# 架构
# 1.IgniteSQL的工作方式
# 1.1.概述
Ignite的SQL引擎是与H2数据库紧紧绑定在一起的,简而言之,H2是一个Java写的,遵循一组开源许可证,基于内存和磁盘的速度很快的数据库。
当ignite-indexing模块加入节点的类路径之后,一个嵌入式的H2数据库实例就会作为Ignite节点进程的一部分被启动。如果节点是在终端中通过ignite.sh{bat}脚本启动的,那么该模块会自动地加入类路径,因为它已经被放入了{apache_ignite}\libs\目录中。
如果使用的是maven,那么需要将如下的依赖加入pom.xml文件:
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-indexing</artifactId>
<version>${ignite.version}</version>
</dependency>
Ignite借用了H2的SQL查询解析器以及优化器还有执行计划器。最后H2会在一个特定的节点执行本地化的查询,然后会将本地的结果集传递给分布式SQL引擎用于后续处理。
不过数据和索引,通常是存储于Ignite数据网格端的,而Ignite以分布式以及容错的方式执行SQL查询,这个是H2不支持的。
Ignite SQL网格执行查询有两种方式:
首先,如果查询在一个部署为REPLICATED模式缓存上执行,那么Ignite会将查询发送给一个单个集群节点,然后在其上的本地化数据上执行;
第二,如果查询执行于PARTITIONED模式缓存,那么执行流程如下:
- 查询会被解析然后拆分为多个映射查询以及一个汇总查询;
- 所有的映射查询都会在持有缓存数据的所有数据节点上执行;
- 所有的节点都会将本地执行的结果集提供给查询发起者(汇总节点),它会通过正确地合并结果集完成汇总的过程。
关联执行流程 关联查询的执行流程与上面描述的
分区缓存查询执行流程没什么不同。
# 1.2.并发修改
UPDATE和DELETE语句在内部会生成SELECT查询,目的是获得要更新的条目的集合。这个集合中的键是不会被锁定的,因此有一种可能就是在并发的情况下,属于某个键的值会被其它的查询修改。SQL引擎已经实现了一种技术,即首先避免锁定键,然后保证在DML语句执行更新时值是最新的。
总体而言,引擎会并发地检测要更新的缓存条目的子集,然后重新执行SELECT语句来限制要修改的键的范围。
比如下面的要执行的UPDATE语句:
UPDATE Person set firstName = 'Mike' WHERE lastName = 'Smith';
在firstName和lastName更新之前,DML引擎会生成SELECT查询来获得符合UPDATE语句的WHERE条件的缓存条目,语句如下:
SELECT _key, _value, 'Mike' from Person WHERE lastName = 'Smith';
_key和_val
_key和_val关键字用于获取同时获取对象的键和包含所有属性的值,同样的关键字也可以用于应用的代码中。
之后通过上面的SELECT获得的条目会被其它查询并发地更新:
UPDATE Person set firstName = 'Sarah' WHERE id = 1;
SQL引擎在UPDATE语句执行的更新阶段会检测到键为1的缓存条目要被修改,之后会暂停更新并且重新执行一个SELECT查询的修订版本来获得最新的条目值:
SELECT _key, _value, 'Mike' from Person WHERE secondName = 'Smith'
AND _key IN (SELECT * FROM TABLE(KEY long = [ 1 ]))
这个查询只会为过时的键执行,本例中只有一个键1。
这个过程会一直重复,直到DML引擎确信在更新阶段所有的条目都已经更新到最新版。尝试次数的最大值是4,目前并没有配置参数来改变这个值。
DML引擎不会为并发删除的条目重复执行
SELECT语句,重复执行的查询只针对还在缓存中的条目。
# 1.3.已知的限制
WHERE条件中的子查询 INSERT和MERGE语句中的子查询和UPDATE和DELETE操作自动生成的SELECT查询一样,如有必要都会被分布化然后执行,要么是并置,要么是非并置的模式。
但是,如果WHERE语句里面有一个子查询,那么它只能以并置的模式执行。
比如,有这样一个查询:
DELETE FROM Person WHERE id IN
(SELECT personId FROM Salary s WHERE s.amount > 2000);
SQL引擎会生成SELECT查询来获得要删除的条目列表,这个查询会在整个集群中分布化并且执行,如下所示:
SELECT _key, _val FROM Person WHERE id IN
(SELECT personId FROM Salary s WHERE s.amount > 2000);
不过IN子句中的子查询(SELECT personId FROM "salary".Salary ...)不会被进一步分布化,只会在一个集群节点的本地数据集上执行。
事务性支持
目前,SQL仅仅支持原子模式,这意味着如果有一个事务已经提交了一个值A,但是一个并行的SQL查询正在提交值B,这是会看到值A而看不到值B。
多版本并发控制(MVCC) 一旦Ignite SQL网格使用MVCC进行控制,DML操作也会支持事务模式。
DML语句的执行计划支持
目前DML操作不支持EXPLAIN。
一个方法就是执行UPDATE或DELETE语句自动生成的SELECT语句或者DML语句使用的INSERT或MERGE语句的执行计划,这样会提供一个要执行的DML操作所使用的索引情况。
# 2.分布式关联
# 2.1.概述
Ignite支持并置和非并置的分布式SQL关联,此外,如果数据位于不同的缓存,Ignite还可以进行跨缓存的关联。
SELECT from Person as p, Organization as org
WHERE p.orgId = org.id AND lower(org.name) = lower('apple')
分区和复制模式缓存之间的关联也可以无限制地进行。
不过如果在分区模式的数据集之间进行关联,那么一定要确保要么关联的键是并置的,要么为查询开启了非并置关联参数,两种类型的分布式关联模式下面会详述。
# 2.2.并置关联
默认情况下,如果一个SQL关联需要跨越多个Ignite缓存,那么所有的缓存都需要是并置的,否则,查询完成后会得到一个不完整的结果集,这是因为在关联阶段一个节点只能使用本地节点的可用数据。
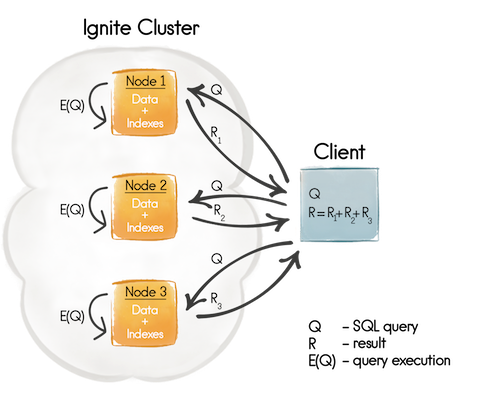
如图1所示,首先,一个SQL查询会被发送到待关联数据所在的节点(Q),然后查询在每个节点的本地数据上立即执行(E(Q)),最后,所有的执行结果都会在客户端进行聚合(R)。
# 2.3.非并置关联
虽然关联并置是一个强大的概念,即一旦配置了应用的业务实体(缓存),就可以以最优的方式执行跨缓存的关联,并且返回一个完整且一致的结果集。但还有一种可能就是,无法并置所有的数据,这时,就可能无法执行满足需求的所有SQL查询了。 Ignite设计和支持的非并置分布式关联就是针对的这样的场景,既无法或者很难并置所有的数据,但是仍然需要执行SQL查询。
在实践中不要过度使用基于非并置的分布式关联的方式,因为这种关联方式的性能差于基于关联并置的关联,因为要完成这个查询,要有更多的网络开销和节点间的数据移动。
当为一个SQL查询启用了非并置的分布式关联之后,查询映射的节点就会从远程节点通过发送广播或者单播请求的方式获取缺失的数据(本地不存在的数据)。
启用非并置的关联 可以查看JDBC, ODBC, Java, .NET, C++的相关文档来了解详细的信息。 以Jdbc为例,它需要在连接的URL连接串中添加
distributedJoins=true参数。
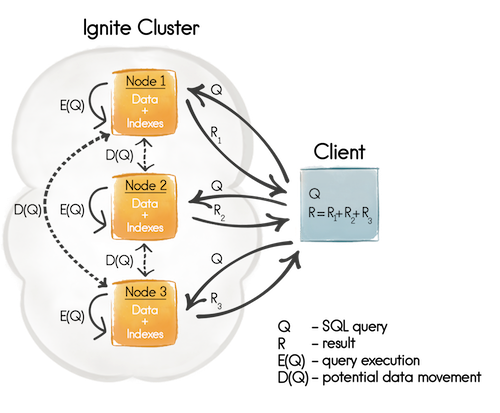
正如图2所示,有一个潜在的数据移动步骤(D(Q))。潜在的单播请求只会在关联在主键(缓存键)或者关联键上完成之后才会发送,因为执行关联的节点知道缺失数据的位置,其它所有的情况都会发送广播请求。
因为性能的原因,不管是广播还是单播请求,都是批量处理的,这个批量的大小是由
page size参数管理的。
# .3.3.本地查询
有时,SQL网格中查询的执行会从分布式模式回落至本地模式,在本地模式中,查询会简单地传递至底层的H2引擎,它只会处理本地节点的数据集。 这些场景包括:
- 如果一个查询在部署有
复制缓存的节点上执行,那么Ignite会假定所有的数据都在本地,然后就会隐式地在本地执行一个简单的查询; - 查询在
本地缓存上执行; - 使用
local = true参数为查询显式地开启本地模式,该功能只有原生的Java、.NET和C++ API才支持,比如,在Java中该参数是通过SqlQuery.setLocal(true)或者SqlFieldsQuery.setLocal(true)进行切换;
即使查询执行时拓扑发生变化(新节点加入集群或者老节点离开集群),前两个场景也会一直提供完整而一致的结果集。
不过在应用显式开启本地模式的第三个场景中需要注意,原因是如果希望在部分节点的分区缓存上执行本地查询时拓扑还发生了变化,那么可能得到结果集的一部分,因为这时会触发一个自动的数据再平衡过程,SQL引擎无法处理这个特殊情况。
如果仍然希望在分区缓存上执行本地查询,那么需要考虑使用这里描述的关联计算技术。
# 4.空间支持
# 4.1.概述
Ignite除了支持标准ANSI-99标准的SQL查询,支持基本数据类型或者特定/自定义对象类型之外,还可以查询和索引几何数据类型,比如点、线以及包括这些几何形状空间关系的多边形。
空间信息的查询功能,以及对应的可用的函数和操作符,是在SQL的简单特性规范中定义的,目前,Ignite通过JTS Topology Suite的使用,支持规范的交叉操作。
# 4.2.引入Ignite空间库
Ignite的空间库(ignite-geospatial)依赖于JTS,它是LGPL许可证,不同于Apache的许可证,因此ignite-geospatial并没有包含在Ignite的二进制包中。
因为这个原因,ignite-geospatial的二进制库版本位于如下的Maven仓库中:
<repositories>
<repository>
<id>GridGain External Repository</id>
<url>http://www.gridgainsystems.com/nexus/content/repositories/external</url>
</repository>
</repositories>
在pom.xml中添加这个仓库以及如下的Maven依赖之后,就可以将该空间库引入应用中了。
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-geospatial</artifactId>
<version>${ignite.version}</version>
</dependency>
另外,也可以下载Ignite的源代码自己构建这个库。
# 5.性能和调试
# 5.1.使用EXPLAIN语句
为了读取执行计划以及提高查询性能的目的,Ignite支持EXPLAIN ...语法,注意一个计划游标会包含多行:最后一行是汇总节点的查询,其它是映射节点的。
EXPLAIN SELECT name FROM Person WHERE age = 26;
执行计划本身是由H2生成的,这里有详细描述。
# 5.2.使用H2调试控制台
当用Ignite进行开发时,有时对于检查表和索引是否正确或者运行在嵌入节点内部的H2数据库中的本地查询是非常有用的,为此Ignite提供了启动H2控制台的功能。要启用该功能,在启动节点时要将IGNITE_H2_DEBUG_CONSOLE系统属性或者环境变量设置为true。然后就可以在浏览器中打开控制台,可能需要点击控制台中的刷新按钮,因为有可能控制台在数据库对象初始化之前打开。

# 5.3.SQL性能和可用性考量
当执行SQL查询时有一些常见的陷阱需要注意:
- 如果查询使用了操作符OR那么它可能不是以期望的方式使用索引。比如对于查询:
select name from Person where sex='M' and (age = 20 or age = 30),会使用sex字段上的索引而不是age上的索引,虽然后者选择性更强。要解决这个问题需要用UNION ALL重写这个查询(注意没有ALL的UNION会返回去重的行,这会改变查询的语意而且引入了额外的性能开销),比如:select name from Person where sex='M' and age = 20 UNION ALL select name from Person where sex='M' and age = 30; - 如果查询使用了操作符IN,那么会有两个问题:首先无法提供可变参数列表,这意味着需要在查询中指定明确的列表,比如
where id in (?, ?, ?),但是不能写where id in ?然后传入一个数组或者集合。第二,查询无法使用索引,要解决这两个问题需要像这样重写查询:select p.name from Person p join table(id bigint = ?) i on p.id = i.id,这里可以提供一个任意长度的对象数组(Object[])作为参数,然后会在字段id上使用索引。注意基本类型数组(比如int[],long[]等)无法使用这个语法,但是可以使用基本类型的包装器。
示例:
new SqlFieldsQuery(
"select * from Person p join table(id bigint = ?) i on p.id = i.id").setArgs(new Object[]{ new Integer[] {2, 3, 4} }))
它会被转换为下面的SQL:
select * from "cache-name".Person p join table(id bigint = (2,3,4)) i on p.id = i.id
# 5.4.结果集延迟加载
Ignite默认会试图将所有结果集加载到内存然后将其发送给查询发起方(通常为应用客户端),这个方式在查询结果集不太大时提供了比较好的性能。
但是,如果相对于可用内存来说结果集过大,就是导致长期的GC暂停甚至内存溢出。
为了降低内存的消耗,以适度降低性能为代价,可以对结果集进行延迟加载和处理,这个可以通过给JDBC或者ODBC连接串传递lazy参数,或者对于Java、.NET和C++来说,使用一个简单的方法也可以实现:
Java:
SqlFieldsQuery query = new SqlFieldsQuery("SELECT * FROM Person WHERE id > 10");
// Result set will be loaded lazily.
query.setLazy(true);
JDBC连接串
jdbc:ignite:thin://192.168.0.15?lazy=true
# 5.5.查询并行度
SQL查询在每个涉及的节点上,默认是以单线程模式执行的,这种方式对于使用索引返回一个小的结果集的查询是一种优化,比如:
select * from Person where p.id = ?
某些查询以多线程模式执行会更好,这个和带有表扫描以及聚合的查询有关,这在OLAP的场景中比较常见,比如:
select SUM(salary) from Person
通过CacheConfiguration.queryParallelism属性可以配置查询的并行度,这个参数定义了在单一节点中执行查询时使用的线程数。使用CREATE TABLE生成SQL模式以及底层缓存时,使用一个已配置好的CacheConfiguration模板,也可以对这个参数进行调整。
如果查询包含JOIN,那么所有相关的缓存都应该有相同的并行度配置。
注意 当前,这个属性影响特定缓存上的所有查询,可以加速很重的OLAP查询,但是会减慢其它的简单查询,这个行为在未来的版本中会改进。
# 5.6.索引提示
当明确知道对于查询来说一个索引比另一个更合适时,索引提示就会非常有用,它也有助于指导查询优化器来选择一个更高效的执行计划。在Ignite中要进行这个优化,可以使用USE INDEX(indexA,...,indexN)语句,它会告诉Ignite对于查询的执行只会使用给定名字的索引之一。
下面是一个示例:
SELECT * FROM Person USE INDEX(index_age)
WHERE salary > 150000 AND age < 35;
# 5.7.查询执行流程优化
对于一个SELECT语句,SQL引擎会自动地使用条件段中的主键以及关联键对查询进行优化,比如下面的查询:
SELECT * FROM Person p WHERE p.id = ?
Ignite会计算p.id所属的分区,然后只在该分区所在的节点中执行查询。
# 5.8.更新时忽略汇总
当Ignite执行DML操作时,首先,它会获取所有受影响的中间行用于查询发起方的分析(也被称为汇总),然后会准备更新值的批处理,最后发送给远程节点。
如果一个DML操作需要移动大量数据,则这个方式可能导致性能问题以及网络的堵塞。
使用这个标志可以作为一个提示,它使Ignite会在对应的远程节点上进行中间行的分析和更新,JDBC和ODBC都支持这个提示:
JDBC
jdbc:ignite:thin://192.168.0.15/skipReducerOnUpdate=true
# 5.9.SQL堆内行缓存
Ignite的固化内存在Java堆外存储数据和索引,这意味着每次数据访问,就会有一部分数据从堆外数据区复制到堆内,然后可能被反序列化并且在应用或者服务端节点引用它期间,一直保持在堆内。
SQL堆内行缓存的目的就是在Java堆内存储热点数据(键-值对象),使反序列化和数据复制的资源消耗最小化,每个缓存的行都会指向堆外数据区的一个数据条目,并且在如下情况下会失效:
- 存储在堆外数据区的主条目被更新或者删除;
- 存储主条目的数据页面从内存中退出。
堆内行缓存是缓存级的(SQL表或者缓存的创建也可以使用CREATE TABLE语句,相关的参数可以通过缓存模板传递)。
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="person"/>
...
<property name="sqlOnheapCacheEnabled" value="true"/>
</bean>
如果开启了行缓存,通过分配更多的内存,对于部分SQL查询或者案例,可能提升2倍的性能,这是一种折衷。
SQL堆内行缓存大小 目前,该缓存没有限制,可以和堆外数据区一样,占用更多的内存,但是: 1.如果开启了堆内行缓存,需要配置JVM的最大堆大小为存储缓存的所有数据区的总大小; 2.调整JVM的垃圾回收。