# 工具和分析
# 1.SQL工具
Ignite的JDBC和ODBC驱动使得从SQL工具接入集群然后处理存储在其中的数据成为可能,需要做的仅仅是为SQL工具配置JDBC或者ODBC驱动。在本章节中会以DBeaver为例,一步步演示如何进行这些基本的配置。
# 1.1.安装和配置
DBeaver作为一个示例,是一个针对开发者和数据库管理员的免费开源的统一数据库工具,它支持包括Ignite在内的所有常见数据库。
Ignite有自己的JDBC驱动实现,DBeaver可以用其处理存储于分布式集群中的数据。
针对自己的操作系统下载和安装DBeaver,再下载最新版本的Ignite。
DBeaver安装完成之后,打开它然后选择Database->Driver Manager菜单项来配置Ignite JDBC驱动,使用Apache Ignite作为数据库/驱动名然后点击New按钮。
在下一页中输入必要的项目,如下所示:
Driver Name:自定义名字,可以简单地配置为Apache Ignite;Class Name:值为org.apache.ignite.IgniteJdbcThinDriver;URL Template:Ignite的JDBC连接串,作为入门来说可以为jdbc:ignite:thin://127.0.0.1/;Default Port:Ignite JDBC驱动默认使用10800,如果要修改端口号或者连接串,可以见前文描述;Libraries:点击Add file按钮,然后找到包含Ignite JDBC驱动的{apache-ignite-version}/libs/ignite-core-{version}.jar文件;
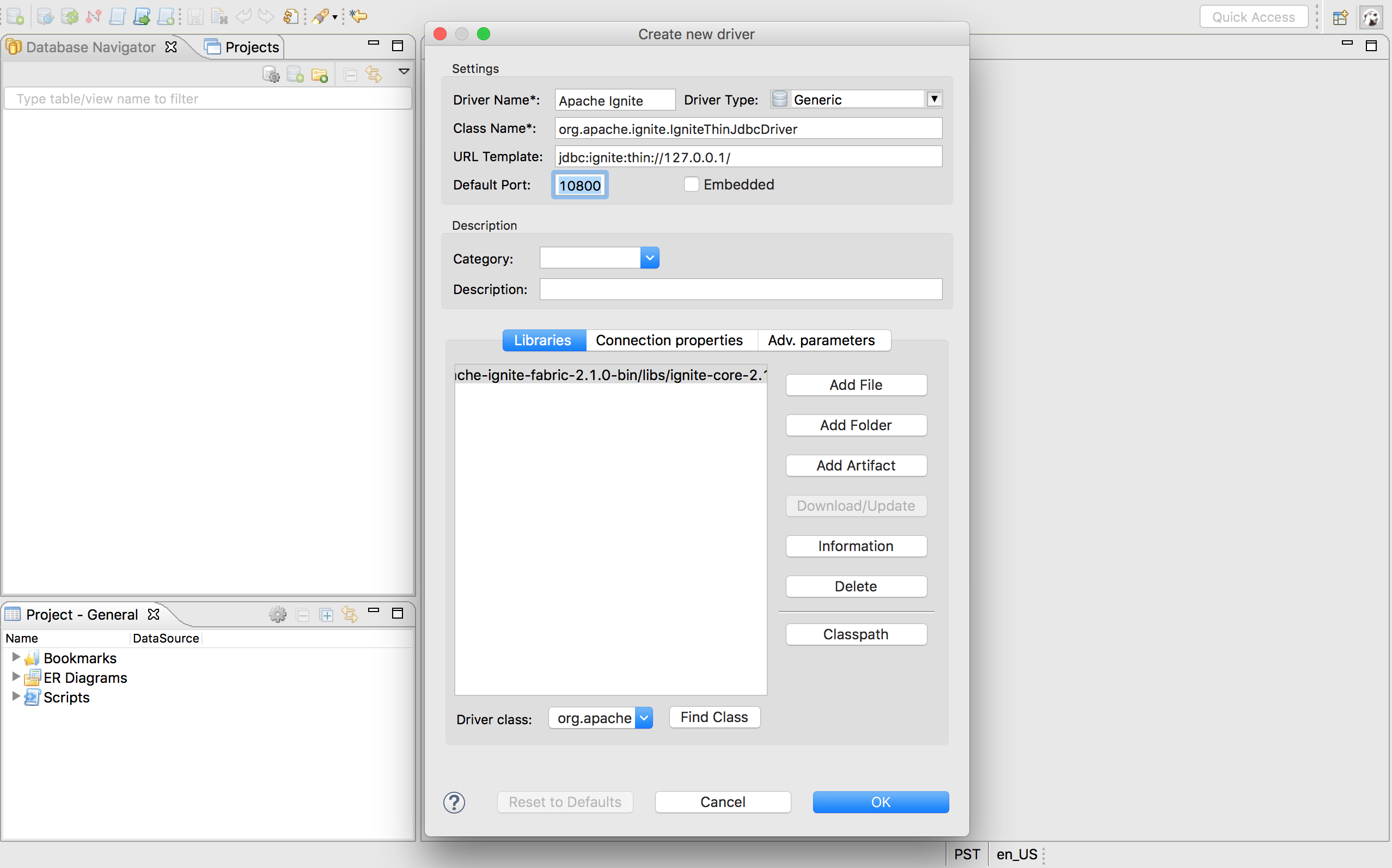
点击OK按钮后完成配置,然后关闭Driver Manager对话框,然后就可以在驱动列表中看到Apache Ignite:
# 1.2.接入集群
下一步就是启动Ignite集群然后通过DBeaver接入。
打开命令行工具然后定位到{apache-ignite-version}/bin,执行ignite.sh或者ignite.bat脚本:
Unix:
./ignite.sh
Windows:
ignite.bat
这个脚本会启动一个Ignite节点,使用同样的脚本可以启动很多的节点,节点启动之后会看到大致如下的输出:
[12:46:46] __________ ________________
[12:46:46] / _/ ___/ |/ / _/_ __/ __/
[12:46:46] _/ // (7 7 // / / / / _/
[12:46:46] /___/\___/_/|_/___/ /_/ /___/
[12:46:46]
[12:46:46] ver. 2.1.0#20170720-sha1:a6ca5c8a
[12:46:46] 2017 Copyright(C) Apache Software Foundation
[12:46:46]
[12:46:46] Ignite documentation: http://ignite.apache.org
[12:46:46]
[12:46:46] Quiet mode.
[12:46:46] ^-- Logging to file '/Users/dmagda/Downloads/apache-ignite-fabric-2.1.0-bin/work/log/ignite-20d0a1be.0.log'
[12:46:46] ^-- To see **FULL** console log here add -DIGNITE_QUIET=false or "-v" to ignite.{sh|bat}
[12:46:46]
[12:46:46] OS: Mac OS X 10.12.6 x86_64
[12:46:51] VM information: Java(TM) SE Runtime Environment 1.8.0_77-b03 Oracle Corporation Java HotSpot(TM) 64-Bit Server VM 25.77-b03
[12:46:51] Configured plugins:
[12:46:51] ^-- None
[12:46:58] Ignite node started OK (id=20d0a1be)
[12:47:03] Topology snapshot [ver=1, servers=1, clients=0, CPUs=4, heap=1.0GB]
切换到DBeaver然后选择Database->New Connection菜单项,在列表中找到Apache Ignite然后点击Next >按钮:
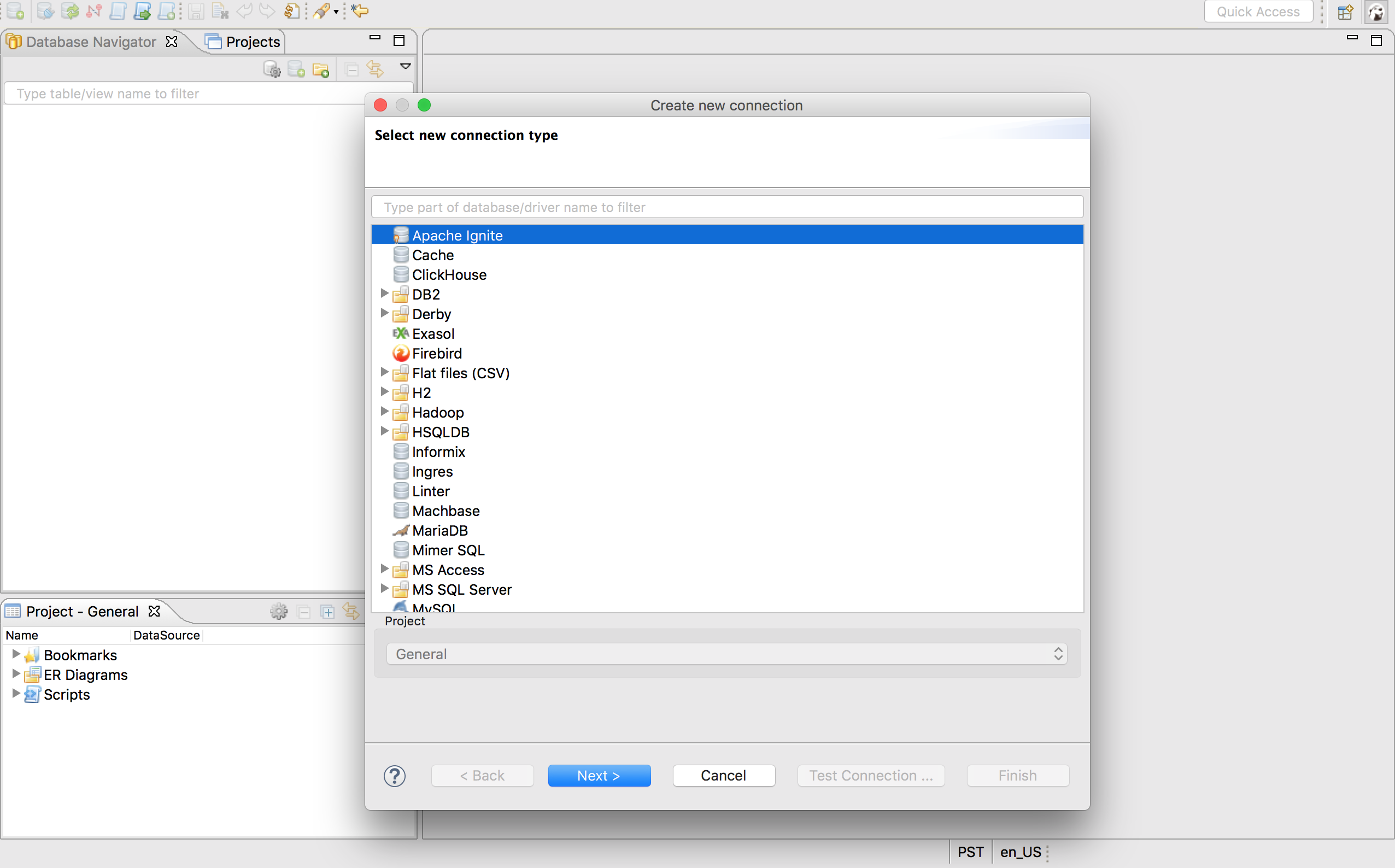
确保JDBC URL配置为前述的jdbc:ignite:thin://127.0.0.1/连接串,然后点击Test Connection ...按钮来验证DBeaver与本地运行的Ignite集群之间的连接。
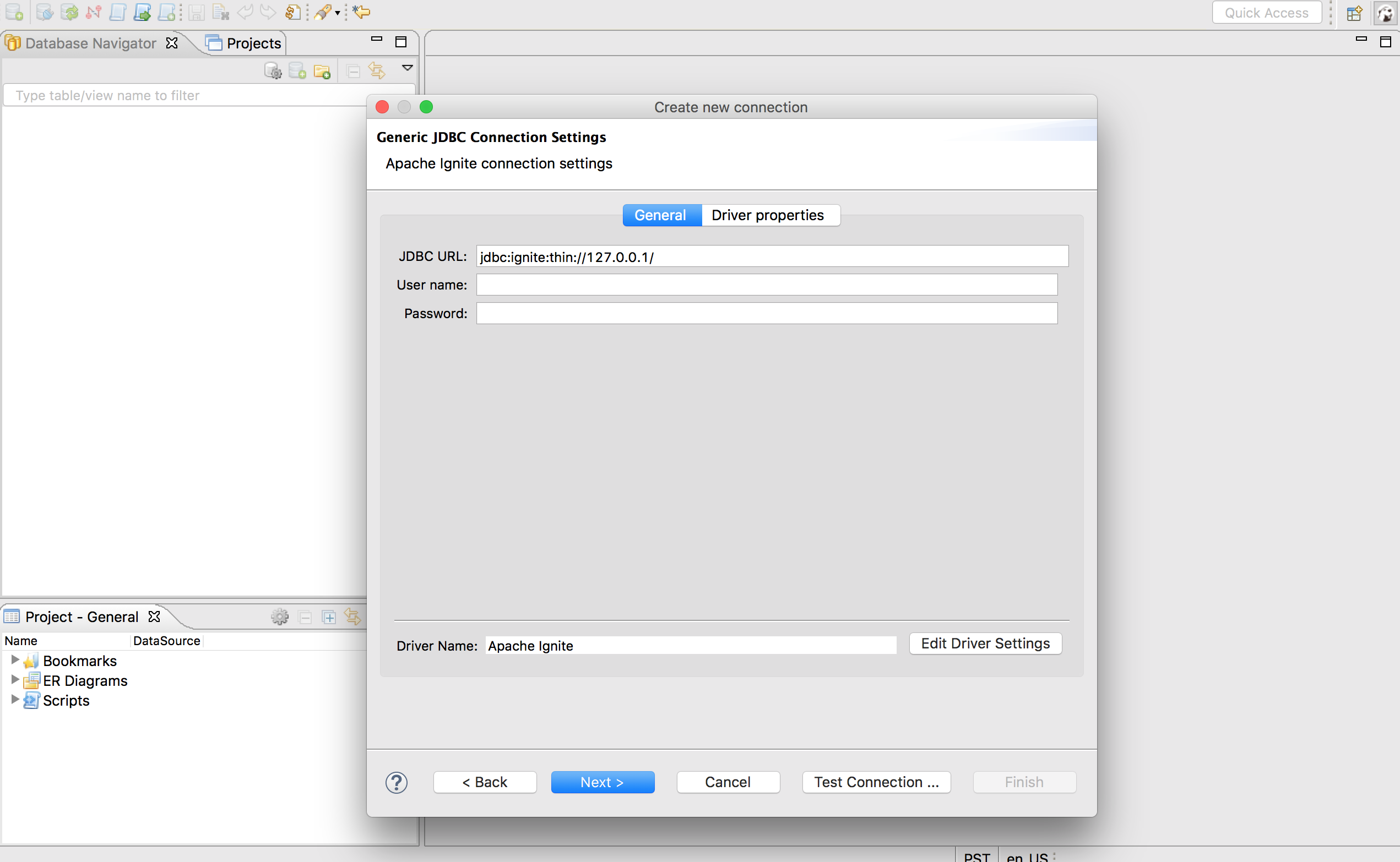
如果在JDBC URL字段中没看到连接串,选择
< Back按钮然后再选一次Next >。
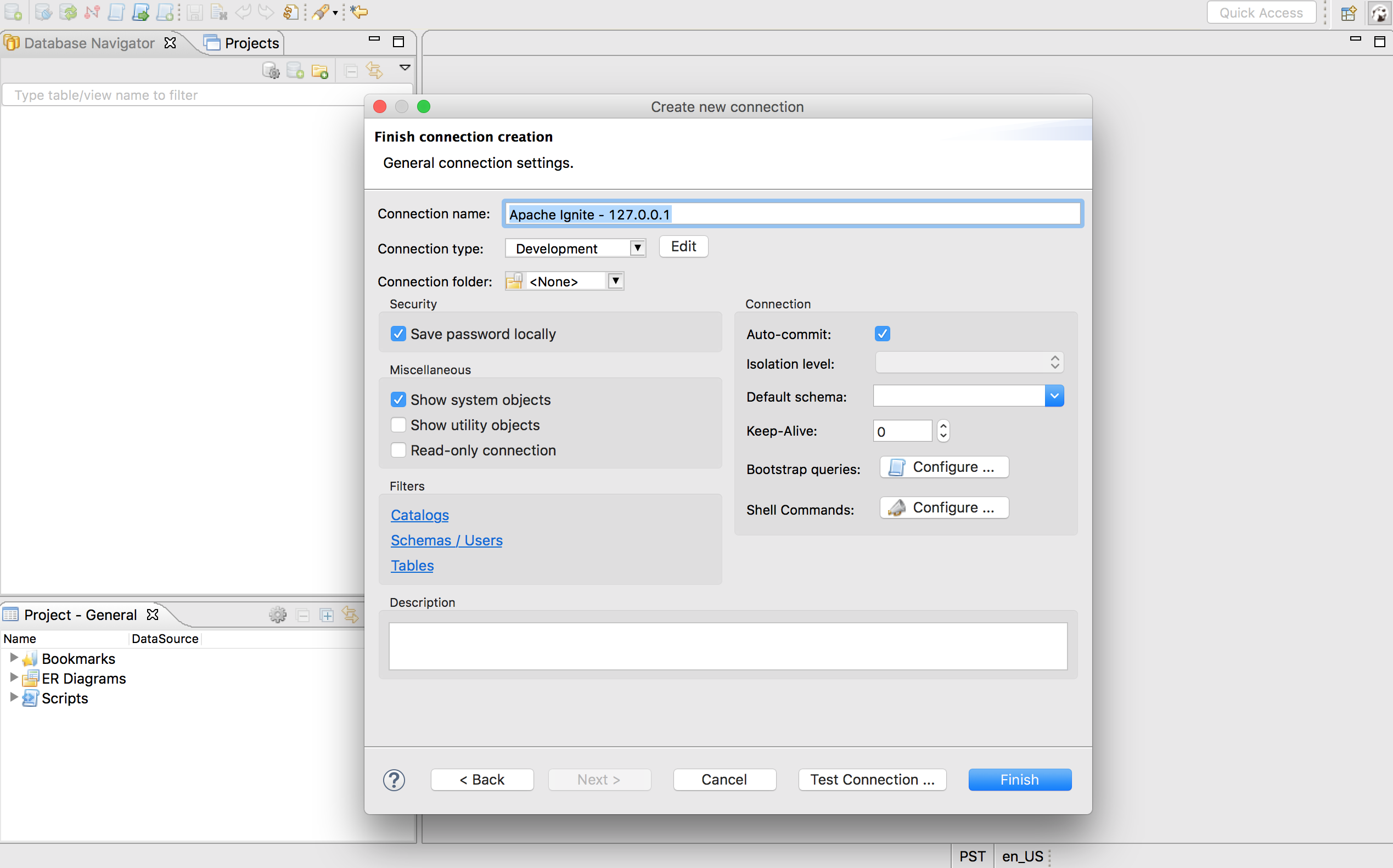
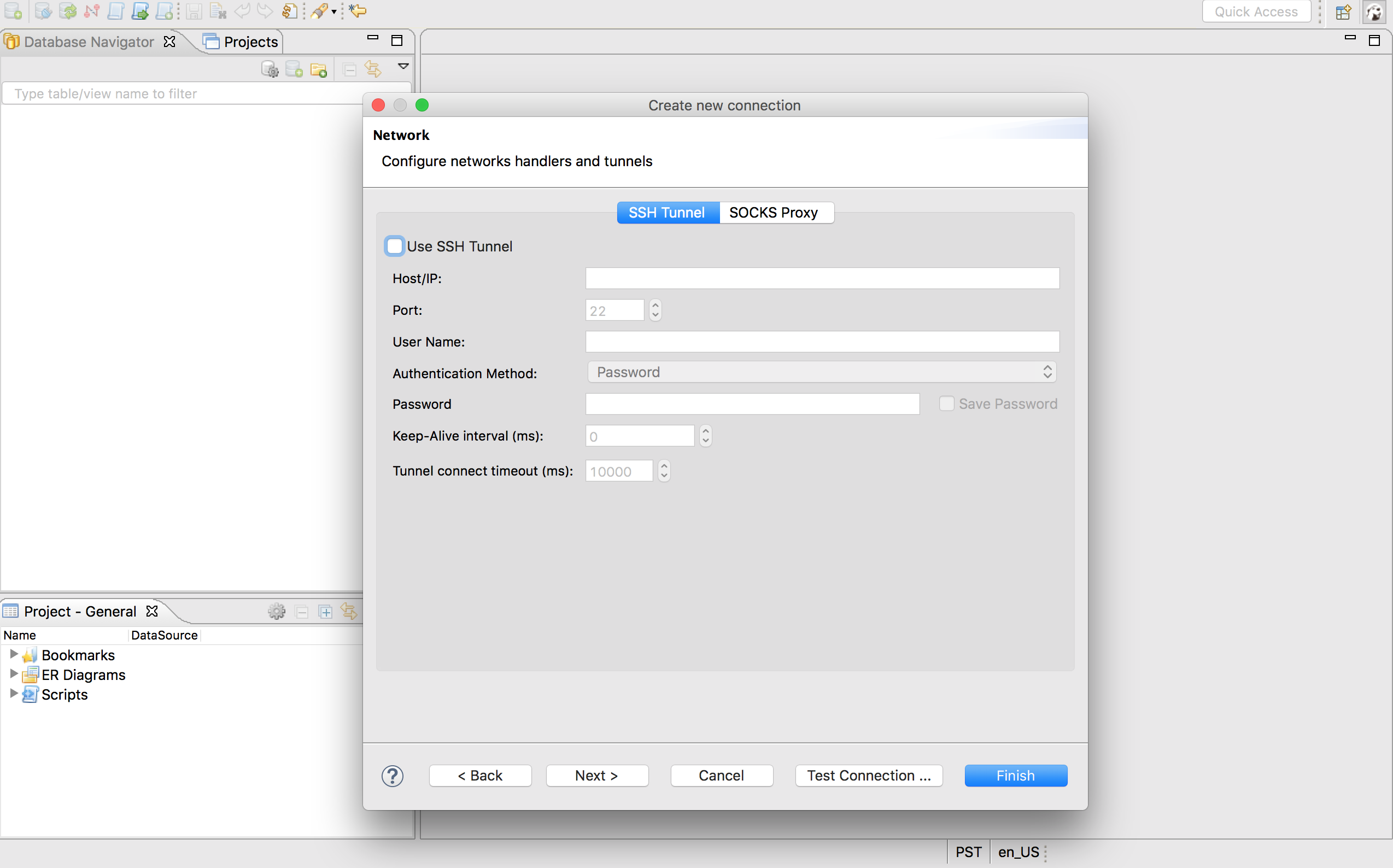
测试通过之后点击Next >按钮就会跳转到Network界面:
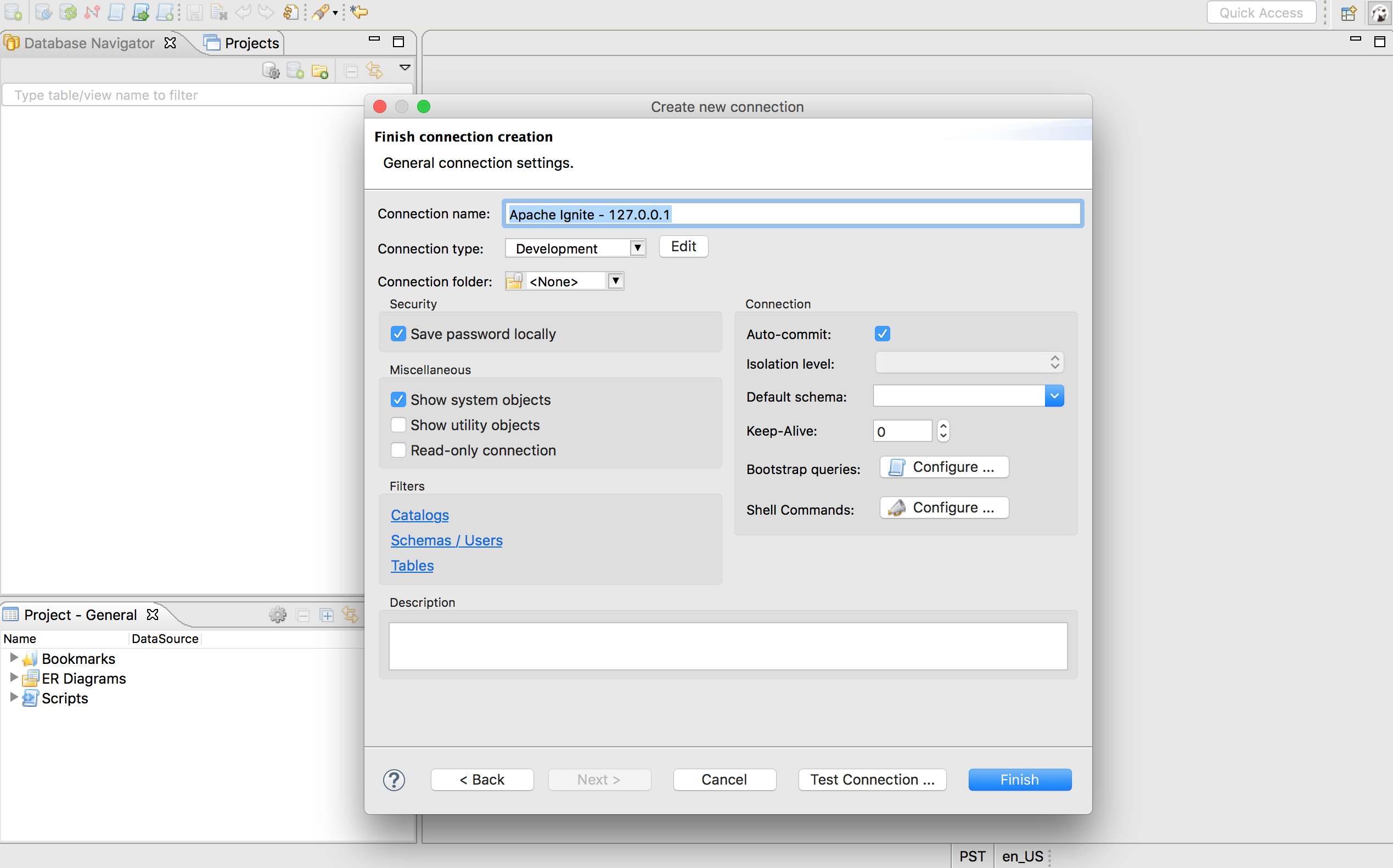
在最后一个界面中确认信息之后点击Finish按钮:
Database Navigator选项卡中就会出现Apache Ignite:
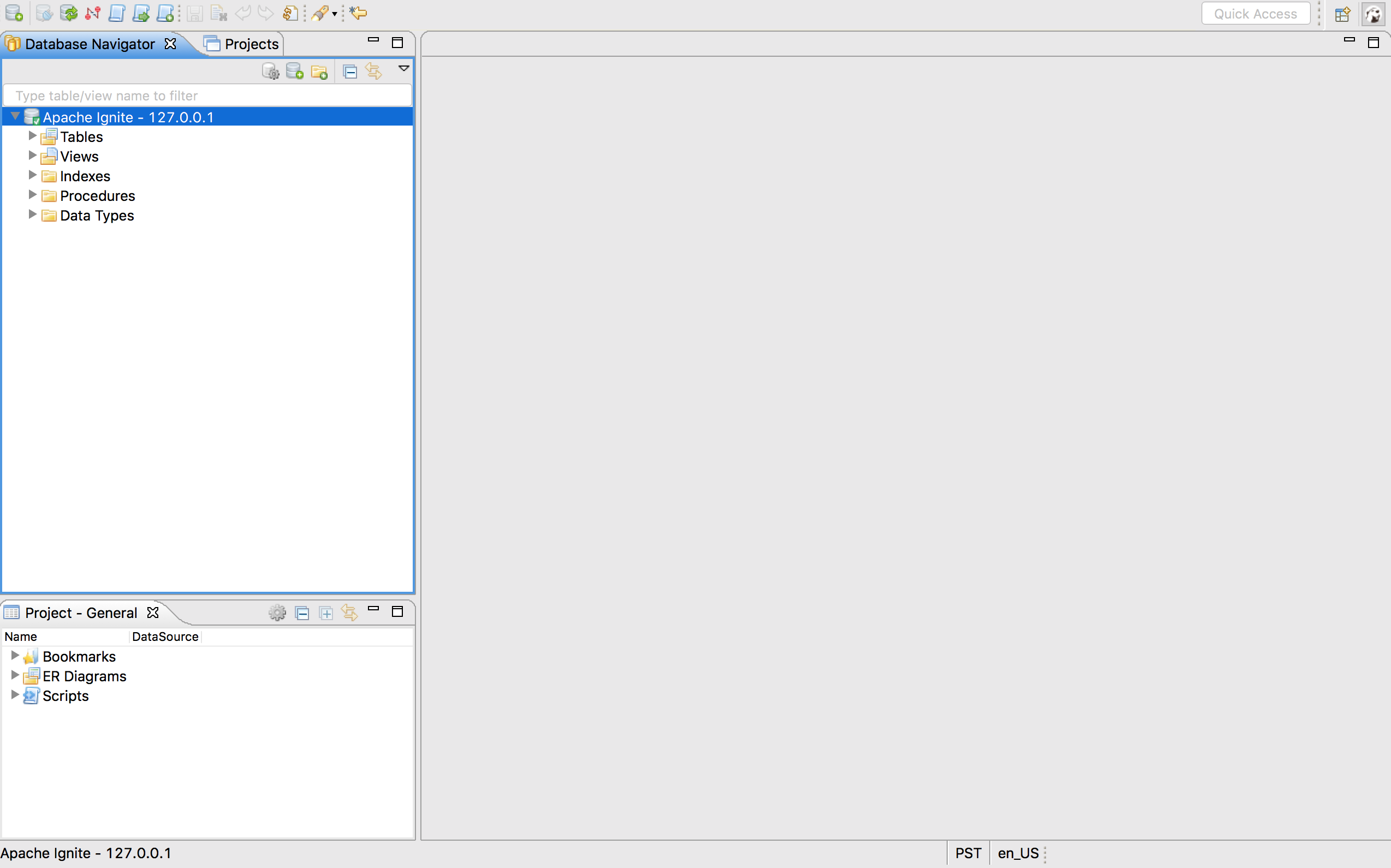
不支持数据库元数据的错误 如果Ignite的版本是2.0或者2.1,在展开
Tables、Views或者其它菜单项时,会得到SQL Error: Database metadata not supported by driver这样的错误。Ignite的下一个版本就会支持元数据,但是缺少这个特性并不影响下面会看到的所有使用场景。
# 1.3.数据查询和分析
下一步会定义一个SQL模式,通过DBeaver插入以及查询部分数据,再挑选一些支持的DDL和DML语句。
再一次确保工具已经接入集群,点击右键菜单然后打开SQL Editor:
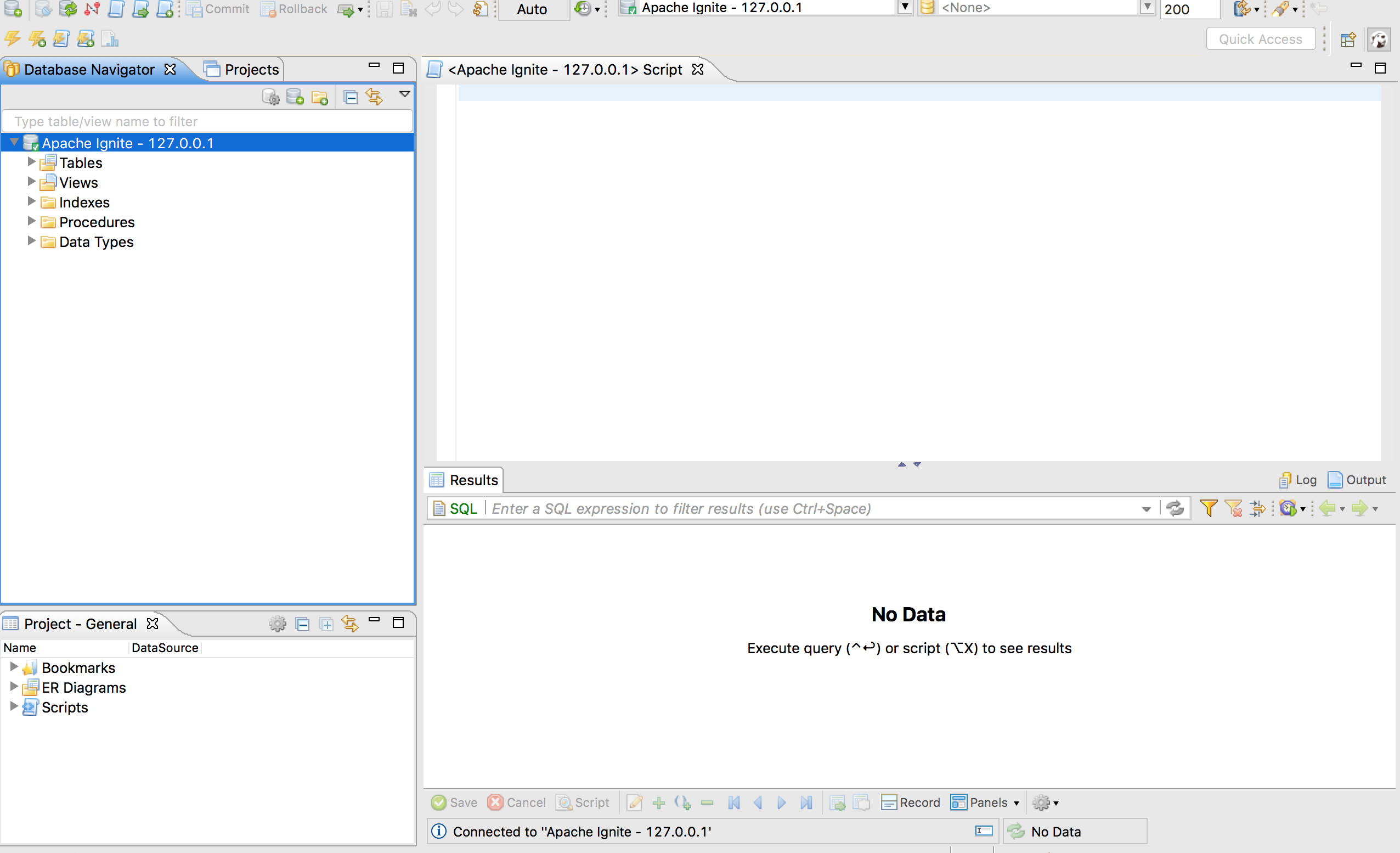
表和索引的创建
使用下面的SQL语句创建City和Person表:
CREATE TABLE City (
id LONG PRIMARY KEY, name VARCHAR)
WITH "template=replicated"
CREATE TABLE Person (
id LONG, name VARCHAR, city_id LONG, PRIMARY KEY (id, city_id))
WITH "backups=1, affinityKey=city_id"
将语句粘贴到DBeaver的脚本窗口然后点击Execute SQL Statement菜单项:
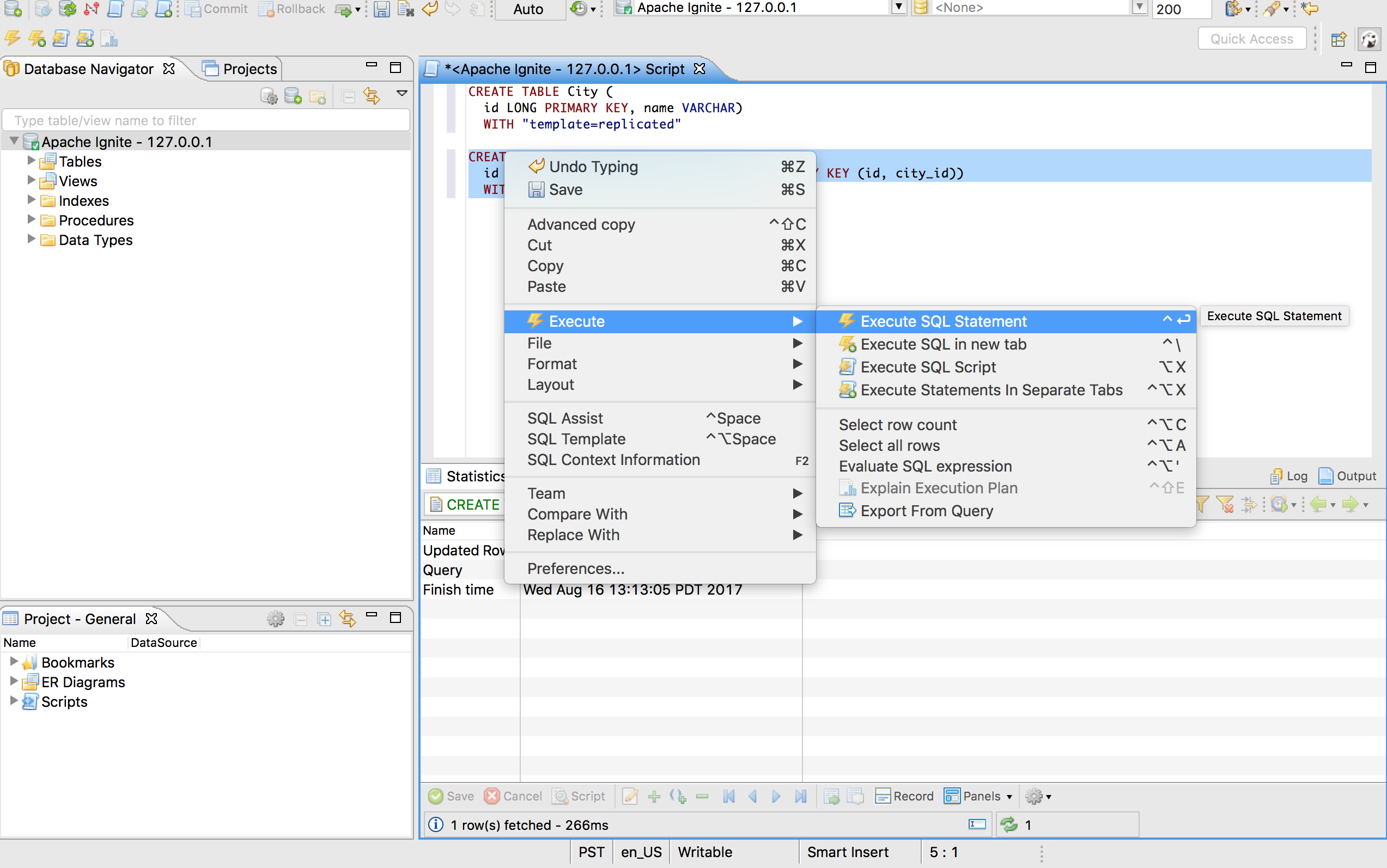
创建完表之后,像下面这样定义一些索引:
CREATE INDEX idx_city_name ON City (name)
CREATE INDEX idx_person_name ON Person (name)
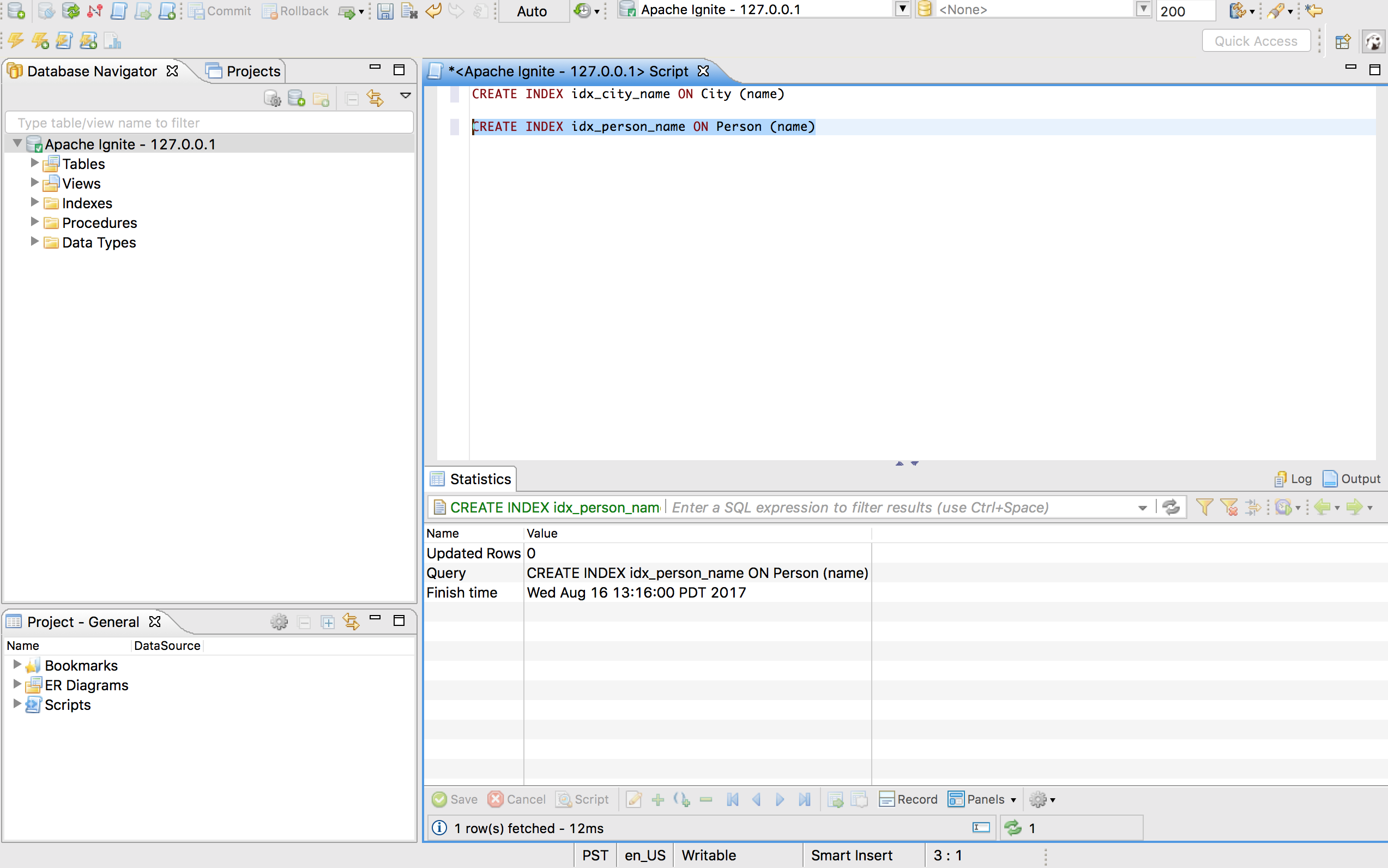
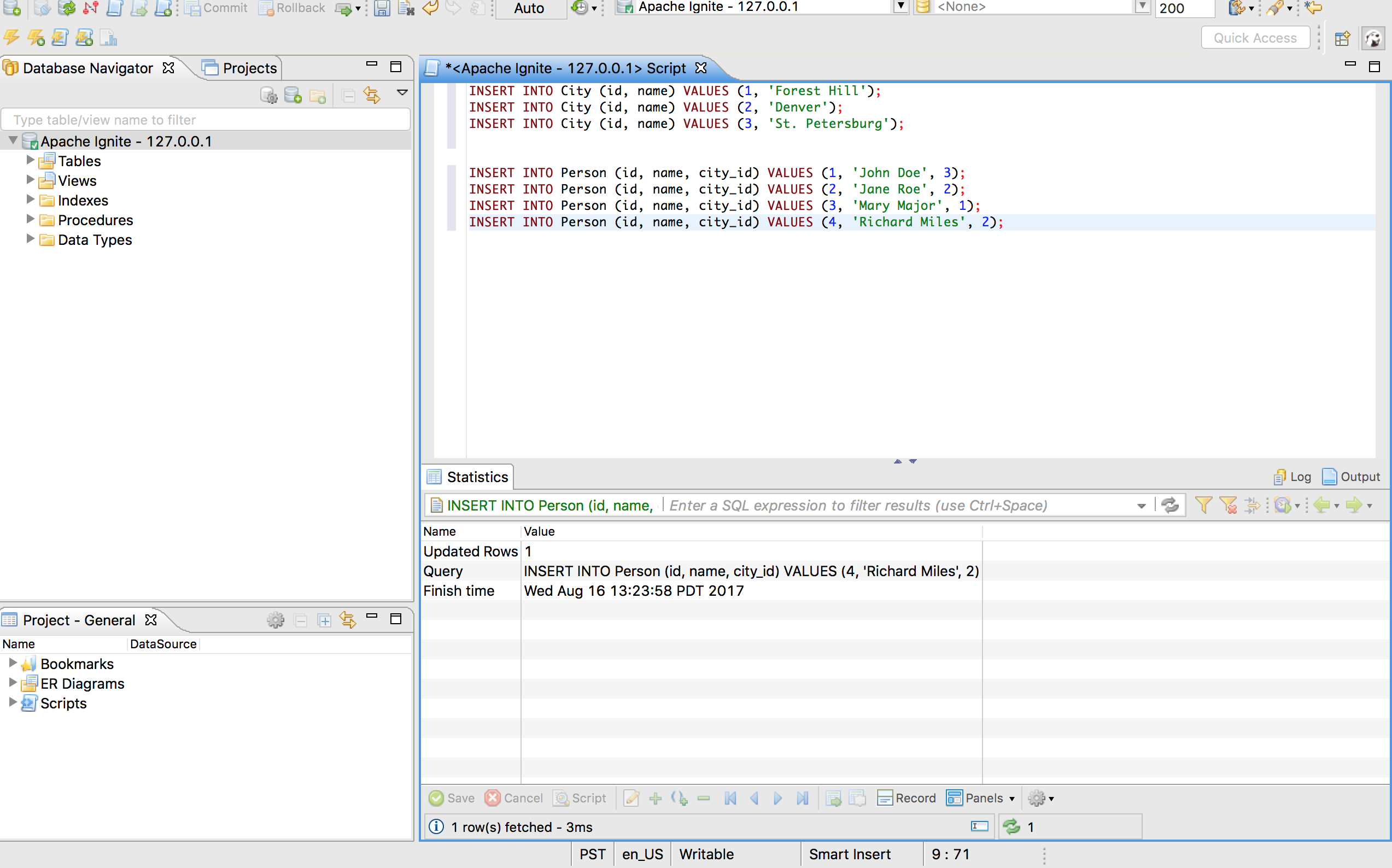
插入数据
通过如下语句往集群中插入一些记录:
INSERT INTO City (id, name) VALUES (1, 'Forest Hill');
INSERT INTO City (id, name) VALUES (2, 'Denver');
INSERT INTO City (id, name) VALUES (3, 'St. Petersburg');
INSERT INTO Person (id, name, city_id) VALUES (1, 'John Doe', 3);
INSERT INTO Person (id, name, city_id) VALUES (2, 'Jane Roe', 2);
INSERT INTO Person (id, name, city_id) VALUES (3, 'Mary Major', 1);
INSERT INTO Person (id, name, city_id) VALUES (4, 'Richard Miles', 2);
下一步,需要单独(一个一个)地执行所有的语句,在未来的版本中会支持批量插入:
查询数据
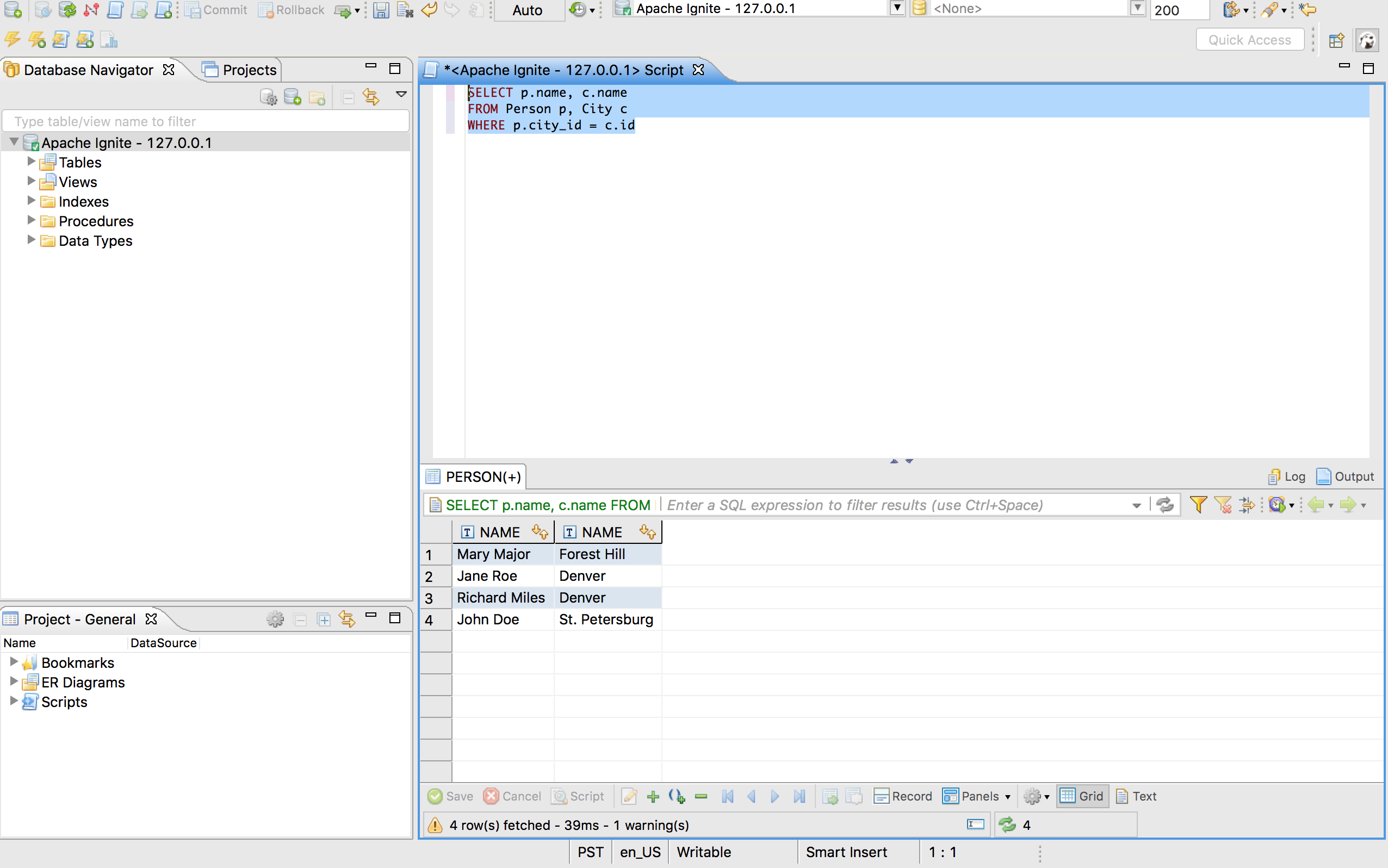
装载数据之后,就可以执行查询了,下面是查询数据的示例,包括两个表之间的关联:
SELECT p.name, c.name
FROM Person p, City c
WHERE p.city_id = c.id
# 2.SQL命令行
Ignite提供了一个SQLLine工具,它是一个接入关系数据库然后执行SQL命令的基于命令行的工具,它是Ignite中用于SQL连接的默认命令行工具。本章节会描述如何用SQLLine接入Ignite集群,以及Ignite支持的各种SQLLine命令。
# 2.1.接入集群
在IGNITE_HOME/bin目录中,执行sqlline.sh -u jdbc:ignite:thin:[host]命令就可以使用SQLLine接入集群,注意要将[host]替换为实际的值,比如:
.sh:
./sqlline.sh --verbose=true -u jdbc:ignite:thin://127.0.0.1/
.bat:
sqlline.bat --verbose=true -u jdbc:ignite:thin://127.0.0.1/
输入./sqlline.sh -h或者./sqlline.sh --help可以看到可用的各种选项。
使用认证
如果集群打开了认证,那么在IGNITE_HOME/bin目录中,通过运行jdbc:ignite:thin://[address]:[port];user=[username];password=[password]命令SQLLine才可以接入集群。注意要将[address],[port],[username]和`[password]替换为实际值,比如:
.sh:
./sqlline.sh --verbose=true -u "jdbc:ignite:thin://127.0.0.1:10800;user=ignite;password=ignite"
.bat:
sqlline.bat --verbose=true -u "jdbc:ignite:thin://127.0.0.1:10800;user=ignite;password=ignite"
通过bash接入时JDBC URL要加引号 当在bash环境中接入时连接的URL一定要加
" ",比如:"jdbc:ignite:thin://[address]:[port];user=[username];password=[password]"。
# 2.2.命令
下面是Ignite支持的SQLLine命令列表:
| 命令 | 描述 |
|---|---|
!all | 在当前的所有连接中执行指定的SQL |
!batch | 开始执行一批SQL语句 |
!brief | 启动简易输出模式 |
!closeall | 关闭所有目前已打开的连接 |
!columns | 显示表中的列 |
!connect | 接入数据库 |
!dbinfo | 列出当前连接的元数据信息 |
!dropall | 删除数据库中的所有表 |
!go | 转换到另一个活动连接 |
!help | 显示帮助信息 |
!history | 显示命令历史 |
!indexes | 显示表的索引 |
!list | 显示所有的活动连接 |
!manual | 显示SQLLine手册 |
!metadata | 调用任意的元数据命令 |
!nickname | 为连接命名(更新命令提示) |
!outputformat | 改变显示SQL结果的方法 |
!primarykeys | 显示表的主键列 |
!properties | 使用指定的属性文件接入数据库 |
!quit | 退出SQLLine |
!reconnect | 重新连接当前的数据库 |
!record | 开始记录SQL命令的所有输出 |
!run | 执行一个命令脚本 |
!script | 将已执行的命令保存到一个文件 |
!sql | 在数据库上执行一个SQL |
!tables | 列出数据库中的所有表 |
!verbose | 启动详细输出模式 |
上面的列表可能不完整,还可能有其它Ignite支持的SQLLine命令。想看完整的SQLLine命令列表,看这里。
# 2.3.示例
接入集群后,就可以执行SQL语句和SQLLine命令,比如:
创建模式:
0: jdbc:ignite:thin://127.0.0.1/> CREATE TABLE City (id LONG PRIMARY KEY, name VARCHAR) WITH "template=replicated";
No rows affected (0.301 seconds)
0: jdbc:ignite:thin://127.0.0.1/> CREATE TABLE Person (id LONG, name VARCHAR, city_id LONG, PRIMARY KEY (id, city_id))WITH "backups=1, affinityKey=city_id";
No rows affected (0.078 seconds)
0: jdbc:ignite:thin://127.0.0.1/> !tables
+-----------+--------------+--------------+-------------+-------------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS |
+-----------+--------------+--------------+-------------+-------------+
| | PUBLIC | CITY | TABLE | |
| | PUBLIC | PERSON | TABLE | |
+-----------+--------------+--------------+-------------+-------------+
定义索引:
0: jdbc:ignite:thin://127.0.0.1/> CREATE INDEX idx_city_name ON City (name);
No rows affected (0.039 seconds)
0: jdbc:ignite:thin://127.0.0.1/> CREATE INDEX idx_person_name ON Person (name);
No rows affected (0.013 seconds)
0: jdbc:ignite:thin://127.0.0.1/> !indexes
+-----------+--------------+--------------+-------------+-----------------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | NON_UNIQUE | INDEX_QUALIFIER |
+-----------+--------------+--------------+-------------+-----------------+
| | PUBLIC | CITY | true | |
| | PUBLIC | PERSON | true | |
+-----------+--------------+--------------+-------------+-----------------+
# 3.Tableau
# 3.1.概述
Tableau是一个聚焦于商务智能领域的交互式数据可视化工具。它使用ODBC API接入各种数据库和数据平台,然后分析里面的数据。
Ignite有自己的ODBC实现,这样就使从Tableau端接入Ignite成为可能,并且可以分析存储于分布式Ignite集群中的数据。
# 3.2.安装和配置
要从Tableau接入Ignite,需要进行如下操作:
- 下载并且安转Tableau桌面版,可以在其产品主页查看官方文档;
- 在Windows或者基于Unix的操作系统上安装Ignite的ODBC驱动;
- 最后,通过DSN配置驱动,Tableau会通过DSN配置接入;
- ODBC驱动通过一个叫做
ODBC processor的协议与Ignite集群通信,一定要确保这个组件在集群端已经启用。
上述步骤完成后,就可以接入集群然后分析数据了。
# 3.3.接入集群
- 启动Tableau应用,然后在
Connect->To a Server->More...窗口中找到Other Databases (ODBC)配置;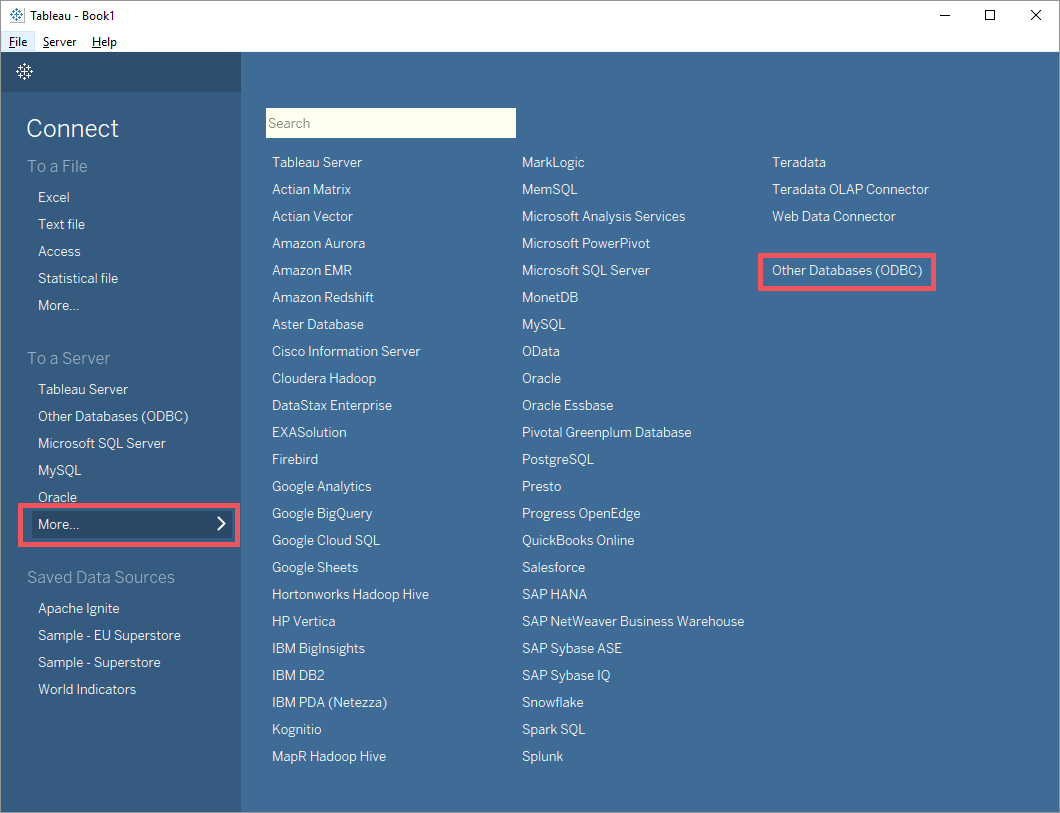
- 点击
Edit connection链接;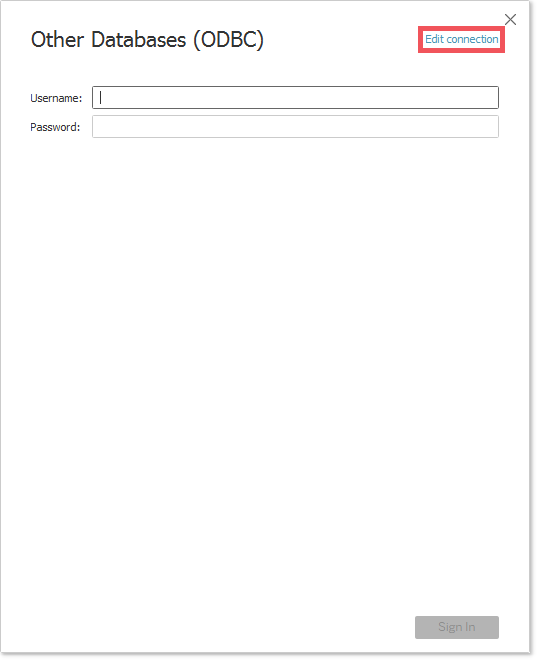
- 配置之前设定的
DSN属性值,下面的示例中为:LocalApacheIgniteDSN,做完之后,点击Connect按钮;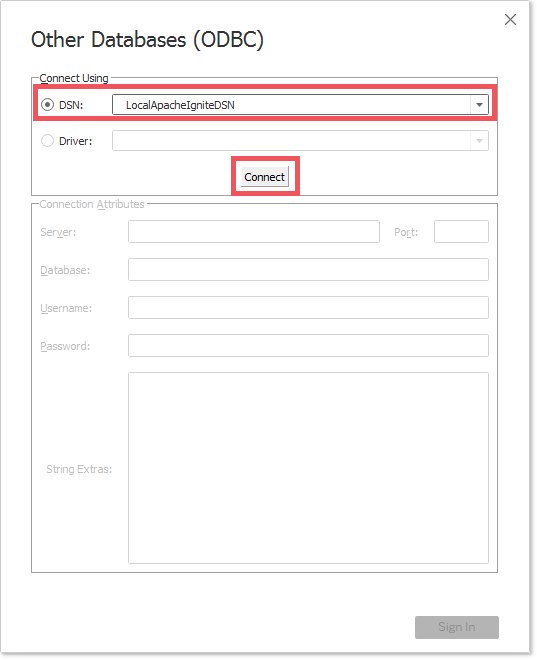
- Tableau会试图验证这个连接,如果验证通过,
Sign In按钮以及其它的与连接有关的字段就会变为可用状态,点击Sign In就会完成连接过程;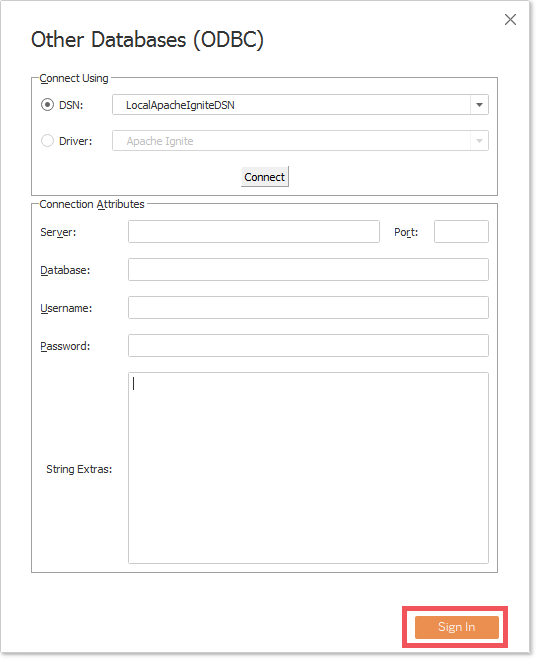
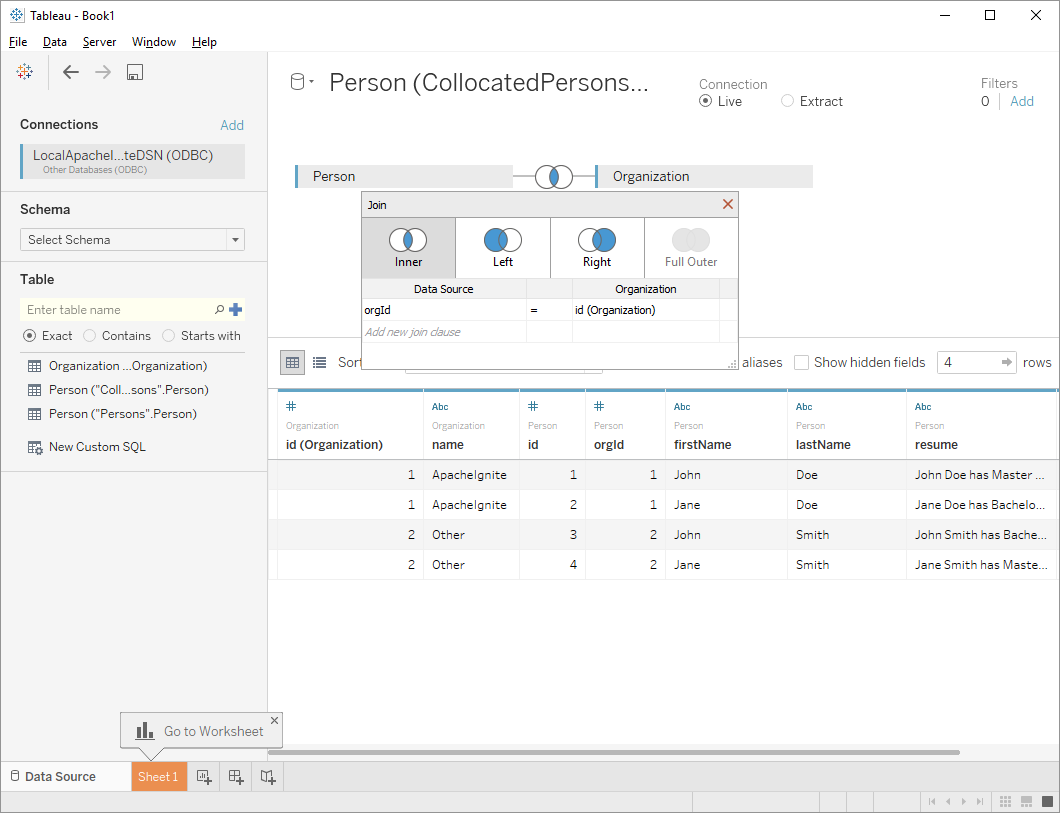
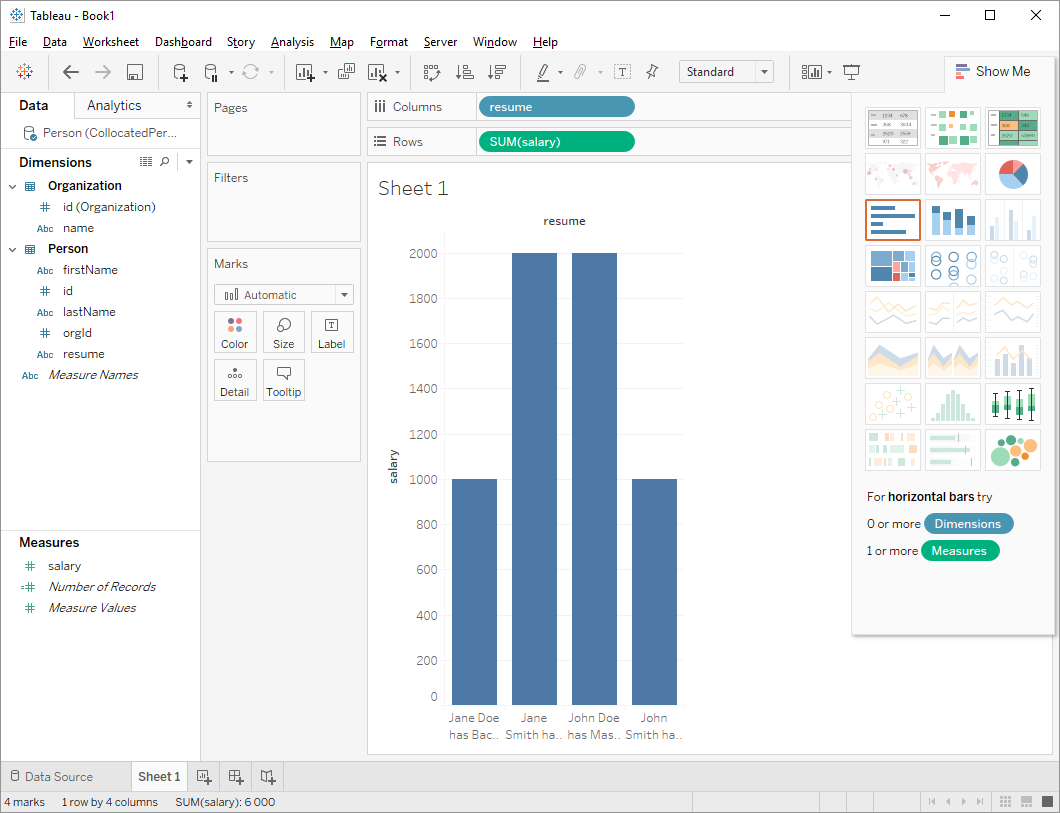
# 3.4.数据查询和分析
成功建立Ignite和Tableau之间的连接之后,就可以通过Tableau支持的各种方式对数据进行查询和分析,通过官方文档可以了解更多的细节。
# 4.Pentaho
# 4.1.概述
Pentaho是一个全面的平台,它可以非常容易地对数据进行抽取、转换、可视化和分析。Pentaho数据集成采用Java数据库连接(JDBC)API接入数据库。
Ignite有自己的JDBC驱动,这样就使得通过Pentaho平台接入Ignite成为可能,然后就可以分析分布式Ignite集群中的数据了。
# 4.2.安装和配置
- 下载并安装Pentaho平台,具体可以参考官方的Pentaho文档;
- 安装完成之后,需要使用相关的工具安装Ignite的JDBC驱动,怎么做呢,下载Ignite然后找到
{apache-ignite}/libs/ignite-core-{version}.jar,然后将其复制到{pentaho}/jdbc-distribution目录; - 打开一个命令行工具,切换到
{pentaho}/jdbc-distribution目录然后执行脚本:./distribute-files.sh ignite-core-{version}.jar。
# 4.3.JDBC驱动配置
下一步是配置JDBC驱动然后接入集群,下面做的都是必要的,JDBC Thin模式驱动有更多的细节信息。
- 打开命令行工具,切换到
{pentaho}/design-tools/data-integration目录,然后使用./spoon.sh脚本启动Pentaho; - 出现下面的界面之后,点击
File菜单然后创建一个新的转换:New->Transformation;
![]()
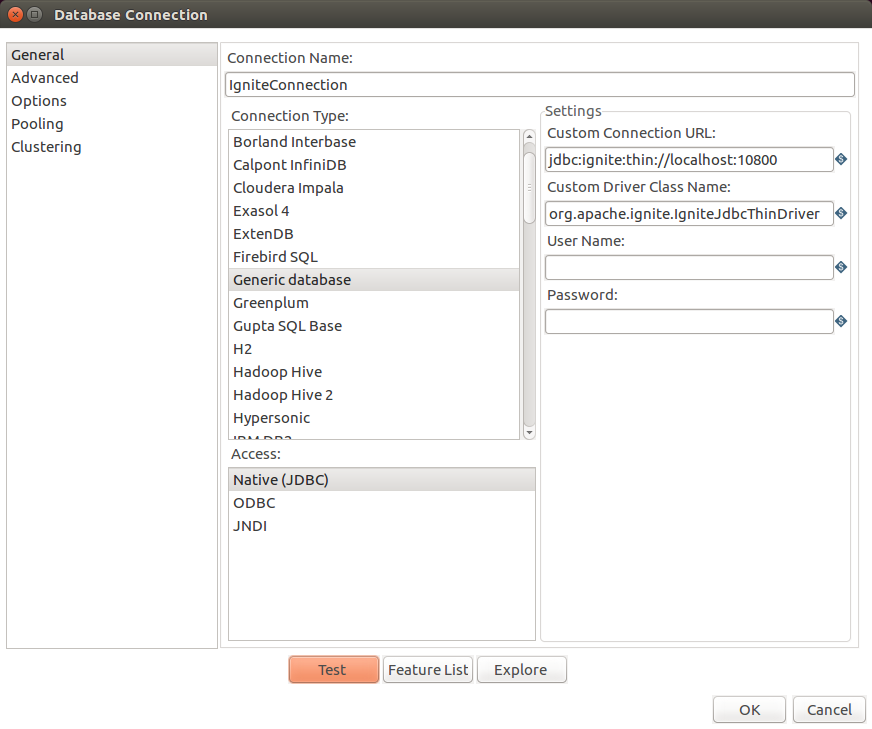
- 在Pentaho的界面中,填入下面的参数就可以创建一个新的数据库连接:
| Pentaho属性名 | 值 |
|---|---|
Connection Name | 比如IgniteConnection这样的自定义名字 |
Connection Type | 选择Generic database选项 |
Access | 选择Native (JDBC) |
Custom Connection URL | jdbc:ignite:thin://localhost:10800,其中端口和地址可以根据实际进行调整 |
Custom Driver Class Name | org.apache.ignite.IgniteJdbcThinDriver |
- 点击
Test按钮,对连接进行测试
# 4.4.数据的查询和分析
Ignite和Pentaho之间建立连接之后,就可以通过Pentaho支持的各种方式对数据进行查询、转换和分析了,更多的细节,可以查看Pentaho的官方文档。
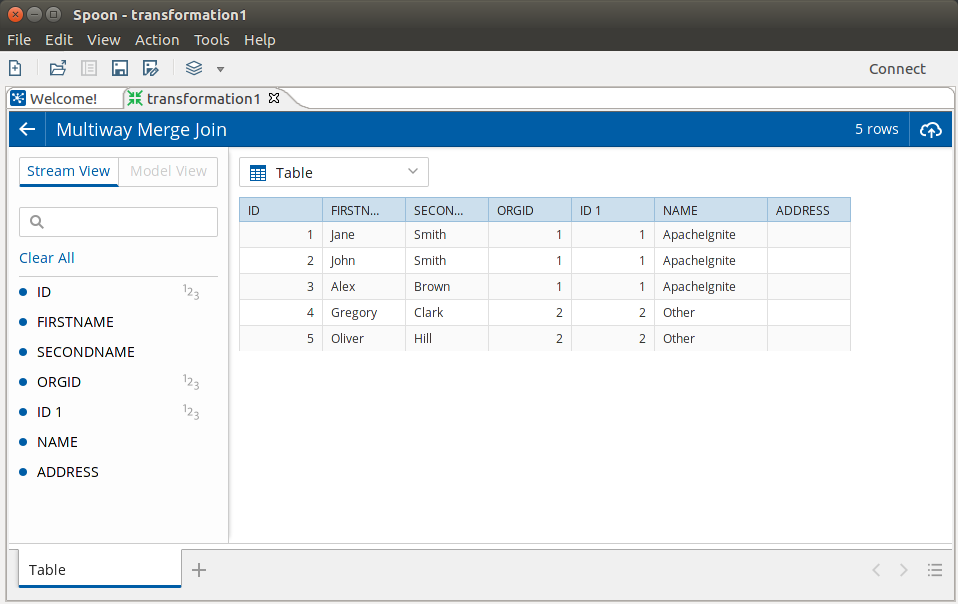
# 5.Apache Zeppelin
# 5.1.概述
Apache Zeppelin,是一个支持交互式数据分析的基于Web的笔记本,它可以用SQL,Scala以及其它的工具来生成漂亮的数据驱动的,交互式以及可协同的文档。
Zeppelin通过Ignite的SQL解释器可以从缓存中获得分布式的数据,此外,当SQL无法满足需求时Ignite解释器可以执行任何的Scala代码。比如,可以将数据注入缓存或者执行分布式计算。
# 5.2.Zeppelin安装和配置
为了通过Ignite解释器启动,需要用2个简单的步骤来安装Zeppelin:
- 克隆Zeppelin的Git仓库:
git clone https://github.com/apache/incubator-zeppelin.git
- 从源代码构建:
cd incubator-zeppelin
mvn clean install -Dignite-version=1.7.0 -DskipTests
用指定的Ignite版本构建Zeppelin 在构建Zeppelin时可以通过
ignite-version属性来指定Ignite的版本,需要使用1.7.0以及之后的版本。 添加Ignite解释器 Ignite和Ignite解释器默认已经在Zeppelin中配置了。另外也可以将如下的解释器类名加入相应的配置文件或者环境变量中(可以参照Zeppelin安装向导的配置章节)。
org.apache.zeppelin.ignite.IgniteInterpreterorg.apache.zeppelin.ignite.IgniteSqlInterpreter注意第一个解释器会成为默认值。
Zeppelin安装配置好了之后,可以用如下的命令来启动:
./bin/zeppelin-daemon.sh start
然后可以在浏览器中打开启动页(默认的启动页地址是http://localhost:8080)。
也可以参照Zeppelin安装文档.
# 5.3.配置Ignite解释器
点击Interpreter菜单项,这个页面包含了所有的已配置的解释器组的设置信息。向下滚动到Ignite章节然后点击Edit按钮可以修改属性的值,点击Save按钮可以保存配置的变更,不要忘了配置变更后重启解释器。
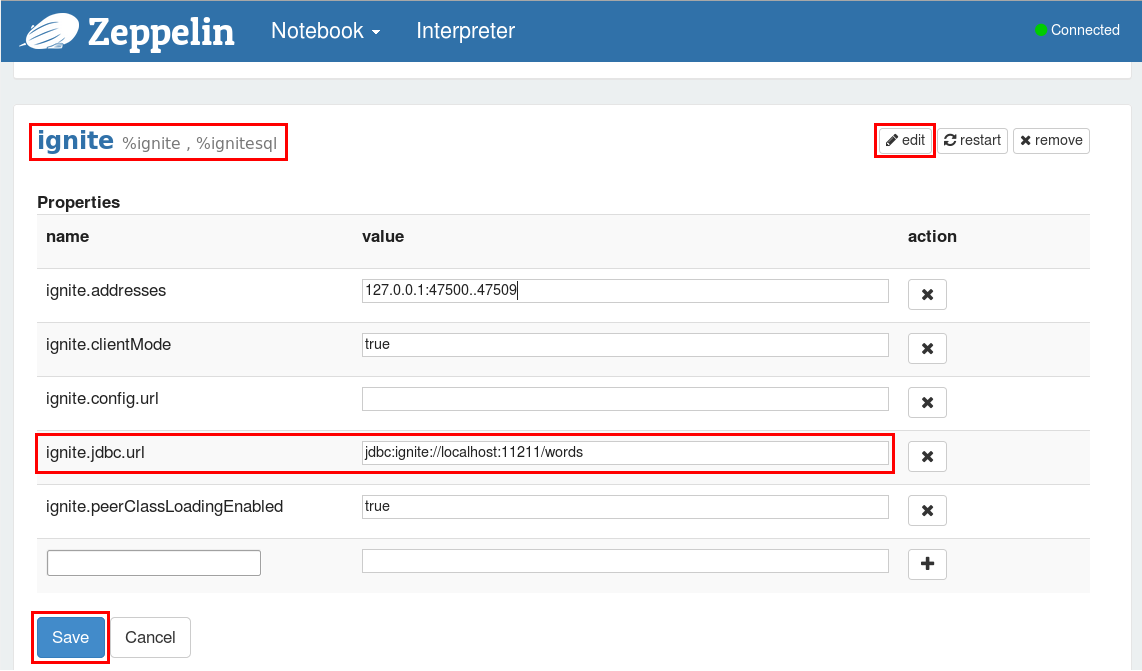
配置Ignite SQL 解释器
Ignite SQL解释器只需要ignite.jdbc.url属性,它的值是JDBC连接地址,在后面的示例中会用到words缓存,因此像下面这样编辑ignite.jdbc.url属性:
jdbc:ignite://localhost:11211/words
配置Ignite解释器
在大多数简单的场景中,Ignite解释器需要下述属性:
ignite.addresses:逗号分割的Ignite集群主机列表,要了解细节信息可以参照2.4.集群配置章节;ignite.clientMode:可以以客户端节点也可以以服务端节点连接到Ignite集群,要了解细节可以参照客户端和服务器端章节。可以使用true或者false分别以客户端或者服务端模式连接到集群。ignite.peerClassLoadingEnabled:启用对等类加载,要了解细节可以参照2.5.零部署章节。可以用true或者false分别启用或者禁用对等类加载。
对于更复杂的场景,可以通过指向Ignite配置文件的ignite.config.url属性来自定义Ignite配置,注意如果定义了ignite.config.url属性,那么上述的属性都会被忽略。
# 5.4.使用Ignite解释器
启动Ignite集群
在使用Zeppelin之前需要启动Ignite集群,下载Ignite二进制包然后解压压缩包:
unzip apache-ignite-fabric-{version}-bin.zip -d <dest_dir>
示例是以一个单独的Maven工程的形式提供的,因此要启动运行只需要简单地导入<dest_dir>/apache-ignite-fabric-{version}-bin/pom.xml文件到喜欢的IDE中即可。
启动如下的示例:
org.apache.ignite.examples.ExampleNodeStartup:启动一个或者多个Ignite节点;org.apache.ignite.examples.streaming.wordcount.StreamWords:启动客户端节点使数据持续流入words缓存。
现在已经准备好通过Zeppelin来访问Ignite集群了。
在Zeppelin中创建新的笔记
通过Notebook菜单项创建(或者打开已有的)笔记。
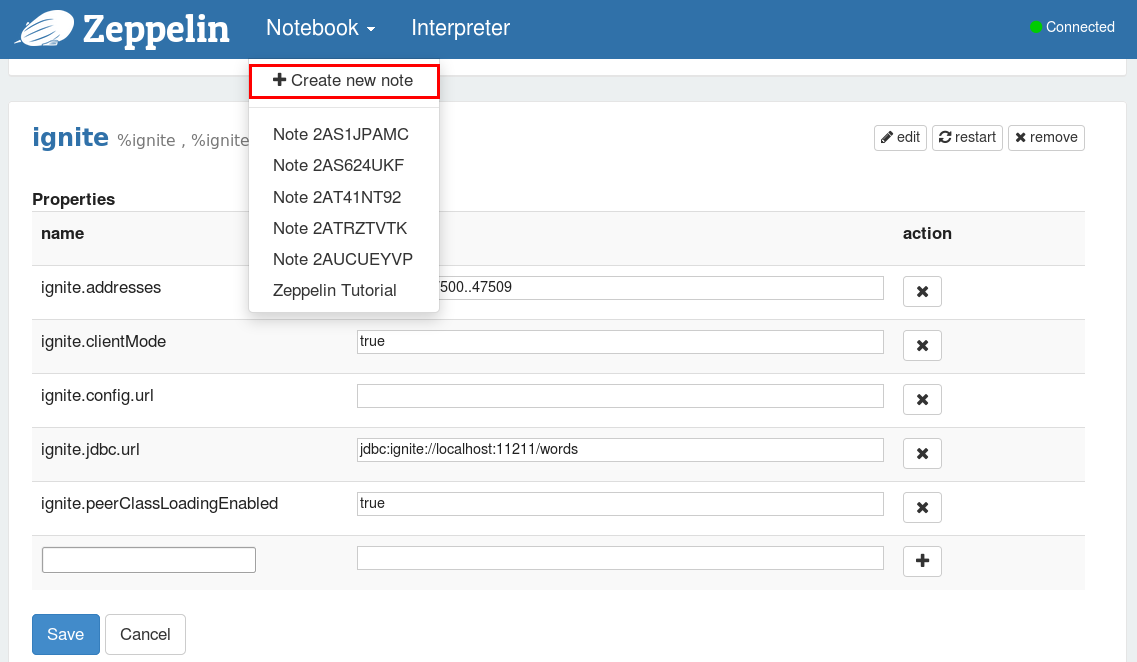
创建新的笔记之后需要再次点击Notebook菜单项来打开创建的笔记,点击笔记的名字可以对它重新命名,输入新的标题然后按下回车键。
笔记创建之后就可以输入SQL语句或者Scala代码,通过点击Execute按钮来执行(蓝色三角形图标)。
使用Ignite SQL解释器
要执行SQL查询要使用%ignite.ignitesql前缀以及SQL语句,比如查询words缓存中最初的是个单词,可以使用如下的查询:
%ignite.ignitesql select _val, count(_val) as cnt from String group by _val order by cnt desc limit 10
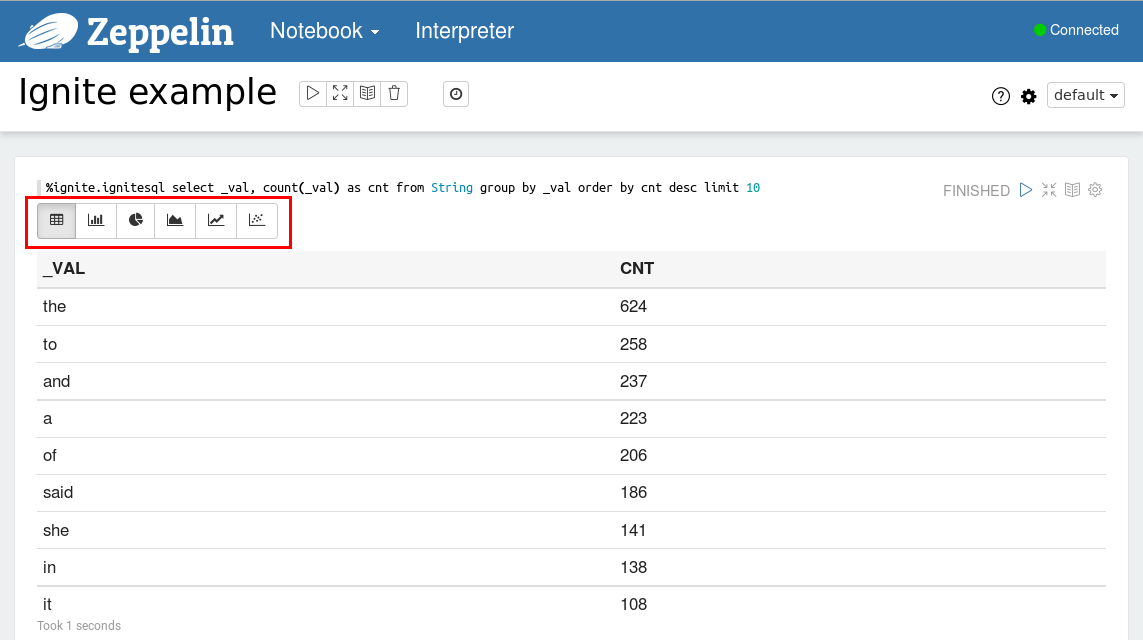
执行示例之后可以以表格或者图形的形式查看结果,可以通过点击相应的图标来切换视图。
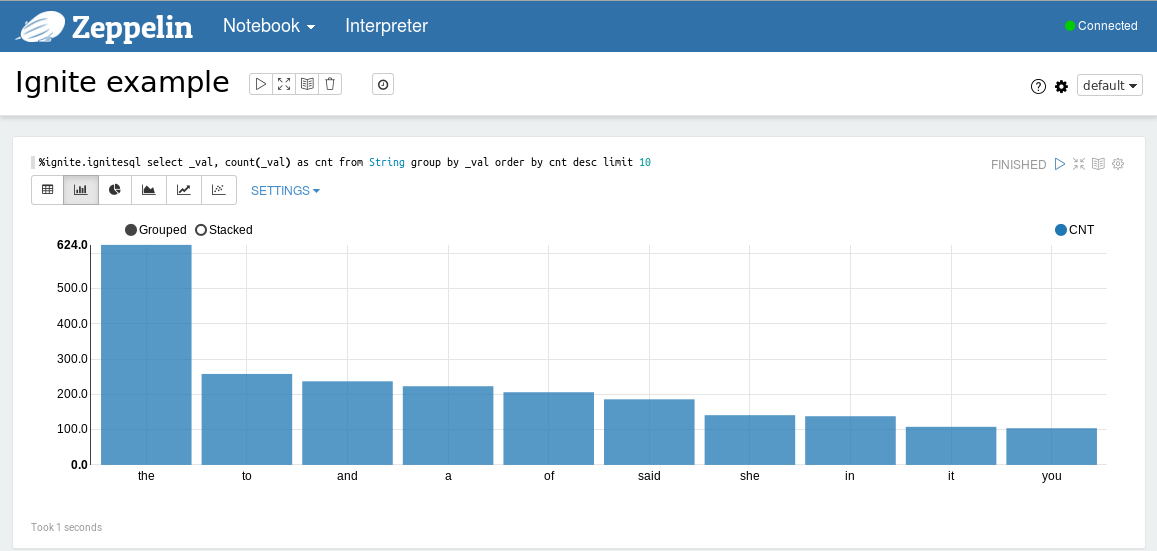
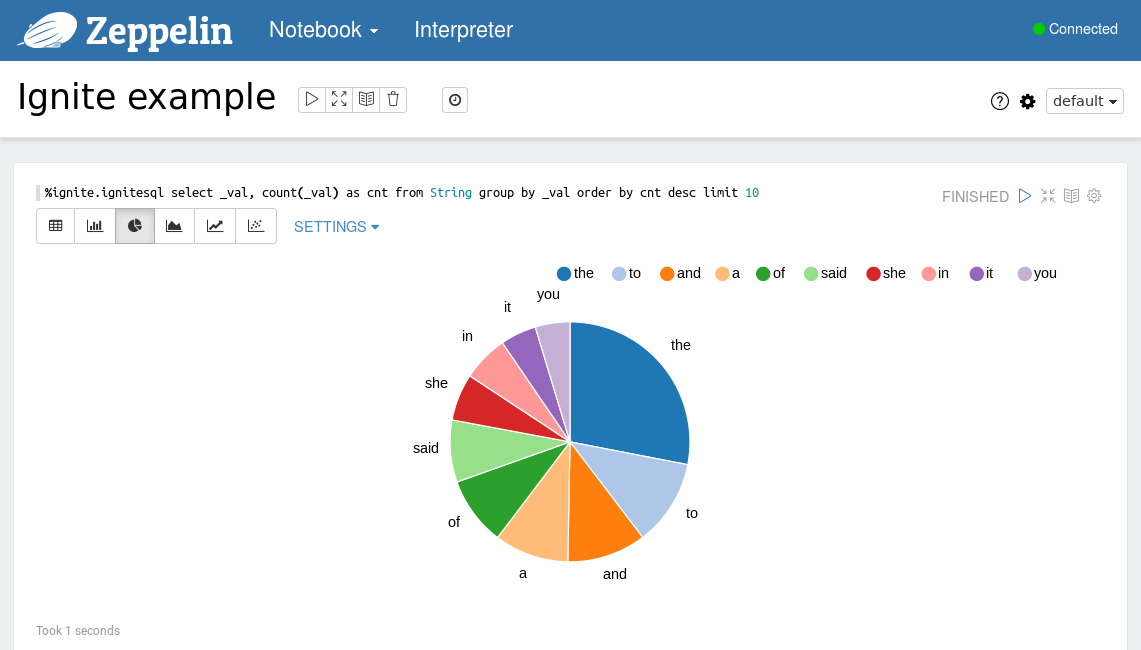
使用Ignite解释器
要执行Scala代码片段需要使用%ignite前缀以及代码片段,比如可以在所有的单词中查询平均值,最小值以及最大值。
%ignite
import org.apache.ignite._
import org.apache.ignite.cache.affinity._
import org.apache.ignite.cache.query._
import org.apache.ignite.configuration._
import scala.collection.JavaConversions._
val cache: IgniteCache[AffinityUuid, String] = ignite.cache("words")
val qry = new SqlFieldsQuery("select avg(cnt), min(cnt), max(cnt) from (select count(_val) as cnt from String group by _val)", true)
val res = cache.query(qry).getAll()
collectionAsScalaIterable(res).foreach(println _)
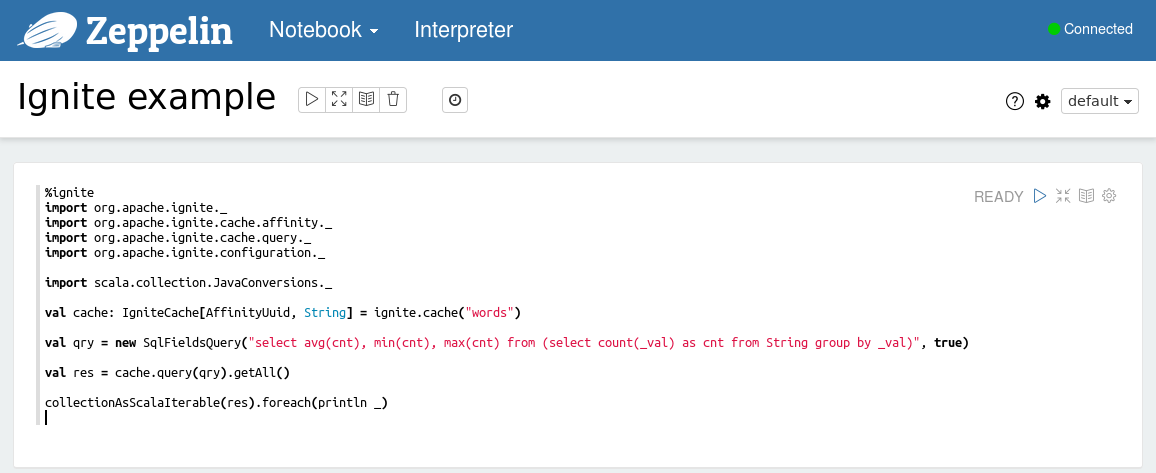
执行这个示例之后就可以看到Scala REPL的输出:
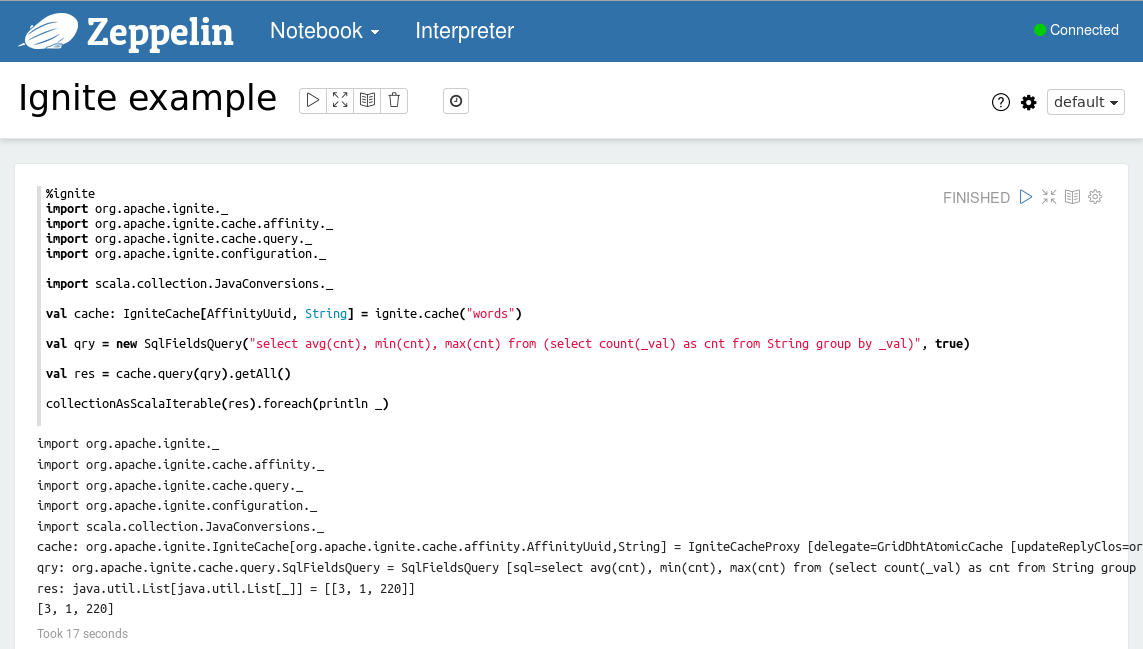
注意Ignite集群的Ignite版本以及Zeppelin的版本必须匹配。