行作业。
private void AffinityRun()
{
using (var ignite = Ignition.Start())
{
var compute = ignite.GetCluster().ForRemotes().GetCompute();
int key = 5;
// This closure will execute on the remote node where
// data with the 'key' is located.
compute.AffinityRun("myCache", key, new ComputeAction {Key = key});
}
}
class ComputeAction : IComputeAction
{
[InstanceResource]
private readonly IIgnite ignite;
public int Key { get; set; }
public void Invoke()
{
// Peek is a local memory lookup.
string value = ignite.GetCache<int, string>("myCache").LocalPeek(Key);
Console.WriteLine("Co-located [key={0}, value={1}]", Key, value);
}
}
# 5.容错
Ignite.NET支持自动化的作业故障转移,在节点故障时作业将自动转移到其他可用节点以重新执行。不过也可以将任何作业结果都视为失败,比如虽然工作节点仍然在线,但是它可能在CPU、I/O、磁盘空间等方面资源不足,这时可能会导致应用内发生故障,从而触发故障转移。此外,还可以选择将作业故障转移到指定节点,因为不同的应用或同一应用中的不同计算可能会有所不同。
FailoverSpi负责选择失败的作业在哪个新节点执行。FailoverSpi探测失败的作业以及可以在其上重试作业的所有可用节点的列表,它能保证作业不会被重新映射到失败的同一节点。当IComputeTask.OnResult(...)方法返回ComputeJobResultPolicy.Failover策略时,也会触发故障转移。Ignite内置了许多可自定义的故障转移SPI实现。
# 5.1.至少一次保证
只要有一个节点在线,就不会有作业丢失。
Ignite默认会自动对已停止或崩溃的节点上的所有作业进行故障转移。通过实现IComputeTask.OnResult()方法,可以自定义故障转移行为,以下示例在作业抛出任何异常时触发故障转移:
class MyTask : IComputeTask<string, int, int>
{
...
public ComputeJobResultPolicy OnResult(IComputeJobResult<int> res, IList<IComputeJobResult<int>> rcvd)
{
if (res.Exception != null)
return ComputeJobResultPolicy.Failover;
// If there is no exception, wait for all job results.
return ComputeJobResultPolicy.Wait;
}
...
}
# 5.2.闭包的故障转移
闭包的故障转移默认受ComputeTaskAdapter控制,如果远程节点故障或拒绝闭包的执行,都会触发。可以使用ICompute.WithNoFailover()方法覆盖此默认行为,其会创建一个带有no-failover标志的ICompute实例,下面是一个示例:
ICompute compute = ignite.GetCompute().WithNoFailover();
compute.Apply(..., "Some argument");
# 5.3.AlwaysFailOverSpi
AlwaysFailoverSpi总是将失败的作业路由到另一个节点。注意,首先将尝试将失败的作业路由到未在其上执行过该任务的节点,如果没有这样的节点可用,则将尝试将失败的作业路由到正在执行同一任务其他作业的节点。如果以上尝试均未成功,则该作业将不会故障转移,并且将返回null。
以下配置参数可用于配置AlwaysFailoverSpi:
| 属性 | 描述 | |
|---|---|---|
maximumFailoverAttempts(int) | 配置将失败的作业路由到其它节点的最大尝试次数 | 5 |
<bean id="grid.custom.cfg" class="org.apache.ignite.IgniteConfiguration" singleton="true">
...
<bean class="org.apache.ignite.spi.failover.always.AlwaysFailoverSpi">
<property name="maximumFailoverAttempts" value="5"/>
</bean>
...
</bean>