# 深度学习
# 1.基于TensorFlow的深度学习
TensorFlow是一个用于高性能数值计算的开源软件库,主要用于深度学习和其它计算密集型机器学习任务。其灵活的体系结构允许跨各种平台(CPU、GPU、TPU)轻松部署计算。最初是由Google人工智能体系内的Google大脑团队的研究人员和工程师开发的,它具有对机器学习和深度学习的强大支持,并且灵活的数值计算核心也可以用于许多其它科学领域。
Ignite是一个以内存为中心的分布式数据库、缓存和处理平台,支持事务、分析和流式工作负载,以内存级的性能可以支撑PB级的数据规模。
Ignite和TensorFlow的集成可以提供一个完整的工具集,用于处理在线的和历史的数据,执行数据分析和基于神经网络构建复杂的数学模型。
# 1.1.Ignite Dataset
Ignite Dataset表示Apache Ignite和TensorFlow之间的集成,它允许TensorFlow将Apache Ignite用作神经网络训练、推理和TensorFlow支持的所有其它计算的数据源。使用Ignite Dataset有许多优点,包括:
- TensorFlow可以快速地访问一个包含待训练和待推理数据的分布式数据库;
- Ignite Dataset提供的对象可以具有任何结构,因此可以在TensorFlow流水线中进行所有预处理;
- SSL、Windows和分布式训练也是支持的;
目前,Ignite Dataset是TensorFlow的一部分,因此不需要安装任何第三方包就可以直接使用。集成基于TensorFlow的tf.data和Ignite的二进制客户端协议。
# 1.2.IGFS插件
除了分布式数据库的功能,Ignite还有一个叫做IGFS的分布式文件系统,IGFS的功能类似于Hadoop的HDFS,但是仅仅在内存级。
集成基于TensorFlow的自定义文件系统插件和Ignite的IGFS原生API,它有很多使用场景,比如:
- 为了可靠性和容错性,状态检查点可以保存到IGFS;
- 通过将事件文件写入一个目录,训练过程可以与TensorBoard进行通信,TensorBoard会监控这个目录,IGFS的存在,使得TensorBoard即使位于不同的进程或者机器,通信都是可以正常进行。
IGFS插件的状态
目前,IGFS插件还不是Tensorflow的一部分,TensorFlow的当前状态,可以看这个PR。
# 2.分布式训练
# 2.1.概述
分布式训练可以使用整个集群的计算资源,从而加速深度学习模型的训练。TensorFlow是一个机器学习框架,原生支持分布式神经网络训练、推理和其它计算。分布式神经网络训练的主要思想是能够计算每个数据分区(按照水平分区)上的损失函数(误差的平方)的梯度,然后将它们相加以获得整个数据集的损失函数梯度:

利用这种能力,可以计算数据实际所在节点的梯度,减少这些梯度,最后更新模型参数。这避免了节点之间的数据传输,从而防止了网络阻塞。
Ignite使用水平分区在分布式集群中存储数据。当创建一个Ignite缓存(或SQL表)时,可以指定数据将被分区的分区数量。例如,如果Ignite集群由10台机器组成,并且创建了10个分区的缓存,那么每台机器将维护大约一个数据分区。
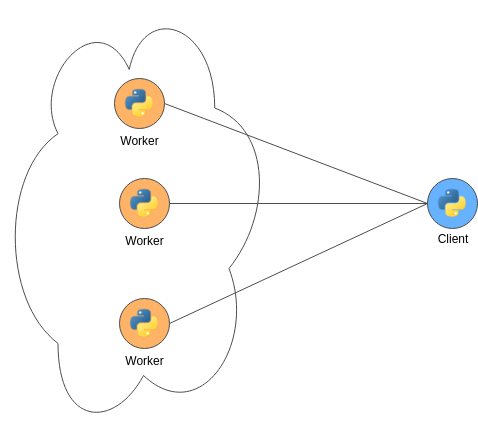
TensorFlow在Ignite之上的分布式训练,是基于分布式多工作节点训练的独立客户端模式。这个模式假设已经有一个已启动TensorFlow服务端的工作节点集群,并且有一个实际包含模型代码的客户端。当客户端调用tf.estimator.train_and_evaluate时,TensorFlow会使用特定的分布策略将计算分布在工作节点中,以便计算最密集的部分在工作节点上执行。
# 2.2.Ignite上的独立客户端模式
对于运行在Ignite之上的TensorFlow,最重要的目标之一是避免冗余数据传输,并利用数据分区,这是Ignite的核心概念。Ignite提供了所谓的零ETL,为了实现这个目标,在存储数据的节点上启动并维护了TensorFlow工作节点。下图说明了这个想法:

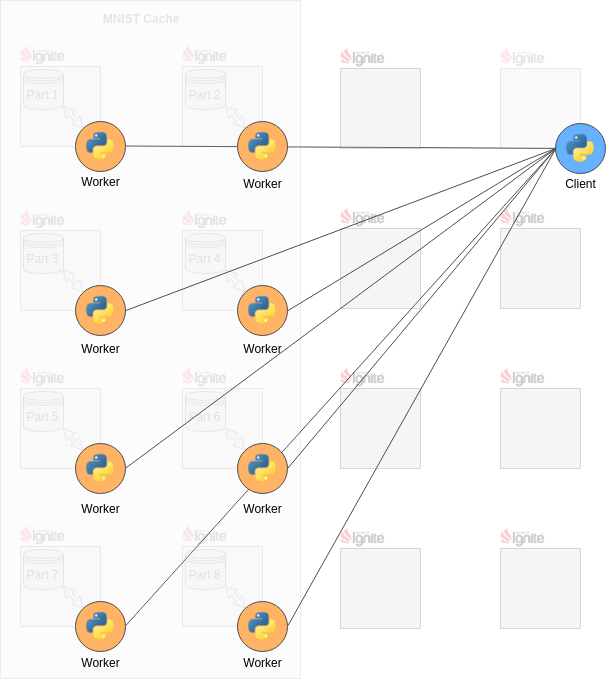
如图所示,Ignite集群中的MNIST缓存分布在8个服务端(每个服务端一个分区)上,除了维护数据分区之外,每个服务端还维护一个TensorFlow工作节点。每个工作节点配置为只能访问本地数据(这种“粘性”通过一组环境变量实现)。
与Ignite上的TensorFlow中的经典独立客户端模式不同,客户端进程也是在Ignite集群内作为服务启动的。这允许Ignite在任何故障情况下或在数据再平衡事件之后自动重新开始训练。
当初始化完成并配置好TensorFlow集群后,Ignite并不干扰TensorFlow的工作。只有在出现故障和数据再平衡事件的情况下,Ignite才重新启动集群。在正常操作模式中,可以认为整个架构如下图所示:
# 3.命令行工具
为了允许用户在Ignite集群之上对构建一个TensorFlow集群进行控制,Ignite提供了一个简单的命令行工具,支持的命令下面会介绍。
# 3.1.start命令
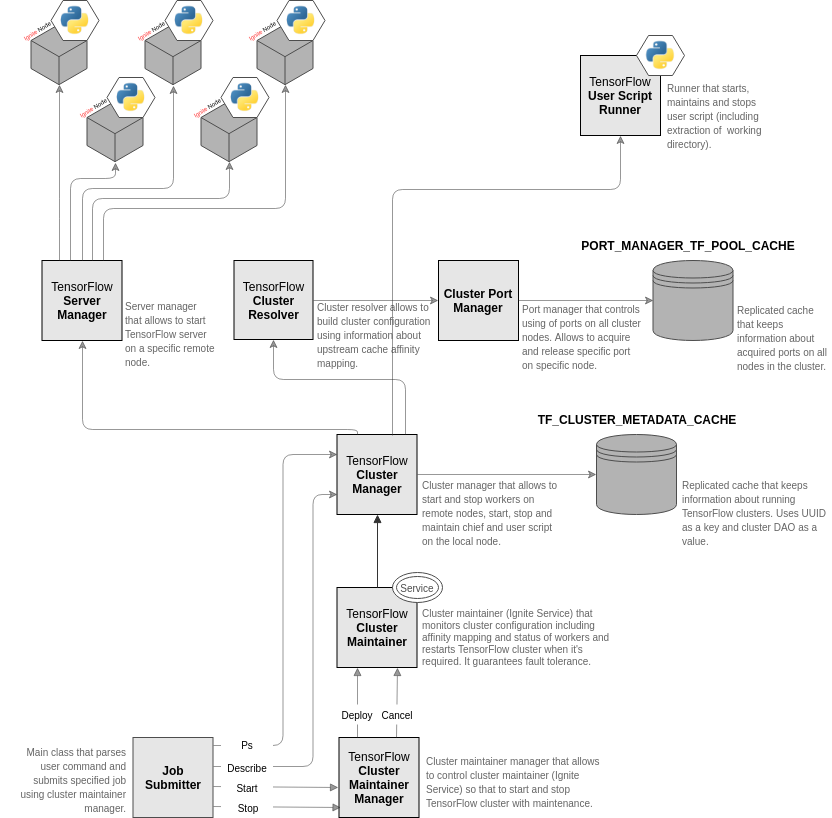
start命令在Ignite集群的特定缓存之上启动了一个新的TensorFlow集群,然后开始训练(指定了JOB_DIR,JOB_CMD和JOB_ARGS)。都启动之后,Ignite会维护所有的进程,如果故障会重启它们。start命令的输出,就是训练的输出。
start命令
使用: ignite-tf start [-hV] [-c=<cfg>] CACHE_NAME JOB_DIR JOB_CMD[JOB_ARGS...]
启动新的TensorFlow集群并附加到用户脚本进程。
CACHE_NAME 上游缓存名
JOB_DIR 作业文件夹(或zip压缩包)
JOB_CMD 作业命令
[JOB_ARGS...] 作业参数
-c, --config=<cfg> Ignite客户端配置
-h, --help 显示帮助信息并退出
-V, --version 输出版本信息并退出
内部流程如下:
- 确定指定缓存的分区位置;
- 根据分区位置,在对应的节点启动工作节点;
- 在集群中通过配置了
TF_CONFIG(包含了工作节点位置等信息)的随机节点,启动训练代码; - 将训练的输出路由到start命令的输出
- 如果发生故障,停止然后重新启动回到第一步
- 如果成功结束,则全部停止
# 3.2.stop命令
stop命令停止该TensorFlow集群及相应的训练。
stop命令
使用:ignite-tf stop [-hV] [-c=<cfg>] CLUSTER_ID
停止正在运行的TensorFlow集群。
CLUSTER_ID 集群的标识符
-c, --config=<cfg> Ignite的客户端配置
-h, --help 显示帮助信息并退出
-V, --version 输出版本信息并退出
# 3.3.attach命令
attach命令会附加指定的训练并将训练结果路由到attach命令的输出。
attach命令
使用:ignite-tf attach [-hV] [-c=<cfg>] CLUSTER_ID
附加到正在运行的TensorFlow集群(用户脚本进程)。
CLUSTER_ID 集群的标识符
-c, --config=<cfg> Ignite的客户端配置
-h, --help 显示帮助信息并退出
-V, --version 输出版本信息并退出
# 3.4.ps命令
ps命令会输出所有正在运行的TensorFlow集群信息。
ps命令
使用:ignite-tf ps [-hV] [-c=<cfg>]
ps命令会输出所有正在运行的TensorFlow集群信息。
-c, --config=<cfg> Ignite的客户端配置
-h, --help 显示帮助信息并退出
-V, --version 输出版本信息并退出
# 3.5.集群管理器
Ignite有一个复杂的架构来维护TensorFlow集群,下图会对这个架构做一个浓缩: