
数据分区
数据分区是划分大型数据集为更小的块,并在所有服务端节点之间平衡分布的一种方法。
1.数据分区方式
创建表时,会被分配到一个分布区,根据分布区参数,数据被分成多个PARTITIONS,称为分区,然后整个集群中存储REPLICAS份。每个分区由固定范围中的一个数字标识(默认为0到24)。每个分区称为一个副本,然后将尽可能地存储在不同的节点上。Ignite使用公平分区分布算法,它会存储关于分区分布的信息,并使用这些信息来分配新的分区。此信息保留在集群元存储中,必要时会重新计算。
创建分区及其副本时,会根据DATA_NODES_FILTER参数和分区分布算法将其分布在分布区对应的可用集群节点上。因此,每条数据都映射到拥有相应分区的节点列表,并存储在这些节点上。添加数据时,数据在分区之间均匀分布。 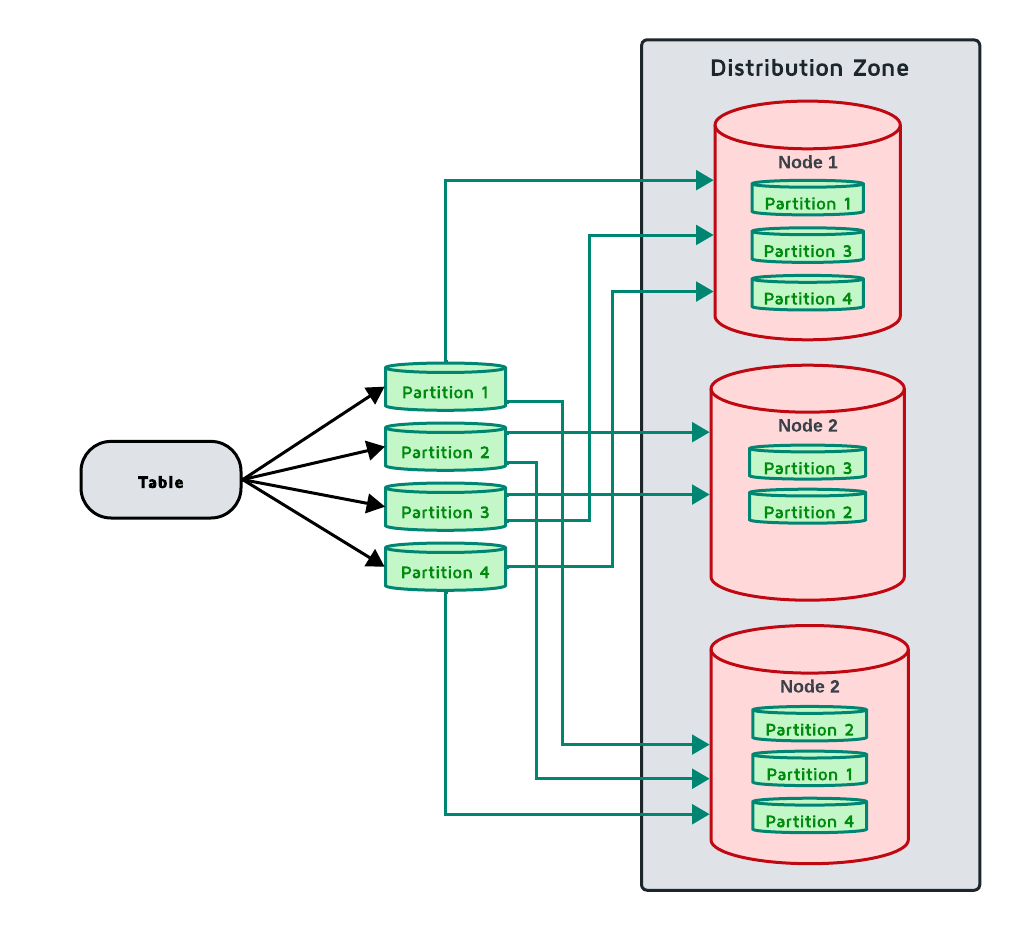 节点将分区存储在由
节点将分区存储在由 ignite.system.partitionsBasePath 指定的文件夹中,或者在 work/partitions 文件夹中。节点还将与分区有关的 Raft 日志存储在由 ignite.system.partitionsLogPath 指定的文件夹中,这些日志包含有关 Raft 选举和共识的信息。
1.1.默认的分区号
创建分布区时,可以使用PARTITIONS参数手动设置分区数,例如:
CREATE ZONE IF NOT EXISTS exampleZone WITH STORAGE_PROFILES='default',PARTITIONS=10否则,Ignite 将自动计算分区数:
dataNodesCount * coresOnNode * 2 / replicas2.主副本和租约
一旦分区分布在节点上,Ignite 就会为表的所有分区生成复制组,每个组都会选举其领导者。为了线性化对分区的写入,Ignite 将每个分区的一个副本指定为主副本。
为了指定主副本,Ignite 采用了一种授予租约的流程。租约由租约安排驱动授予,并确定持有主副本的节点,称为租约持有者。授予租约后,有关租约的信息将写入元存储,并提供给集群中的所有节点。通常主副本将与复制组领导者相同。
已授予的租约有效期很短,每隔几秒钟就会延长一次,从而保持每个租约的连续性。租约在到期之前无法撤销。在特殊情况下(例如当主副本无法再用作主副本、租约持有者节点离线、复制组无法操作等)时,安排驱动会等待租约到期,然后启动新租约的协商。
只有主副本可以处理读写事务,可以使用只读事务从分区的其他副本中读取。
如果选择新副本来接收租约,它首先会确保其复制组中存储的数据是最新的。在复制组不再可用时(例如,节点意外离开集群,复制组失去多数),它会执行故障恢复过程,这时可能需要手动重置分区。
3.版本存储
当新数据写入分区时,Ignite不会立即删除旧数据。而是将旧数据存储在同一分区内的版本链中。
旧的版本只能通过只读事务访问,而最新版本可以通过任何事务访问。
旧的数据版本将一直保留,直到达到低水位线。低水位线默认为600000ms,不过可以在集群配置中更改。增加数据可用时间意味着旧数据版本将可用更长时间,但存储它们可能需要额外的存储空间,具体取决于集群负载。
以类似的方式,删除的表在达到低水位线之前,也不会从磁盘中删除,但是不能再写入这些表。如果只读事务在表被删除的时间戳之前读取数据,会成功,如果需要完成事务,则将延迟低水位线。
一旦达到低水位线,旧版本的数据将被视为垃圾,并在下次清理时由垃圾回收器清理。这些数据可能可用,也可能不可用,因为垃圾收集不是一个立即的过程。如果在达到低水位线之前启动了事务,则即使执行了垃圾回收,在事务结束之前,所需的数据将仍然可用,此外,Ignite会在清理数据之前检查集群上任何地方都不需要该旧数据。
4.分布重置
在表创建时间比较久的集群中,由于数据并置不佳,SQL查询性能可能会随着拓扑变化而恶化。要解决此问题,可以使用命令行工具或REST API重置(重新计算)分区分布。
提示
重置可能会导致分区再平衡,这可能需要很长时间。
5.分区再平衡
当集群大小发生变化时,Ignite会等待DATA_NODES_AUTO_ADJIST_SCALE_UP或DATA_NODES_ AUTO_ADJUST_SCALE_DOWN分布区属性中指定的超时,然后根据分区分布算法重新分发分区,并传输数据以使其与复制组保持最新。这个过程被称为数据再平衡。
18624049226
