# 持久化
# 1.Ignite持久化
# 1.1.概述
Ignite的原生持久化是一个分布式的ACID和兼容SQL的磁盘存储,它可以透明地与Ignite的固化内存进行集成。Ignite的持久化是可选的,可以打开也可以关闭,当关闭时Ignite就会变成一个纯内存存储。
Ignite的原生持久化会在磁盘上存储一个数据的超集,以及根据容量在内存中存储一个子集。比如,如果有100个条目,然后内存只能存储20条,那么磁盘上会存储所有的100条,然后为了提高性能在内存中缓存20条。
另外值得一提的是,和纯内存的使用场景一样,当打开持久化时,每个独立的节点只会持久化数据的一个子集,不管是主还是备节点,都是只包括节点所属的分区的数据,总的来说,整个集群包括了完整的数据集。
Ignite的原生持久化有如下的特性:
- SQL查询会在囊括内存和磁盘的完整数据集上执行,这就意味着Ignite可以被用作一个以内存为中心的分布式SQL数据库;
- 不需要在内存中保存所有的数据和索引,Ignite的持久化允许在磁盘上存储一个数据的超集,然后只在内存中保存频繁访问的数据的子集;
- 集群即时重启,如果整个集群宕掉,那么是不需要通过从持久化预加载数据来对内存进行预热的,只要所有的节点都可以互相访问了,集群就具有了完整的功能;
- 数据和索引在内存和磁盘上以类似的格式存储,这有助于避免在内存和磁盘之间移动数据时进行昂贵的转换;
- 通过加入第三方的解决方案,可以具有创建集群的完整以及增量快照的功能。
# 1.2.使用
要开启Ignite的原生持久化,需要给集群的配置传递一个DataStorageConfiguration的实例:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<!-- Enabling Apache Ignite native persistence. -->
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
</bean>
</property>
</bean>
</property>
<!-- Additional setting. -->
</bean>
Java:
// Apache Ignite node configuration.
IgniteConfiguration cfg = new IgniteConfiguration();
// Ignite persistence configuration.
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
// Enabling the persistence.
storageCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true);
// Applying settings.
cfg.setDataStorageConfiguration(storageCfg);
持久化开启之后,所有的数据和索引都会存储在所有集群节点的内存和磁盘上,下图描述了在单独的集群节点的文件系统层看到的持久化结构:
每个数据区和每个缓存的持久化
Ignite可以为每个具体的数据区甚至每个缓存开启持久化,具体可以看内存区。
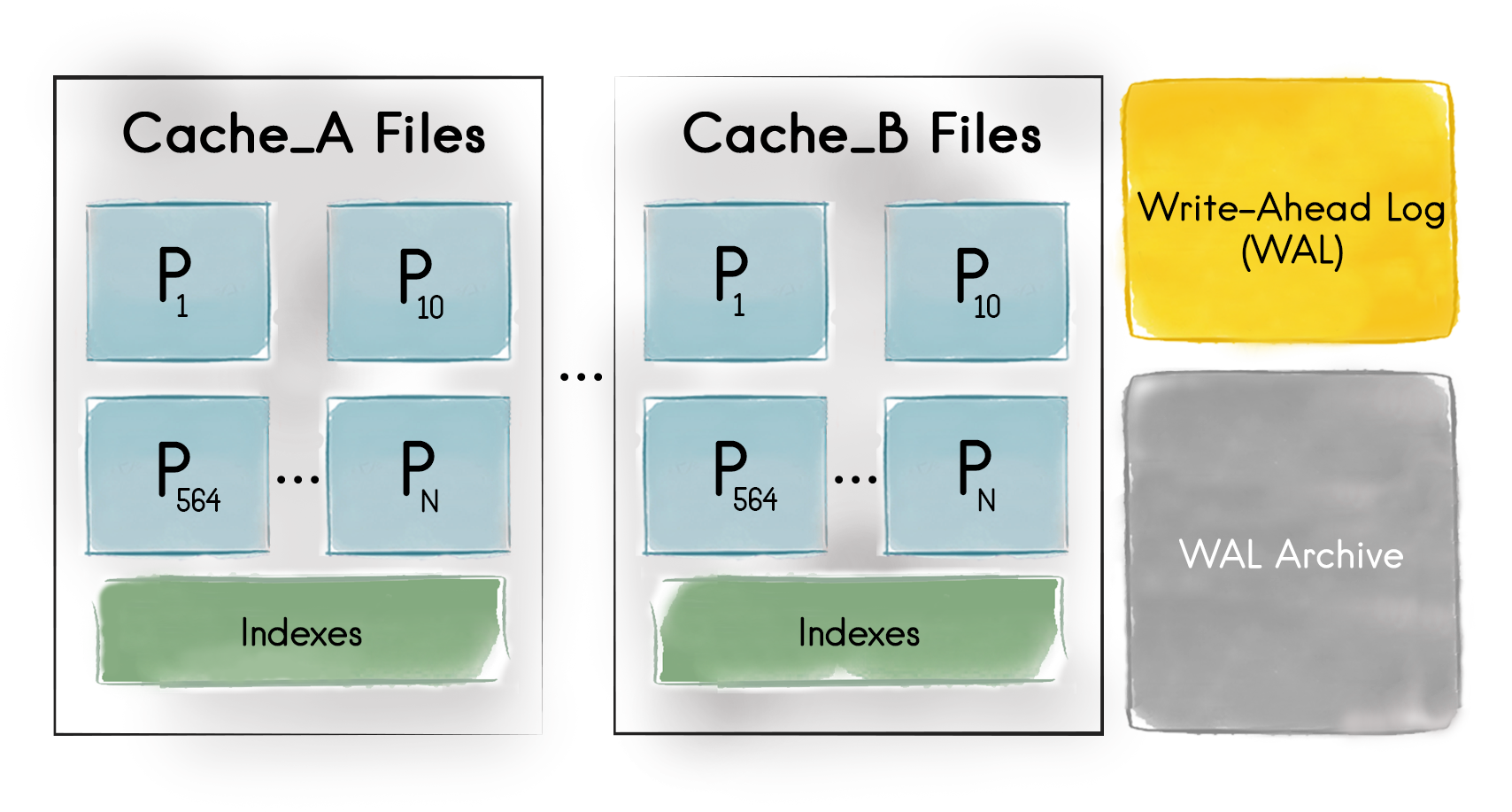
首先,节点中的每个缓存都要有一个唯一的目录,从上图可知,可以看到至少两个缓存(Cache_A和Cache_B),由节点来维护它们的数据和索引。
其次,对于节点的每个分区,不管是主还是备,Ignite的原生持久化都会在文件系统中创建一个专用文件。比如,对上面的节点来说,它负责分区1,10到564,索引是每个缓存一个文件。
缓存组和分区文件
如果Cache_A和Cache_B属于同一个缓存组,那么这些缓存共享的分区文件会放在一个目录中。
最后,和预写日志活动有关的文件和目录,下面还会介绍。
集群激活
注意如果开启了Ignite持久化,集群默认是未激活的,无法进行任何的CRUD操作。用户需要手工激活集群,后面会介绍如何进行操作。
上述的文件层次默认是在一个名为${IGNITE_HOME}/work/db的目录中进行维护的,要改变存储和WAL文件的默认位置,可以使用DataStorageConfiguration中对应的setStoragePath(...)、setWalPath(...)和setWalArchivePath(...)方法。
如果一台主机启动了若干个节点,那么每个节点进程都会在一个预定义的唯一子目录中,比如${IGNITE_HOME}/work/db/node{IDX}-{UUID},有自己的持久化文件,这里IDX和UUID参数都是Ignite在节点启动时自动计算的(这里有详细描述)。如果在持久化层次结构中已经有了若干node{IDX}-{UUID}子目录,那么它们是按照节点先入先出的顺序进行赋值的。如果希望某节点即使重启也有专用目录和专用的数据分区,需要在集群范围配置唯一的IgniteConfiguration.setConsistentId,这个唯一ID会在node{IDX}-{UUID}字符串中映射到UUID。
一台主机隔离集群中的节点
Ignite可以在一台主机上隔离多个集群,每个集群都要在文件系统的不同目录下存储持久化文件,这时可以通过DataStorageConfiguration的setStoragePath(...)、setStoragePath(...)、setWalArchivePath(...)方法来重新定义每个集群的相应的路径。
# 1.3.事务保证
Ignite的原生持久化是一个兼容ACID的分布式存储,每个事务性更新都会首先被添加到WAL。更新会被赋予一个唯一的ID,这意味着集群在故障或者重启时总是会恢复到最近的成功提交的事务或者原子性更新。
# 1.4.SQL支持
Ignite的原生持久化可以将Ignite作为一个分布式的SQL数据库。
在集群中执行SQL查询时是不需要在内存中保存所有的数据的,Ignite会在内存和磁盘上的所有数据中执行。另外,在集群重启后将所有的数据都预加载到内存中也是一个选择,这时当集群启动运行时,就可以执行SQL查询了。
# 1.5.Ignite持久化内部
本章节提供了Ignite持久化的一个高层视图,如果想了解更多的技术细节,可以看下面的文档:
# 1.6.性能提示
在固化内存调优章节中有关于性能方面的建议。
# 1.7.示例
要了解Ignite的原生持久化在实践中的应用,可以看GitHub上的这个示例。
# 2.预写日志(WAL)
# 2.1.概述
Ignite的持久化会为节点的每个分区创建和维护一个专有文件,但是当内存中的页面更新时,更新是不会直接写入对应的分区文件的,因为会严重影响性能,而是将数据写入预写日志的尾部(WAL)。
WAL的目的是为单个节点或者整个集群故障的场景提供一种恢复机制。值得一提的是,集群可以根据WAL的内容在故障或者重启时随时恢复到最近成功提交的事务。
整个WAL会被拆分为若干个文件,叫做段,它是按顺序进行填充的。当第一个段满了之后,它的内容会被复制到WAL存档(具体可以看下面的WAL存档章节),在第一个段的复制过程中,第二个段会被视为激活的WAL文件,然后接收由应用发送过来的更新请求。默认会创建和使用10个这样的段,这个数值可以通过DataStorageConfiguration.walSegments进行修改。
每个更新在写入WAL文件之前会被写入缓冲区,这个缓冲区的大小由DataStorageConfiguration.walBuffSize属性定义。如果开启了内存映射文件,WAL缓冲区大小默认等于WAL段大小,如果禁用了内存映射文件,WAL缓冲区大小为WAL段大小的四分之一。注意内存映射文件默认是开启的,它可以通过IGNITE_WAL_MMAP系统属性进行调整,这个属性可以通过JVM参数传入,比如:-DIGNITE_WAL_MMAP=false。
# 2.2.WAL模式
根据WAL模式的不同,Ignite提供了如下的一致性保证:
| WAL模式 | 描述 | 一致性保证 |
|---|---|---|
FSYNC | 保证每个原子写或者事务性提交都会持久化到磁盘。 | 数据更新不会丢失,不管是任何的操作系统或者进程故障,甚至是电源故障。 |
LOG_ONLY | 默认模式,对于每个原子写或者事务性提交,保证会刷新到操作系统的缓冲区缓存或者内存映射文件。默认会使用内存映射文件方式,并且可以通过将IGNITE_WAL_MMAP系统属性配置为false将其关闭。 | 如果仅仅是进程崩溃数据更新会保留。 |
BACKGROUND | 如果打开了IGNITE_WAL_MMAP属性(默认),该模式的行为类似于LOG_ONLY模式,如果关闭了内存映射文件方式,变更会保持在节点的内部缓冲区,缓冲区刷新到磁盘的频率由DataStorageConfiguration.setWalFlushFrequency参数定义。 | 如果打开了IGNITE_WAL_MMAP属性(默认),该模式提供了与LOG_ONLY模式一样的保证,否则如果进程故障或者其它的故障发生时,最近的数据更新可能丢失。 |
NONE | WAL被禁用,只有在节点优雅地关闭时,变更才会正常持久化,使用Ignite#active(false)可以冻结集群以及停止节点。 | 如果一个节点异常终止,可能出现数据丢失,存储于磁盘上的数据很可能会损坏或者不同步,然后持久化目录需要清理以便节点重启。 |
下面是如何配置WAL模式的代码示例:
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<!-- Enabling Apache Ignite Persistent Store. -->
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
</bean>
</property>
<!-- Changing WAL Mode. -->
<property name="walMode" value="FSYNC"/>
</bean>
</property>
<!-- Additional setting. -->
</bean>
Java:
// Apache Ignite node configuration.
IgniteConfiguration cfg = new IgniteConfiguration();
// Native Persistence configuration.
DataStorageConfiguration psCfg = new DataStorageConfiguration();
// Enabling the persistence.
psCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true);
// Set WAL Mode.
psCfg.setWalMode(WALMode.LOG_ONLY);
// Enabling the Persistent Store.
cfg.setDataStorageConfiguration(psCfg);
//Additional parameters.
# 2.3.WAL激活和冻结
WAL是Ignite持久化的一个基本组件,会在集群故障时保证持久性和一致性。
但是,有时因为性能原因禁用WAL也是合理的,比如,通常在数据初始加载时禁用WAL,然后在预加载完毕后再打开它。
分别通过IgniteCluster.enableWal(cacheName)和IgniteCluster.disableWal(cachename)方法可以打开和关闭WAL。如果要检查某个缓存是否开启了WAL,可以使用IgniteCluster.isWalEnabled(cacheName)。
如果使用SQL,可以使用ALTER TABLE命令打开/关闭WAL。
注意
如果禁用了WAL并重新启动节点,则将从该节点上的持久化存储中删除所有数据,这是因为如果没有WAL,在节点故障或重新启动时无法保证数据的一致性。
# 2.4.WAL存档
WAL存档用于保存故障后恢复节点所需的WAL段。存档中保存的段的数量应确保所有段的总大小不超过WAL存档的既定大小。
WAL存档的大小可以通过DataStorageConfiguration.maxWalArchiveSize属性进行配置,如果该属性在配置中未指定,存档的大小定义为4倍于检查点缓冲区的大小。
注意
将WAL存档大小配置为小于默认值可能影响性能,用于生产之前需要进行测试。
# 2.5.WAL存档调整
下面是一些关于如何通过调整WAL存档参数来调整空间占用和集群性能的提示。
# 2.5.1.WAL存档压缩
可以启用WAL存档压缩以减少WAL存档占用的空间。默认情况下,WAL存档包含最后20个检查点的段(这个数字是可配置的)。如果启用压缩,则所有比第1个检查点旧的存档段都将压缩为zip格式。在需要这些段的时候(例如,为了在节点之间进行数据再平衡),它们将被解压缩为原始格式。
要启用WAL存档压缩,请将DataStorageConfiguration.walCompactionEnabled属性设置为true。还可以指定压缩级别(1表示最快的速度,9表示最佳的压缩)。
XML:
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<!-- Enabling Apache Ignite Persistent Store. -->
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
</bean>
</property>
<property name="walCompactionEnabled" value="true" />
<property name="walCompactionLevel" value="6" />
</bean>
Java:
DataStorageConfiguration dsCfg = new DataStorageConfiguration();
DataRegionConfiguration regCfg = new DataRegionConfiguration();
regCfg.setPersistenceEnabled(true);
dsCfg.setDefaultDataRegionConfiguration(regCfg);
dsCfg.setWalCompactionEnabled(true);
# 2.5.2.禁用WAL存档
有时可能想要禁用WAL存档,比如减少与将WAL段复制到存档文件有关的开销,当Ignite将数据写入WAL段的速度快于将段复制到存档文件的速度时,这样做就有用,因为这样会导致I/O瓶颈,从而冻结节点的操作,如果遇到了这样的问题,就可以尝试关闭WAL存档。
要关闭存档,可以将WAL路径和WAL存档路径配置为同一个值,这时Ignite就不会将段复制到存档文件,而是按顺序循环地覆盖激活段。
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<!-- Enabling Apache Ignite Persistent Store. -->
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
</bean>
</property>
<property name="walPath" value="/wal/path"/>
<property name="walArchivePath" value="/wal/path"/>
</bean>
</property>
<!-- Additional setting. -->
</bean>
Java:
DataStorageConfiguration dsCfg = new DataStorageConfiguration();
DataRegionConfiguration regCfg = new DataRegionConfiguration();
regCfg.setPersistenceEnabled(true);
dsCfg.setDefaultDataRegionConfiguration(regCfg);
String walAbsPath = "/wal/path";
dsCfg.setWalPath(walAbsPath);
dsCfg.setWalArchivePath(walAbsPath);
# 3.检查点
# 3.1.概述
由于WAL文件会一直增长,并且通过WAL从头到尾地恢复集群会花费大量的时间。为了解决这个问题,Ignite引入了一个检查点过程。
检查点是一个将脏页面从内存复制到磁盘上的分区文件的过程,脏页面是指页面已经在内存中进行了更新但是还没有写入对应的分区文件(只是添加到了WAL中)。
这个过程有助于通过在磁盘上保持页面的最新状态而高效地利用磁盘空间,并且允许在WAL档案中删除过时的WAL段(文件)。
# 3.2.工作方式
下图显示的是一个简单的更新操作的执行过程:
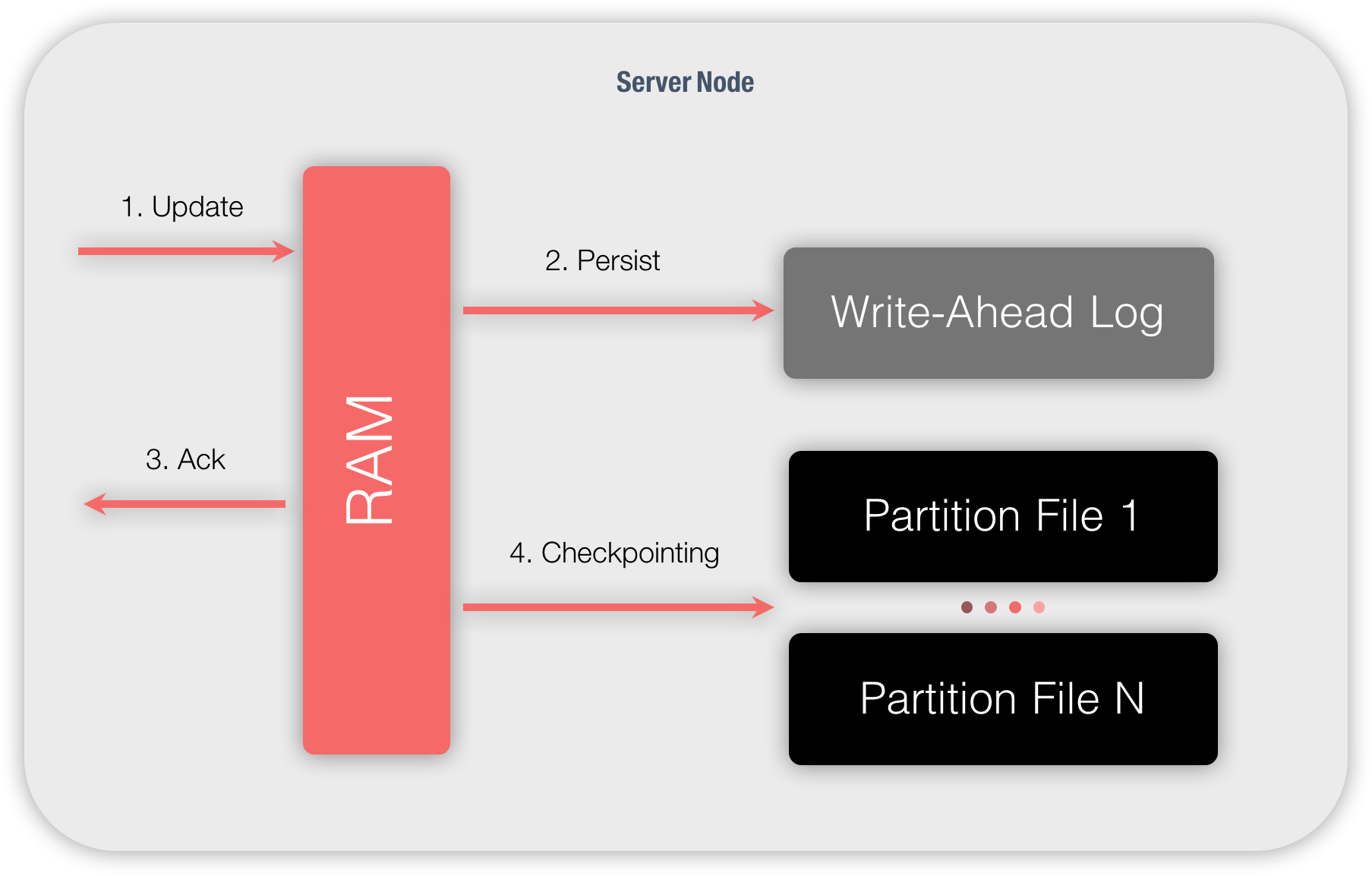
- 节点接收到更新请求之后,它会在内存中查找该数据所属的数据页面,该页面会被更新然后标记为脏页面;
- 更新会被附加到WAL的尾部;
- 节点会向更新发起方发送一个更新成功的确认信息;
- 根据配置或者其它参数配置的频率,检查点会被定期地触发。脏页面会从内存复制到磁盘,然后传递给特定的分区文件;
# 4.第三方存储
# 4.1.概述
Ignite可以做为已有的第三方数据库之上的一个缓存层(数据网格),包括RDBMS、Apache Cassandra,该模式可以对底层数据库进行加速。Ignite对于在任何RDBMS和Cassandra中进行数据库记录的读写,提供了直接的支持,而对于其它NoSQL数据库的通读和通写功能,则没有现成的实现,不过Ignite提供了API,可以实现自定义的CacheStore。
JCache规范提供了javax.cache.integration.CacheLoader和javax.cache.integration.CacheWriterAPI,它们分别用于底层持久化存储的通读和通写(比如RDBMS中的Oracle或者MySQL,以及NoSQL数据库中的MongoDB或者CouchDB)。除了键-值操作,Ignite还支持INSERT、UPDATE和MERGE操作的通写,但是SELECT查询是无法读取第三方数据库的数据的。
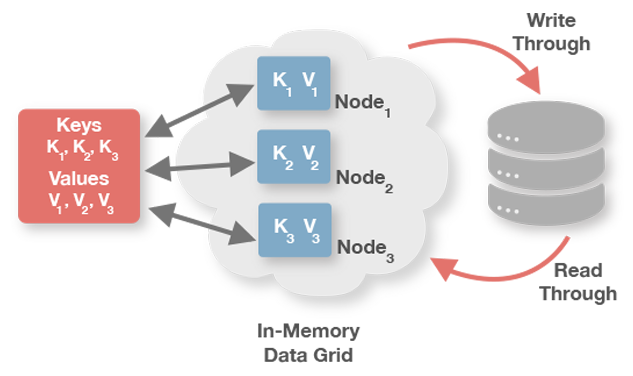
虽然Ignite可以单独地配置CacheRLoader和CacheWriter,但是在两个单独的类中实现事务化存储是非常尴尬的,因为多个load和put操作需要在同一个事务中的同一个连接中共享状态。为了解决这个问题,Ignite提供了org.apacche.ignite.cache.store.CacheStore接口,它同时扩展了CacheLoader和CacheWriter。
事务
CacheStore是完整事务性的,它会自动地融入当前的缓存事务。
# 4.2.通读和通写
如果需要通读和通写行为时,就得提供一个正确的CacheStore实现。通读意味着当缓存无效时会从底层的持久化存储中读取,注意这只对缓存的get操作有效,Ignite的SELECT查询不会从第三方持久化中通读数据,要执行SELECT查询,数据必须从数据库中预加载到Ignite缓存中(后面会解释)。
通写意味着当缓存更新时会自动地进行持久化。所有的通读和通写都会参与整体的缓存事务以及作为一个整体提交或者回滚。
要配置通读和通写,需要实现CacheStore接口以及设置CacheConfiguration中cacheStoreFactory的readThrough和writeThrough属性,下面的示例会有说明。
# 4.3.后写缓存
在一个简单的通写模式中每个缓存的put和remove操作都会涉及一个持久化存储的请求,因此整个缓存更新的持续时间可能是相对比较长的。另外,密集的缓存更新频率也会导致非常高的存储负载。
对于这种情况,Ignite提供了一个选项来执行异步化的持久化存储更新,也叫做后写,这个方式的主要概念是累加更新操作然后作为一个批量操作异步化地刷入持久化存储中。真实的数据持久化可以被基于时间的事件触发(数据输入的最大时间受到队列的限制),也可以被队列的大小触发(当队列大小达到一个限值),或者通过两者的组合触发,这时任何事件都会触发刷新。
更新顺序
对于后写的方式只有数据的最后一次更新会被写入底层存储。如果键为key1的缓存数据分别依次地更新为值value1、value2和value3,那么只有(key1,value3)对这一个存储请求会被传播到持久化存储。
更新性能
批量的存储操作通常比按顺序的单一存储操作更有效率,因此可以通过开启后写模式的批量操作来利用这个特性。简单类型(put和remove)的简单顺序更新操作可以被组合成一个批量操作。比如,连续地往缓存中加入(key1,value1),(key2,value2),(key3,value3)可以通过一个单一的CacheStore.putAll(...)操作批量处理。
后写缓存可以通过CacheConfiguration.setWriteBehindEnabled(boolean)配置项来开启,下面的配置章节显示了一个完整的配置属性列表来进行后写缓存行为的定义。
# 4.4.配置
下面cacheConfiguration的配置参数可以用于启用以及配置后写缓存:
| setter方法 | 描述 | 默认值 |
|---|---|---|
setWriteBehindEnabled(boolean) | 设置后写是否启用的标志 | false |
setWriteBehindFlushSize(int) | 后写缓存的最大值,如果超过了这个限值,所有的缓存数据都会被刷入CacheStore然后写缓存被清空。如果值为0,刷新操作将会依据刷新频率间隔,注意不能将写缓存大小和刷新频率都设置为0 | 10240 |
setWriteBehindFlushFrequency(long) | 后写缓存的刷新频率,单位为毫秒,该值定义了从对缓存对象进行插入/删除和当相应的操作被施加到CacheStore的时刻之间的最大时间间隔。如果值为0,刷新会依据写缓存大小,注意不能将写缓存大小和刷新频率都设置为0 | 5000 |
setWriteBehindFlushThreadCount(int) | 执行缓存刷新的线程数 | 1 |
setWriteBehindBatchSize(int) | 后写缓存存储操作的操作数最大值 | 512 |
CacheStore接口可以在IgniteConfiguration上通过一个工厂进行设置,就和CacheLoader和CacheWriter同样的方式。
注意
对于分布式缓存的配置,Factory应该是可序列化的。
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
...
<property name="cacheConfiguration">
<list>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
...
<property name="cacheStoreFactory">
<bean class="javax.cache.configuration.FactoryBuilder" factory-method="factoryOf">
<constructor-arg value="foo.bar.MyPersonStore"/>
</bean>
</property>
<property name="readThrough" value="true"/>
<property name="writeThrough" value="true"/>
</bean>
</list>
</property>
...
</bean>
Java:
IgniteConfiguration cfg = new IgniteConfiguration();
CacheConfiguration<Long, Person> cacheCfg = new CacheConfiguration<>();
cacheCfg.setCacheStoreFactory(FactoryBuilder.factoryOf(MyPersonStore.class));
cacheCfg.setReadThrough(true);
cacheCfg.setWriteThrough(true);
cfg.setCacheConfiguration(cacheCfg);
// Start Ignite node.
Ignition.start(cfg);
# 4.5.RDBMS集成
Ignite可以和任意RDBMS集成,将数据加载进Ignite缓存,然后执行键-值操作,包括ACID事务,这有两种方式:
自动
使用Ignite的Web控制台可以从RDBMS中自动导入元数据,以及创建Ignite的集群配置,具体细节可以看自动化RDBMS集成的相关文档。
手动
在Ignite的XML配置文件(或者通过代码)中,可以手动地开启JDBC的POJO存储,需要做的是:
- 下载使用的数据库的JDBC驱动,然后将其放入应用的类路径中;
- 通过初始化
CacheJdbcPojoStoreFactory,配置CacheConfiguration的cacheStoreFactory属性,需要提供的属性如下:
dataSourceBean:数据库连接凭据,url、用户名、密码等;dialect:兼容于数据库的方言,Ignite为如下的数据库提供直接支持:MySQL、Oracle、H2、SQL Server和DB2。这些方言位于Ignite的org.apache.ignite.cache.store.jdbc.dialect包中;types:这个属性用于定义数据库表和相对应的POJO之间的映射(具体可以看下面的示例);
配置完之后,就可以通过IgniteCache.loadCache()方法将数据从数据库中加载进对应的Ignite缓存。
示例
本例中使用MySQL数据库,假定有一个PERSON表,该表有字段:id、orgId、name以及salary。
POJO配置:
<!-- Data source beans -->
<bean id="dsMySQL_Test" class="com.mysql.cj.jdbc.MysqlDataSource">
<property name="URL" value="jdbc:mysql://[host]:[port]/[database]"/>
<property name="user" value="YOUR_USER_NAME"/>
<property name="password" value="YOUR_PASSWORD"/>
</bean>
<!-- Ignite Configuration -->
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="cacheConfiguration">
<list>
<!-- Configuration for PersonCache -->
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="PersonCache"/>
<property name="cacheMode" value="PARTITIONED"/>
<property name="atomicityMode" value="ATOMIC"/>
<property name="cacheStoreFactory">
<bean class="org.apache.ignite.cache.store.jdbc.CacheJdbcPojoStoreFactory">
<property name="dataSourceBean" value="dsMySQL_Test"/>
<property name="dialect">
<bean class="org.apache.ignite.cache.store.jdbc.dialect.MySQLDialect">
</bean>
</property>
<property name="types">
<list>
<bean class="org.apache.ignite.cache.store.jdbc.JdbcType">
<property name="cacheName" value="PersonCache"/>
<property name="keyType" value="java.lang.Integer"/>
<property name="valueType" value="com.gridgain.pgarg.model.Person"/>
<property name="databaseSchema" value="MY_DB_SCHEMA"/>
<property name="databaseTable" value="PERSON"/>
<property name="keyFields">
<list>
<bean class="org.apache.ignite.cache.store.jdbc.JdbcTypeField">
<constructor-arg>
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
<constructor-arg value="id"/>
<constructor-arg value="int"/>
<constructor-arg value="id"/>
</bean>
</list>
</property>
<property name="valueFields">
<list>
<bean class="org.apache.ignite.cache.store.jdbc.JdbcTypeField">
<constructor-arg>
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
<constructor-arg value="orgId"/>
<constructor-arg value="java.lang.Integer"/>
<constructor-arg value="orgid"/>
</bean>
<bean class="org.apache.ignite.cache.store.jdbc.JdbcTypeField">
<constructor-arg>
<util:constant static-field="java.sql.Types.VARCHAR"/>
</constructor-arg>
<constructor-arg value="name"/>
<constructor-arg value="java.lang.String"/>
<constructor-arg value="name"/>
</bean>
<bean class="org.apache.ignite.cache.store.jdbc.JdbcTypeField">
<constructor-arg>
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
<constructor-arg value="salary"/>
<constructor-arg value="java.lang.Integer"/>
<constructor-arg value="salary"/>
</bean>
</list>
</property>
</bean>
</list>
</property>
</bean>
</property>
<property name="readThrough" value="true"/>
<property name="writeThrough" value="true"/>
<property name="queryEntities">
<list>
<bean class="org.apache.ignite.cache.QueryEntity">
<property name="keyType" value="java.lang.Integer"/>
<property name="valueType" value="com.gridgain.pgarg.model.Person"/>
<property name="keyFieldName" value="id"/>
<property name="keyFields">
<list>
<value>id</value>
</list>
</property>
<property name="fields">
<map>
<entry key="orgid" value="java.lang.Integer"/>
<entry key="name" value="java.lang.String"/>
<entry key="salary" value="java.lang.Integer"/>
<entry key="id" value="java.lang.Integer"/>
</map>
</property>
</bean>
</list>
</property>
</bean>
<!-- Provide similar configurations for other caches/tables -->
</list>
</property>
</bean>
缓存加载:
try (Ignite ignite = Ignition.start("path/to/xml-config/file")) {
// Load data from person table into PersonCache.
ignite.cache("PersonCache").loadCache(null);
// Populate other caches
...
}
Person类示例:
import java.io.Serializable;
public class Person implements Serializable {
/** */
private static final long serialVersionUID = 0L;
/** Value for orgid. */
private Integer orgid;
/** Value for name. */
private String name;
/** Value for salary. */
private Integer salary;
/** Value for id. */
private int id;
/** Empty constructor. **/
public Person() {
// No-op.
}
/** Full constructor. **/
public Person(Integer orgid,
String name,
Integer salary,
int id) {
this.orgid = orgid;
this.name = name;
this.salary = salary;
this.id = id;
}
/**
* Gets orgid
*
* @return Value for orgid.
**/
public Integer getOrgid() {
return orgid;
}
/**
* Sets orgid
*
* @param orgid New value for orgid.
**/
public void setOrgid(Integer orgid) {
this.orgid = orgid;
}
/**
* Gets name
*
* @return Value for name.
**/
public String getName() {
return name;
}
/**
* Sets name
*
* @param name New value for name.
**/
public void setName(String name) {
this.name = name;
}
/**
* Gets salary
*
* @return Value for salary.
**/
public Integer getSalary() {
return salary;
}
/**
* Sets salary
*
* @param salary New value for salary.
**/
public void setSalary(Integer salary) {
this.salary = salary;
}
/**
* Gets id
*
* @return Value for id.
**/
public int getId() {
return id;
}
/**
* Sets id
*
* @param id New value for id.
**/
public void setId(int id) {
this.id = id;
}
/** {@inheritDoc} **/
@Override public boolean equals(Object o) {
if (this == o)
return true;
if (!(o instanceof Person))
return false;
Person that = (Person)o;
if (orgid != null ? !orgid.equals(that.orgid) : that.orgid != null)
return false;
if (name != null ? !name.equals(that.name) : that.name != null)
return false;
if (salary != null ? !salary.equals(that.salary) : that.salary != null)
return false;
if (id != that.id)
return false;
return true;
}
/** {@inheritDoc} **/
@Override public int hashCode() {
int res = orgid != null ? orgid.hashCode() : 0;
res = 31 * res + (name != null ? name.hashCode() : 0);
res = 31 * res + (salary != null ? salary.hashCode() : 0);
res = 31 * res + (id);
return res;
}
/** {@inheritDoc} **/
@Override public String toString() {
return "Person [" +
"orgid=" + orgid + ", " +
"name=" + name + ", " +
"salary=" + salary + ", " +
"id=" + id +
"]";
}
}
CacheJdbcBlobStore
CacheJdbcBlobStore的实现基于JDBC,这个实现将对象用BLOB格式存储于底层数据库中,Store会在数据库中创建ENTRIES表,用于数据存储,该表有key和val两个字段。如果提供了自定义的DDL和DML语句,那么所有语句中的表名和字段名都应该是一致的,并且参数的顺序也要保留。
可以使用CacheJdbcBlobStoreFactory工厂向CacheConfiguration传入CacheJdbcBlobStore:
<bean id= "simpleDataSource" class="org.h2.jdbcx.JdbcDataSource">
<property name="url" value="jdbc:h2:mem:jdbcCacheStore;DB_CLOSE_DELAY=-1" />
</bean>
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
...
<property name="cacheConfiguration">
<list>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
...
<property name="cacheStoreFactory">
<bean class="org.apache.ignite.cache.store.jdbc.CacheJdbcBlobStoreFactory">
<property name="user" value = "user" />
<property name="dataSourceBean" value = "simpleDataSource" />
</bean>
</property>
</bean>
</list>
</property>
...
</bean>
CacheJdbcPojoStore
CacheJdbcPojoStore实现基于JDBC和基于反射的POJO,这个实现将对象用基于反射的Java Bean映射描述的形式存储在底层数据库中。
可以使用CacheJdbcPojoStoreFactory工厂向CacheConfiguration传入CacheJdbcPojoStore:
<bean id= "simpleDataSource" class="org.h2.jdbcx.JdbcDataSource"/>
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
...
<property name="cacheConfiguration">
<list>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
...
<property name="cacheStoreFactory">
<bean class="org.apache.ignite.cache.store.jdbc.CacheJdbcPojoStoreFactory">
<property name="dataSourceBean" value = "simpleDataSource" />
</bean>
</property>
</bean>
</list>
</property>
</bean>
CacheHibernateBlobStore
CacheHibernateBlobStore实现基于Hibernate,这个实现将对象以BLOB的格式存储在底层数据库中。
可以使用CacheHibernateBlobStoreFactory工厂向CacheConfiguration传入CacheHibernateBlobStore:
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
...
<property name="cacheConfiguration">
<list>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<bean class="org.apache.ignite.cache.store.hibernate.CacheHibernateBlobStoreFactory">
<property name="hibernateProperties">
<props>
<prop key="connection.url">jdbc:h2:mem:</prop>
<prop key="hbm2ddl.auto">update</prop>
<prop key="show_sql">true</prop>
</props>
</property>
</bean>
</list>
</property>
...
</bean>
# 4.6.NoSQL集成
Ignite可以与NoSQL数据库(比如Cassandra)集成。具体请参见Cassandra集成的相关文档,以了解如何将Cassandra用作Ignite持久化存储。对于其它NoSQL数据库,Ignite不提供任何现成的实现,开发者可以实现自己的CacheStore。
注意,虽然Ignite支持分布式事务,但如果将NoSQL数据库用作Ignite的持久层,Ignite也不会使其具有事务性。除非,NoSQL数据库直接支持事务。比如,在Ignite缓存上执行的事务不会传播到Cassandra。
# 4.7.自定义CacheStore
开发者还可以实现自己的CacheStore。CacheStore接口允许从底层数据存储中写入和读取数据。除了标准的JCache加载和存储方法外,它还引入了事务结束边界和从数据库批量加载缓存的能力。
loadCache()
CacheStore.loadCache()方法可以进行缓存的加载,而不需要传入要加载的所有键,它通常用于启动时缓存的热加载,但是也可以在缓存加载完之后的任何时间点调用。
在每一个相关的集群节点,IgniteCache.loadCache()方法会委托给CacheStore.loadCache()方法,如果只想在本地节点上进行加载,可以用IgniteCache.localLoadCache()方法。
提示
对于分区缓存,不管是主节点还是备份节点,如果键没有被映射到该节点,会被缓存自动丢弃。
load(), write(), delete()
当调用IgniteCache接口的get(),put(),remove()方法时,相对应的会调用CacheStore的load(),write()和delete()方法,当处理单个缓存条目时,这些方法会用于通读和通写处理。
loadAll(), writeAll(), deleteAll()
当调用IgniteCache接口的getAll(),putAll(),removeAll()方法时,相对应的会调用CacheStore的loadAll(),writeAll()和deleteAll()方法,当处理多个缓存条目时,这些方法会用于通读和通写处理,它们通常用批量操作的方式实现以提高性能。
注意
CacheStoreAdapter提供了loadAll(),writeAll()和deleteAll()方法的默认实现,它只是简单地对键进行一个个地迭代。
sessionEnd()
Ignite有一个存储会话的概念,它可以跨越不止一个CacheStore操作,会话对于事务非常有用。
对于原子化的缓存,sessionEnd()方法会在每个CacheStore方法完成之后被调用,对于事务化的缓存,不管是在底层持久化存储进行提交或者回滚多个操作,sessionEnd()方法都会在每个事务结束后被调用。
注意
CacheStoreAdapater提供了sessionEnd()方法的默认的空实现。
CacheStoreSession
CacheStoreSession的主要目的是当CacheStore用于事务中时在多个存储操作中持有一个上下文。比如,如果使用JDBC,可以通过CacheStoreSession.attach()方法保存数据库的连接,然后可以在CacheStore.sessionEnd(boolean)方法中提交这个连接。
CacheStoreSession可以通过@GridCacheStoreSessionResource注解注入自定义的CacheStore实现中。
示例
下面是几个不同场景的CacheStore的实现,注意有没有事务时的不同处理。
JDBC无事务:
public class CacheJdbcPersonStore extends CacheStoreAdapter<Long, Person> {
// This method is called whenever "get(...)" methods are called on IgniteCache.
@Override public Person load(Long key) {
try (Connection conn = connection()) {
try (PreparedStatement st = conn.prepareStatement("select * from PERSONS where id=?")) {
st.setLong(1, key);
ResultSet rs = st.executeQuery();
return rs.next() ? new Person(rs.getLong(1), rs.getString(2), rs.getString(3)) : null;
}
}
catch (SQLException e) {
throw new CacheLoaderException("Failed to load: " + key, e);
}
}
// This method is called whenever "put(...)" methods are called on IgniteCache.
@Override public void write(Cache.Entry<Long, Person> entry) {
try (Connection conn = connection()) {
// Syntax of MERGE statement is database specific and should be adopted for your database.
// If your database does not support MERGE statement then use sequentially update, insert statements.
try (PreparedStatement st = conn.prepareStatement(
"merge into PERSONS (id, firstName, lastName) key (id) VALUES (?, ?, ?)")) {
for (Cache.Entry<Long, Person> entry : entries) {
Person val = entry.getValue();
st.setLong(1, entry.getKey());
st.setString(2, val.getFirstName());
st.setString(3, val.getLastName());
st.executeUpdate();
}
}
}
catch (SQLException e) {
throw new CacheWriterException("Failed to write [key=" + key + ", val=" + val + ']', e);
}
}
// This mehtod is called whenever "remove(...)" methods are called on IgniteCache.
@Override public void delete(Object key) {
try (Connection conn = connection()) {
try (PreparedStatement st = conn.prepareStatement("delete from PERSONS where id=?")) {
st.setLong(1, (Long)key);
st.executeUpdate();
}
}
catch (SQLException e) {
throw new CacheWriterException("Failed to delete: " + key, e);
}
}
// This method is called whenever "loadCache()" and "localLoadCache()"
// methods are called on IgniteCache. It is used for bulk-loading the cache.
// If you don't need to bulk-load the cache, skip this method.
@Override public void loadCache(IgniteBiInClosure<Long, Person> clo, Object... args) {
if (args == null || args.length == 0 || args[0] == null)
throw new CacheLoaderException("Expected entry count parameter is not provided.");
final int entryCnt = (Integer)args[0];
try (Connection conn = connection()) {
try (PreparedStatement st = conn.prepareStatement("select * from PERSONS")) {
try (ResultSet rs = st.executeQuery()) {
int cnt = 0;
while (cnt < entryCnt && rs.next()) {
Person person = new Person(rs.getLong(1), rs.getString(2), rs.getString(3));
clo.apply(person.getId(), person);
cnt++;
}
}
}
}
catch (SQLException e) {
throw new CacheLoaderException("Failed to load values from cache store.", e);
}
}
// Open JDBC connection.
private Connection connection() throws SQLException {
// Open connection to your RDBMS systems (Oracle, MySQL, Postgres, DB2, Microsoft SQL, etc.)
// In this example we use H2 Database for simplification.
Connection conn = DriverManager.getConnection("jdbc:h2:mem:example;DB_CLOSE_DELAY=-1");
conn.setAutoCommit(true);
return conn;
}
}
JDBC有事务:
public class CacheJdbcPersonStore extends CacheStoreAdapter<Long, Person> {
/** Auto-injected store session. */
@CacheStoreSessionResource
private CacheStoreSession ses;
// Complete transaction or simply close connection if there is no transaction.
@Override public void sessionEnd(boolean commit) {
try {
Connection conn = ses.getAttached();
if (conn != null && ses.isWithinTransaction()) {
if (commit)
conn.commit();
else
conn.rollback();
}
}
catch (SQLException e) {
throw new CacheWriterException("Failed to end store session.", e);
}
}
// This method is called whenever "get(...)" methods are called on IgniteCache.
@Override public Person load(Long key) {
try {
Connection conn = connection();
try (PreparedStatement st = conn.prepareStatement("select * from PERSONS where id=?")) {
st.setLong(1, key);
ResultSet rs = st.executeQuery();
return rs.next() ? new Person(rs.getLong(1), rs.getString(2), rs.getString(3)) : null;
}
}
catch (SQLException e) {
throw new CacheLoaderException("Failed to load: " + key, e);
}
}
// This method is called whenever "put(...)" methods are called on IgniteCache.
@Override public void write(Cache.Entry<Long, Person> entry) {
try {
Connection conn = connection();
// Syntax of MERGE statement is database specific and should be adopted for your database.
// If your database does not support MERGE statement then use sequentially update, insert statements.
try (PreparedStatement st = conn.prepareStatement(
"merge into PERSONS (id, firstName, lastName) key (id) VALUES (?, ?, ?)")) {
for (Cache.Entry<Long, Person> entry : entries) {
Person val = entry.getValue();
st.setLong(1, entry.getKey());
st.setString(2, val.getFirstName());
st.setString(3, val.getLastName());
st.executeUpdate();
}
}
}
catch (SQLException e) {
throw new CacheWriterException("Failed to write [key=" + key + ", val=" + val + ']', e);
}
}
// This mehtod is called whenever "remove(...)" methods are called on IgniteCache.
@Override public void delete(Object key) {
try {
Connection conn = connection();
try (PreparedStatement st = conn.prepareStatement("delete from PERSONS where id=?")) {
st.setLong(1, (Long)key);
st.executeUpdate();
}
}
catch (SQLException e) {
throw new CacheWriterException("Failed to delete: " + key, e);
}
}
// This method is called whenever "loadCache()" and "localLoadCache()"
// methods are called on IgniteCache. It is used for bulk-loading the cache.
// If you don't need to bulk-load the cache, skip this method.
@Override public void loadCache(IgniteBiInClosure<Long, Person> clo, Object... args) {
if (args == null || args.length == 0 || args[0] == null)
throw new CacheLoaderException("Expected entry count parameter is not provided.");
final int entryCnt = (Integer)args[0];
try {
Connection conn = connection();
try (PreparedStatement st = conn.prepareStatement("select * from PERSONS")) {
try (ResultSet rs = st.executeQuery()) {
int cnt = 0;
while (cnt < entryCnt && rs.next()) {
Person person = new Person(rs.getLong(1), rs.getString(2), rs.getString(3));
clo.apply(person.getId(), person);
cnt++;
}
}
}
}
catch (SQLException e) {
throw new CacheLoaderException("Failed to load values from cache store.", e);
}
}
// Opens JDBC connection and attaches it to the ongoing
// session if within a transaction.
private Connection connection() throws SQLException {
if (ses.isWithinTransaction()) {
Connection conn = ses.getAttached();
if (conn == null) {
conn = openConnection(false);
// Store connection in the session, so it can be accessed
// for other operations within the same transaction.
ses.attach(conn);
}
return conn;
}
// Transaction can be null in case of simple load or put operation.
else
return openConnection(true);
}
// Opens JDBC connection.
private Connection openConnection(boolean autocommit) throws SQLException {
// Open connection to your RDBMS systems (Oracle, MySQL, Postgres, DB2, Microsoft SQL, etc.)
// In this example we use H2 Database for simplification.
Connection conn = DriverManager.getConnection("jdbc:h2:mem:example;DB_CLOSE_DELAY=-1");
conn.setAutoCommit(autocommit);
return conn;
}
}
JDBC批量操作:
public class CacheJdbcPersonStore extends CacheStoreAdapter<Long, Person> {
// Skip single operations and open connection methods.
// You can copy them from jdbc non-transactional or jdbc transactional examples.
...
// This method is called whenever "getAll(...)" methods are called on IgniteCache.
@Override public Map<K, V> loadAll(Iterable<Long> keys) {
try (Connection conn = connection()) {
try (PreparedStatement st = conn.prepareStatement(
"select firstName, lastName from PERSONS where id=?")) {
Map<K, V> loaded = new HashMap<>();
for (Long key : keys) {
st.setLong(1, key);
try(ResultSet rs = st.executeQuery()) {
if (rs.next())
loaded.put(key, new Person(key, rs.getString(1), rs.getString(2));
}
}
return loaded;
}
}
catch (SQLException e) {
throw new CacheLoaderException("Failed to loadAll: " + keys, e);
}
}
// This method is called whenever "putAll(...)" methods are called on IgniteCache.
@Override public void writeAll(Collection<Cache.Entry<Long, Person>> entries) {
try (Connection conn = connection()) {
// Syntax of MERGE statement is database specific and should be adopted for your database.
// If your database does not support MERGE statement then use sequentially update, insert statements.
try (PreparedStatement st = conn.prepareStatement(
"merge into PERSONS (id, firstName, lastName) key (id) VALUES (?, ?, ?)")) {
for (Cache.Entry<Long, Person> entry : entries) {
Person val = entry.getValue();
st.setLong(1, entry.getKey());
st.setString(2, val.getFirstName());
st.setString(3, val.getLastName());
st.addBatch();
}
st.executeBatch();
}
}
catch (SQLException e) {
throw new CacheWriterException("Failed to writeAll: " + entries, e);
}
}
// This method is called whenever "removeAll(...)" methods are called on IgniteCache.
@Override public void deleteAll(Collection<Long> keys) {
try (Connection conn = connection()) {
try (PreparedStatement st = conn.prepareStatement("delete from PERSONS where id=?")) {
for (Long key : keys) {
st.setLong(1, key);
st.addBatch();
}
st.executeBatch();
}
}
catch (SQLException e) {
throw new CacheWriterException("Failed to deleteAll: " + keys, e);
}
}
}
# 4.8.原生持久化和第三方持久化一起使用
从2.4版本开始,在一个集群中,Ignite支持原生持久化和第三方持久化的共存,如果启用了第三方持久化,Ignite会尽力保证两者之间的一致性。
但是,当使用事务且在事务提交期间,如果一个分区对应的所有节点故障(或者整个集群故障),数据可能会不一致。根据时间节点,第三方持久化和原生持久化的事务状态可能有所不同。
警告
Ignite无法保证原生持久化和第三方持久化之间的严格一致性,因为目前的CacheStore接口还不支持二阶段提交协议。
在恢复时,必须对两个存储的提交日志进行比较。不一致时,相应的缺失事务要么重做要么回滚。
# 5.基线拓扑
# 5.1.概述
如果启用了原生持久化,Ignite引入了一个基线拓扑的概念,它表示集群中将数据持久化到磁盘的一组服务端节点。
通常,打开原生持久化第一次启动集群后,集群处于非激活状态,无法进行任何CRUD操作。比如,如果尝试执行一个SQL或者键-值操作,会抛出一个异常,如下图所示:

这样做是为了避免可能的性能、可用性和一致性问题,如果集群正在重启,然后应用就开始修改持久化在还未加入集群的节点的数据,因此,需要为开启持久化的集群定义一个基线拓扑,之后,Ignite就可以手工或者自动地维护它,下面会看这个概念的细节以及如何使用。
# 5.2.基线拓扑是什么
基线拓扑是一组Ignite服务端节点,目的是同时在内存以及原生持久化中存储数据。基线拓扑中的节点在功能方面不受限制,并且作为数据和计算的容器,在行为上也和普通的服务端节点一样。
另外,部分节点不属于基线拓扑,也是可以的,比如:
- 服务端节点要么在内存中存储数据,要么在第三方数据库,比如RDBMS或者NoSQL中持久化数据;
- 客户端节点也不在基线拓扑中,因为它们不持有共享数据。
基线拓扑的目的是:
- 如果节点重启,避免不必要的数据再平衡。比如,每个节点重启都会触发两个再平衡事件,一个是节点停止,一个是节点重新加入集群,这会导致集群资源的无效利用;
- 集群重启后,如果基线拓扑中的所有节点都已经加入,那么集群会被自动激活。
深入了解基线拓扑
如果要深入了解基线拓扑和集群自动激活的细节,可以看这个Wiki页面。
打开持久化之后,集群第一次启动是没有配置基线拓扑的,这是唯一一个需要人工干预的时间点。因此,当所有属于基线拓扑的节点都启动运行之后,就可以通过代码或者命令行工具进行配置了,之后Ignite就会自动地处理集群的激活过程。
在整个生命周期中,同样的工具和API也可以对基线拓扑进行调整。通过配置让更多或者更少的节点存储数据,就可以对已有的基线拓扑进行缩放,下面的章节会说明如何使用这些API和工具。
# 5.3.配置基线拓扑
基线拓扑只能在一个激活的集群上进行配置,因此首先要对集群进行激活,然后才能配置基线拓扑。
集群激活
要让开启了原生持久化的集群可以自动激活,那么第一次要对集群做一次手工激活,目前支持4种方式:通过代码、命令行、REST API或者第三方工具,下面会详细介绍。
当集群第一次激活之后,基线拓扑就从当前的服务端节点中自动建立起来,这步完成之后,与构成基线拓扑有关的节点信息就会持久化到磁盘。之后即使关闭或者重启集群,只要基线拓扑中的节点启动运行,集群都会自动地激活。
Java:
// Connect to the cluster.
Ignite ignite = Ignition.start();
// Activate the cluster. Automatic topology initialization occurs
// only if you manually activate the cluster for the very first time.
ignite.cluster().active(true);
Linux:
## Run this command from your `$IGNITE_HOME/bin` folder
bin/control.sh --activate
Windows:
## Run this command from your `$IGNITE_HOME/bin` folder
bin\control.bat --activate
REST
## Replace [host] and [port] with actual values.
https://[host]:[port]/ignite?cmd=activate
有关如何通过REST API来对集群进行激活/冻结的更新信息,可以看这个文档。
通过代码配置基线拓扑
如上所述,手工激活集群之后基线拓扑就会自动初始化,使用IgniteCluster.activate()方法,可以通过代码对集群进行激活,然后可以使用IgniteCluster.setBaseLineTopogy()对已有的基线拓扑进行调整,注意,必须激活集群之后才能调用这个方法。
将所有的服务端节点配置为基线拓扑:
// Connect to the cluster.
Ignite ignite = Ignition.start();
// Activate the cluster.
// This is required only if the cluster is still inactive.
ignite.cluster().active(true);
// Get all server nodes that are already up and running.
Collection<ClusterNode> nodes = ignite.cluster().forServers().nodes();
// Set the baseline topology that is represented by these nodes.
ignite.cluster().setBaselineTopology(nodes);
将整个集群都配置为基线拓扑:
// Connect to the cluster.
Ignite ignite = Ignition.start();
// Activate the cluster.
// This is required only if the cluster is still inactive.
ignite.cluster().active(true)
// Set the baseline topology to a specific Ignite cluster topology version.
ignite.cluster().setBaselineTopology(2);
如果之后更新了基线拓扑,比如说往其中加入了新的节点,那么Ignite就会在所有新的基线拓扑节点中对数据进行再平衡。
通过命令行配置基线拓扑
同样可以使用命令行工具在命令行中对集群进行激活/冻结以及对基线拓扑进行配置。
获取节点的一致性ID
定义和调整基线拓扑的命令需要提供一个节点的一致性ID,这个ID是在节点第一次启动时赋予节点的,并且在重启之后还会复用。要获取当前运行节点的一致性ID,可以在$IGNITE_HOME/bin文件夹中执行./control.sh --baseline命令来获取与集群基线拓扑有关的信息,比如:
Linux:
bin/control.sh --baseline
Windows:
bin\control.bat --baseline
输出大致如下:
Cluster state: active
Current topology version: 4
Baseline nodes:
ConsistentID=cde228a8-da90-4b74-87c0-882d9c5729b7, STATE=ONLINE
ConsistentID=dea120d9-3157-464f-a1ea-c8702de45c7b, STATE=ONLINE
ConsistentID=fdf68f13-8f1c-4524-9102-ac2f5937c62c, STATE=ONLINE
--------------------------------------------------------------------------------
Number of baseline nodes: 3
Other nodes:
ConsistentID=5d782f5e-0d47-4f42-aed9-3b7edeb527c0
上面的信息显示了:集群的状态、拓扑的版本、属于和不属于基线拓扑一部分的节点及其一致性ID。
配置基线拓扑
要将一组节点组成基线拓扑,可以使用./control.sh --baseline set命令再加上节点一致性ID的列表:
Linux:
bin\control.sh --baseline set consistentId1[,consistentId2,....,consistentIdN]
Windows:
bin\control.bat --baseline set {consistentId1[,consistentId2,....,consistentIdN]}
另外,也可以使用数值化的集群拓扑版本来配置基线:
Linux:
bin/control.sh --baseline version topologyVersion
Windows:
bin\control.bat --baseline version {topologyVersion}
在上面这个命令中,需要将topologyVersion替换为实际的拓扑版本。
往拓扑中添加节点
要将节点加进已有的基线拓扑,可以使用./control.sh --baseline add命令,它会接受逗号分隔的、待加入拓扑的节点的一致性ID列表。
Linux:
bin/control.sh --baseline add consistentId1[,consistentId2,....,consistentIdN]
Windows:
bin\control.bat --baseline add {consistentId1[,consistentId2,....,consistentIdN]}
比如,下面的命令会将一致性ID为5d782f5e-0d47-4f42-aed9-3b7edeb527c0的节点加入基线拓扑:
Linux:
bin/control.sh --baseline add 5d782f5e-0d47-4f42-aed9-3b7edeb527c0
Windows:
bin\control.bat --baseline add eb05ce3d-f246-4b7b-8e80-91155774c20b
从拓扑中删除节点
要从拓扑中删除节点,使用./control.sh --baseline remove命令,语法如下:
Linux:
bin/control.sh --baseline remove consistentId1[,consistentId2,....,consistentIdN]
Windows:
bin\control.bat --baseline remove {consistentId1[,consistentId2,....,consistentIdN]}
注意,计划要从拓扑中删除的节点首先要停止,否则会抛出一个信息类似Failed to remove nodes from baseline的异常,下面的示例显示如何删除一致性ID为fdf68f13-8f1c-4524-9102-ac2f5937c62c的节点(假定该节点已经停止):
Linux:
bin/control.sh --baseline remove fdf68f13-8f1c-4524-9102-ac2f5937c62c
Windows:
bin\control.bat --baseline remove eb05ce3d-f246-4b7b-8e80-91155774c20b
集群激活命令行工具
Ignite提供了control.sh|bat脚本,位于$IGNITE_HOME/bin文件夹,它是作为从命令行激活/冻结集群的工具,也可以用于配置基线拓扑。control.sh|bat支持如下的命令:
| 命令 | 描述 |
|---|---|
--activate | 激活集群 |
--deactivate | 冻结集群 |
--host {ip} | 集群IP地址,默认值为127.0.0.1 |
--port {port} | 要连接的端口,默认值为11211 |
--state | 输出当前的集群状态 |
--baseline | 如果没有任何参数,该命令输出该集群的基线拓扑信息。它支持如下的参数:add、remove、set和version |
--baseline add | 往基线拓扑中添加节点 |
--baseline remove | 从基线拓扑中删除节点 |
--baseline set | 配置基线拓扑 |
--baseline version | 基于版本配置基线拓扑 |
可以使用./control.sh --help查看帮助。
使用第三方工具进行激活
要激活集群以及配置基线拓扑,还可以使用这个第三方工具。
# 5.4.使用场景
设计基线拓扑的目的是避免不必要的分区重新分配和数据的再平衡。这意味着,相对于特定事件(比如节点加入或者离开集群),决定什么时候对基线拓扑进行调整(会触发数据再平衡),变成了IT管理员的职责。如上所述,这可以通过control.sh|bat命令手工完成,也可以通过一些外部的自动化工具实现(比如一个检查运行Ignite节点的主机健康状态的系统,会从基线拓扑中移除不稳定或者故障的节点)。
再平衡和非基线服务端节点
只存储在内存中(或内存中和第三方持久化)中的数据再平衡会自动触发,不需要任何人工干预。
下面会讨论若干个常见场景,即如果开启了Ignite原生持久化时的基线拓扑管理问题。
集群第一次启动
场景:集群第一次启动,没有数据预加载。
步骤:
- 不管什么方式,启动所有节点,比如通过
ignite.sh,这时:
- 集群为非激活状态,无法处理来自客户端的和数据相关的请求(键-值、SQL、扫描查询等);
- 基线拓扑未配置。
- 通过调用
control.sh --activate激活集群,或者上面文档描述的其它方式,做了如下事情:
- 将正在运行的服务端节点全部加入基线拓扑;
- 将集群切换为激活状态,允许交互。
注意
control.sh --activate命令只在第一次激活时配置基线拓扑,如果已经配置了基线拓扑,则该命令无效。
注意
集群激活之后,除非手工冻结或者所有节点停止,否则会一直处于激活状态,单节点的退出不会影响整个集群的可用性。
集群重启
场景:所有节点都需要重启(比如执行系统或者硬件升级)。
步骤:
- 正常停止所有的节点;
- 执行升级;
- 启动所有的节点,基线拓扑中的所有节点都启动之后,集群会被自动激活;
启用持久化后,使用新的Ignite版本升级集群
场景:所有节点都需要使用新的Ignite版本重启,然后数据从Ignite持久化重新加载。
步骤:
- 正常停止所有的节点;
- 配置
storagePath、walPath和walArchivePath属性,如果这些属性在当前版本的Ignite中已经显式指定,则在新版本的配置中需要保留,如果当前版本未指定,那么需要提供这些属性的默认值; - 从
{current_Ignite_version}/work目录复制binary_meta和marshaller文件夹到{new_Ignite_version}/work文件夹,如果当前版本的Ignite通过IgniteConfiguration.workDirectory修改了工作目录,那么新版本的Ignite也要将该属性修改为相同的值; - 启动所有的节点。基线拓扑中的所有节点都启动成功后,集群会自动激活。
添加新的节点
场景:添加一个新的空节点(没有持久化的数据)。
步骤:
- 正常启动节点,这时:
- 集群仍然是激活状态;
- 新节点已经加入集群,但是未加入基线拓扑;
- 新节点可以用于存储不使用持久化的缓存/表的数据;
- 新节点无法在持久化中存储缓存/表的数据;
- 新节点可用于计算。
- 如果希望该节点可以在持久化中存储数据,那么需要通过
control.sh --baseline add <节点的一致性ID>或者其它方式将其加入基线拓扑,然后:
- 基线拓扑会调整,包含新的节点;
- 在新的基线拓扑中进行数据再平衡。
节点重启
场景:节点需要重启,时间很短。
步骤:
- 停止节点;
- 重启节点,之后:
- 基线拓扑没有必要变化,重启之后节点仍然保留它的
consistentId,因此集群以及基线拓扑只是将该节点收回; - 在节点下线期间如果有数据更新,修改的分区的数据会从其它节点复制到重启后的节点。
注意
如果节点重启时间很短,那么不要去碰基线拓扑是安全的(也是高效的),因此也不需要触发再平衡。
但是如果时间很长,就需要从基线拓扑中删除该节点,然后触发再平衡以避免可能的数据丢失,因为在这期间另一个存储主备数据的节点发生故障也是可能的。
基线节点删除
场景:基线节点需要停止,或者除了严重的故障,然后需要从集群中永久删除,或者需要下线很长时间。
步骤:
- 停止节点(如果还没有停止/故障),这时:
- 集群仍然处于激活状态;
- 停止的节点仍然在基线拓扑中,状态为失去连接;
- 保存在内存中的缓存/表中的数据(或者开启了第三方持久化的缓存/表)会进行数据再平衡;
- 如果开启了原生持久化,不会触发再平衡,在停止的节点恢复在线或者从基线拓扑中删除之前,复制因子(副本数量)都会减小。
注意
长时间降低复制因子可能是危险的。例如,考虑具有一个备份的缓存,如果一个节点故障,则没有数据丢失(因为一个副本仍然在线),但是需要尽快触发再平衡,因为如果另一个节点在重新平衡完成之前故障,则可能导致数据丢失。
- 通过调用
contol.sh --baseline remove <node's consistentId>或者其它方式将节点从基线拓扑中删除,之后:
- 基线拓扑发生变更,排除了停止的节点;
- 开启原生持久化的缓存/表,会按照配置好的复制因子(或者副本数量)进行数据再平衡。
注意
节点从基线拓扑中删除之后,它就无法加入集群然后持有删除之前存储在持久化中的数据。通过在基线拓扑中删除一个节点,可以确定即使该节点重启,也无法再使用存储在该节点上的数据。
非基线节点删除和故障处理
不添加到基线拓扑的服务端节点不需要IT管理员的额外干预来触发数据再平衡。由于这些节点只在内存(或内存和第三方数据库)中存储数据,所以再平衡会自动触发。
# 5.5.编程方式触发再平衡
如前述的节点重启和节点删除章节所述,基线拓扑可能会在一个较长的时间段内维持复制因子(副本数量)的降低,因此如果预期下线时间足够长,就需要从基线拓扑中删除该节点,然后触发再平衡以避免可能的数据丢失,因为其它节点上存储的主备数据可能丢失。
从基线拓扑中手动删除节点之后,就可以触发再平衡以及恢复复制因子。通过control.sh脚本以及监控工具,可以自动地执行删除操作,另外,使用如下的模板代码,也可以通过编程方式触发再平衡:
import java.util.Set;
import java.util.stream.Collectors;
import org.apache.ignite.Ignite;
import org.apache.ignite.cluster.BaselineNode;
import org.apache.ignite.cluster.ClusterNode;
import org.apache.ignite.events.DiscoveryEvent;
import org.apache.ignite.events.EventType;
import org.apache.ignite.internal.IgniteEx;
import org.apache.ignite.internal.processors.timeout.GridTimeoutObjectAdapter;
public class BaselineWatcher {
/** Ignite. */
private final IgniteEx ignite;
/** BLT change delay millis. */
private final long bltChangeDelayMillis;
/**
* @param ignite Ignite.
*/
public BaselineWatcher(Ignite ignite, long bltChangeDelayMillis) {
this.ignite = (IgniteEx)ignite;
this.bltChangeDelayMillis = bltChangeDelayMillis;
}
/**
*
*/
public void start() {
ignite.events().localListen(event -> {
DiscoveryEvent e = (DiscoveryEvent)event;
Set<Object> aliveSrvNodes = e.topologyNodes().stream()
.filter(n -> !n.isClient())
.map(ClusterNode::consistentId)
.collect(Collectors.toSet());
Set<Object> baseline = ignite.cluster().currentBaselineTopology().stream()
.map(BaselineNode::consistentId)
.collect(Collectors.toSet());
final long topVer = e.topologyVersion();
if (!aliveSrvNodes.equals(baseline))
ignite.context().timeout().addTimeoutObject(new GridTimeoutObjectAdapter(bltChangeDelayMillis) {
@Override public void onTimeout() {
if (ignite.cluster().topologyVersion() == topVer)
ignite.cluster().setBaselineTopology(topVer);
}
});
return true;
}, EventType.EVT_NODE_FAILED, EventType.EVT_NODE_LEFT, EventType.EVT_NODE_JOINED);
}
}
# 6.交换空间
# 6.1.概述
如果使用纯内存存储,随着数据量的大小逐步达到物理内存大小,可能导致内存溢出。要避免这种情况的发生,可能的想法包括开启原生的持久化或者使用第三方的持久化。但是,如果不想使用原生或者第三方的持久化,还可以开启交换,这时,Ignite会将内存中的数据移动到磁盘上的交换空间,注意Ignite不会提供自己的交换空间实现,而是利用了操作系统(OS)提供的交换功能。
打开交换空间之后,Ignite会将数据存储在内存映射文件(MMF)中,操作系统会根据内存使用情况,将其内容交换到磁盘,但是这时数据访问的性能会下降,另外,还没有数据持久性保证,这意味着交换空间中的数据只在节点在线期间才可用。一旦节点停止,所有数据都会丢失。因此,应该使用交换空间作为内存的扩展,以便留出足够的时间向集群中添加更多的节点,以便数据重新分布并避免集群未及时扩容导致内存溢出的错误(OOM)发生。
注意
建议使用Ignite的原生持久化,它容量超过了RAM并且保留了持久性。
# 6.2.配置
数据区的maxSize定义了区域的整体最大值,如果数据量达到了maxSize,然后既没有使用原生持久化,也没有使用第三方数据库,那么可能会抛出内存溢出异常。使用交换可以避免这种情况的发生,这时:
- 配置
maxSize的值大于内存大小,这时操作系统就会使用交换; - 配置
DataRegionConfiguration.swapPath属性来启用交换。
XML:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<!-- Durable memory configuration. -->
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="dataRegionConfigurations">
<list>
<!--
Defining a data region that will consume up to 500 MB of RAM
with swap enabled.
-->
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<!-- Custom region name. -->
<property name="name" value="500MB_Region"/>
<!-- 100 MB initial size. -->
<property name="initialSize" value="#{100L * 1024 * 1024}"/>
<!-- Setting region max size equal to physical RAM size(5 GB). -->
<property name="maxSize" value="#{5L * 1024 * 1024 * 1024}"/>
<!-- Enabling swap space for the region. -->
<property name="swapPath" value="/path/to/some/directory"/>
</bean>
</list>
</property>
</bean>
</property>
<!-- Other configurations. -->
</bean>
Java:
// Ignite configuration.
IgniteConfiguration cfg = new IgniteConfiguration();
// Durable Memory configuration.
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
// Creating a new data region.
DataRegionConfiguration regionCfg = new DataRegionConfiguration();
// Region name.
regionCfg.setName("500MB_Region");
// Setting initial RAM size.
regionCfg.setInitialSize(100L * 1024 * 1024);
// Setting region max size equal to physical RAM size(5 GB)
regionCfg.setMaxSize(5L * 1024 * 1024 * 1024);
// Enable swap space.
regionCfg.setSwapPath("/path/to/some/directory");
// Setting the data region configuration.
storageCfg.setDataRegionConfigurations(regionCfg);
// Applying the new configuration.
cfg.setDataStorageConfiguration(storageCfg);
可能的数据丢失
虽然交换空间位于磁盘上,但不要认为它可以替代原生持久化,交换空间中的数据只在节点在线期间可用。一旦节点停止,所有数据都会丢失。要一直保证数据的可用性,要么使用原生持久化,要么使用第三方持久化。