# 安装
# 1.使用ZIP压缩包安装
# 1.1.环境要求
Apache Ignite官方在如下环境中进行了测试:
- JDK:Oracle JDK8、11或17,Open JDK8、11或17,IBM JDK8、11或17;
- OS:Linux(任何版本),Mac OS X(10.6及以上),Windows(XP及以上),Windows Server(2008及以上),Oracle Solaris;
- 网络:没有限制(建议10G甚至更快的网络带宽);
- 架构:x86,x64,SPARC,PowerPC。
# 1.2.使用ZIP压缩包安装
Ignite入门的最简单方式是使用每次版本发布生成的二进制压缩包:
- 下载最新版本的Ignite压缩包;
- 将该包解压到操作系统的一个文件夹;
- (可选)启用必要的模块;
- (可选)配置
IGNITE_HOME环境变量或者Windows的PATH指向Ignite的安装文件夹,路径不要以/(Windows为\)结尾。
# 2.使用Docker安装
# 2.1.注意事项
内存集群和持久化集群
在部署开启持久化的Ignite集群时,需要加载一个持久化卷或者本地目录。如果没有使用持久化卷,Ignite会将数据保存在容器内的文件系统,这意味着如果删除容器,数据也会丢失。
网络
Ignite的Docker镜像默认会暴露如下的端口:11211、47100、47500、49112。通过给docker run命令添加-p <port>参数,可以暴露更多的端口,比如要使用瘦客户端接入在容器中运行的Ignite节点,需要打开10800端口:
docker run -d -p 10800:10800 apacheignite/ignite
# 2.2.下载Ignite的Docker镜像
假定主机上已经安装好了Docker,那么可以使用如下命令拉取并运行Ignite的Docker镜像。
打开命令行终端,使用如下命令拉取Ignite的Docker镜像:
# Pull latest version
sudo docker pull apacheignite/ignite
默认会下载最新的版本,但是也可以下载指定的版本:
# Pull a specific Ignite version
sudo docker pull apacheignite/ignite:2.12.0
# 2.3.运行内存集群
在Docker容器中运行Ignite,需要使用docker run命令:
# Run the latest version
sudo docker run -d apacheignite/ignite
该命令会启动单个Ignite节点。
使用如下命令,可以启动指定版本的Ignite:
# Run a specific Ignite version
sudo docker run -d apacheignite/ignite:2.12.0
# 2.4.运行持久化集群
如果使用原生持久化,Ignite会将用户数据保存在容器文件系统的默认工作目录中({IGNITE_HOME}/work),如果重启容器,该目录会被删除,未来避免这个问题,可以这样做:
- 使用一个持久化卷来保存数据;
- 加载一个本地目录。
# 2.4.1.使用持久化卷
使用如下命令可以创建一个持久化卷:
sudo docker volume create persistence-volume
运行Ignite的Docker镜像时可以将这个卷加载到一个指定的目录,该目录可以通过两个方式传给Ignite:
- 使用
IGNITE_WORK_DIR系统属性; - 在节点配置文件中指定。
如下命令会启动一个Ignite的Docker镜像,通过系统属性将工作目录传给Ignite:
docker run -d \
-v storage-volume:/storage \
-e IGNITE_WORK_DIR=/storage \
apacheignite/ignite
# 2.4.2.使用本地目录
如果不创建持久化卷,还可以将一个本地目录加载到运行Ignite镜像的容器,Ignite会使用这个目录来保存持久化数据。当使用同一个命令重启容器后,Ignite会从该目录加载数据。
mkdir work_dir
docker run -d \
-v ${PWD}/work_dir:/storage \
-e IGNITE_WORK_DIR=/storage \
apacheignite/ignite
-v选项会将一个本地目录加载到容器的/storage路径下面,-e IGNITE_WORK_DIR=/storage选项会通知Ignite将该文件夹用作工作目录。
# 2.5.提供配置文件
运行镜像时,会使用默认的配置文件启动节点,但可以通过CONFIG_URI环境变量传递一个自定义的配置文件:
docker run -d \
-e CONFIG_URI=http://myserver/config.xml \
apacheignite/ignite
还可以使用来自本地文件系统中的一个文件,首先要使用-v选项将该文件加载到容器中的特定路径,然后在CONFIG_URI中使用这个路径:
docker run -d \
-v /local/dir/config.xml:/config-file.xml \
-e CONFIG_URI=/config-file.xml \
apacheignite/ignite
# 2.6.部署自己的库文件
启动节点时,会将{IGNITE_HOME}/libs下面发现的所有库文件(忽略optional目录)都加载到类路径中,如果希望部署自己的库文件,可以通过-v选项,将本地主机上的一个目录加载到容器中/opt/ignite/apache-ignite/libs/下面的某个路径上。
如下命令会将主机上的一个目录加载到容器的libs/user_libs,该目录下的所有库文件都会加载到节点的类路径中:
docker run -v /local_path/to/dir_with_libs/:/opt/ignite/apache-ignite/libs/user_libs apacheignite/ignite
如果库文件可以通过URL进行访问,另一个选项是使用EXTERNAL_LIBS变量:
docker run -e "EXTERNAL_LIBS=http://url_to_your_jar" apacheignite/ignite
# 2.7.启用模块
要启用某模块,可以在OPTION_LIBS系统变量中指定他们的名字,如下所示:
sudo docker run -d \
-e "OPTION_LIBS=ignite-rest-http" \
apacheignite/ignite
Ignite的Docker镜像默认会启用下面的模块:
ignite-log4j2;ignite-spring;ignite-indexing。
# 2.8.环境变量
下面的参数可以以环境变量的形式传给Docker容器:
| 名称 | 描述 | 默认 |
|---|---|---|
CONFIG_URI | Ignite配置文件的URL(也可以相对于类路径的META-INF文件夹),下载的配置文件会保存于./ignite-config.xml | 无 |
OPTION_LIBS | 会被包含在类路径中的可选库 | ignite-log4j2, ignite-spring,ignite-indexing |
JVM_OPTS | 传递给Ignite实例的JVM参数。 | 无 |
EXTERNAL_LIBS | 库文件URL列表 | 无 |
# 3.使用DEB/RPM包安装
# 3.1.概述
确认Linux发行版
Ignite的RPM/DEB包,在如下的Linux发行版中进行了验证:
- Ubuntu 14.10及以上的版本;
- Debian 9.3及以上的版本;
- CentOS 7.4.1708及以上的版本
只要包可以安装,其它的发行版也是支持的。
# 3.2.仓库的配置
配置Ignite的RPM或者DEB仓库,如下所示(如果必要,需要根据提示接受GPG密钥),其中包括了特定发行版的配置:
Debian:
sudo apt update
sudo apt install gnupg ca-certificates --no-install-recommends -y
# 3.3.Ignite的安装
安装Ignite的最新版:
安装后的结构如下:
| 文件夹 | 映射至 | 描述 |
|---|---|---|
/usr/share/apache-ignite | Ignite安装的根目录 | |
/usr/share/apache-ignite/bin | 二进制文件文件夹(脚本以及可执行程序) | |
/etc/apache-ignite | /usr/share/apache-ignite/config | 默认配置文件 |
/var/log/apache-ignite | /var/lib/apache-ignite/log | 日志目录 |
/usr/lib/apache-ignite | /usr/share/apache-ignite/libs | 核心和可选库 |
/var/lib/apache-ignite | /usr/share/apache-ignite/work | Ignite的工作目录 |
/usr/share/doc/latest/apache-ignite | 文档 | |
/usr/share/license/apache-ignite-<version> | 协议 | |
/etc/systemd/system | systemd服务配置 |
# 3.4.将Ignite作为服务
注意
如果运行于Windows10 WSL或者Docker,那么需要将Ignite作为一个独立的进程(而不是一个服务),具体可以看下面的章节。
用一个配置文件启动一个Ignite节点,可以这样做:sudo systemctl start apache-ignite@<config_name>,注意这里的<config_name>参数是相对于/etc/apache-ignite文件夹的。
运行Ignite服务:
sudo systemctl start apache-ignite@default-config.xml # start Ignite service
journalctl -fe # check logs
如果要开启随着系统启动而节点自动重启,如下:
sudo systemctl enable apache-ignite@<config name>
# 3.5.将Ignite作为独立进程
使用下面的命令可以将Ignite启动为一个独立的进程(先要切换到/usr/share/apache-ignite),如果要修改默认的配置,可以修改/etc/apache-ignite/default-config.xml文件。默认的配置会使用组播IP探测器,如果要使用静态IP探测器,需要修改默认的配置文件,具体参见TCP/IP发现。
首先,切换到ignite用户,如下:
sudo -u ignite /usr/bin/env bash # switch to ignite user
然后切换到Ignite的bin文件夹,启动一个节点:
# 3.6.在Windows10 WSL中运行Ignite
网络配置
在Windows 10 WSL环境下运行Ignite,需要对具有高级安全的Windows防御防火墙进行正确的配置:
- 运行
具有高级安全的Windows防御防火墙; - 选择左侧的
入站规则菜单; - 选择右侧的
新建规则菜单; - 选择
程序复选框然后点击下一步; - 在
程序路径字段中输入%SystemRoot%\System32\wsl.exe,然后点击下一步; - 选择
允许连接复选框,然后点击下一步; - 选择
域、私有和公开复选框,然后点击下一步; - 在
名字字段中输入名字(在描述字段中,也可以可选地写一段描述),然后点击完成。
这个配置好的规则将允许Windows 10 WSL环境中的Ignite节点暴露于局域网中。
启动Ignite集群
由于特殊的网络堆栈实现,如果要在一个Windows10 WSL环境中运行多个节点,需要对配置进行自定义(可以看下面的wsl-default-config),启动命令如下:bin/ignite.sh config/wsl-default-config.xml -J-DNODE=<00..99>。
wsl-default-config.xml:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="placeholderConfig" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"/>
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="localPort" value="475${NODE}"/>
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.multicast.TcpDiscoveryMulticastIpFinder">
<property name="addresses">
<list>
<value>127.0.0.1:47500..47599</value>
</list>
</property>
</bean>
</property>
</bean>
</property>
<property name="communicationSpi">
<bean class="org.apache.ignite.spi.communication.tcp.TcpCommunicationSpi">
<property name="localPort" value="481${NODE}"/>
</bean>
</property>
</bean>
</beans>
首先,以ignite用户登录,如下:
sudo -u ignite /usr/bin/env bash
然后转到Ignite的主文件夹,然后在本地启动希望数量的节点(最多100):
# Navigate to Ignite home folder
cd /usr/share/apache-ignite
# Run several local nodes
bin/ignite.sh config/wsl-default-config.xml -J-DNODE=00 &
bin/ignite.sh config/wsl-default-config.xml -J-DNODE=01 &
...
bin/ignite.sh config/wsl-default-config.xml -J-DNODE=99 &
# 4.Kubernetes
# 4.1.Kubernetes部署
Ignite集群可以容易地在Kubernetes环境中部署和维护,Kubernetes是一个开源的系统,可以自动化地部署、伸缩以及管理容器化的应用。
本章节会引导用户将Ignite部署进Kubernetes环境,还会涉及一些与Ignite有关的特殊性内容。
首先要确定Ignite的开发和使用方式:
- 如果使用纯内存方式或者作为第三方数据库(RDBMS, NoSQL)的缓存层,那么需要遵照
无状态部署的相关文档; - 如果Ignite作为内存数据库,并且开启了持久化,那么需要遵照
有状态部署的相关文档。
如果希望将Kubernetes部署在具体的云环境中,那么需要参照下面的文档:
Azure Kubernetes ServiceGoogle Kubernetes EngineAmazon EKS
# 4.2.常规配置
# 4.2.1.无状态部署
如果使用纯内存方式或者作为第三方数据库(RDBMS, NoSQL)的缓存层,那么需要将其按照无状态的解决方案进行部署。
# 4.2.1.1.要求
确保如下事项已经完成:
- 环境中已经部署了Kubernetes集群;
- 已经配置了RBAC授权;
- 已经部署了Ignite服务;
# 4.2.1.2.Kubernetes IP探测器
要开启Kubernetes环境下Ignite节点的自动发现,需要在IgniteConfiguration中启用TcpDiscoveryKubernetesIpFinder,下面会创建一个名为example-kube-rbac.xml的配置文件,然后像下面这样定义相关的配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util.xsd">
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.kubernetes.TcpDiscoveryKubernetesIpFinder">
<property name="namespace" value="ignite"/>
</bean>
</property>
</bean>
</property>
</bean>
</beans>
下面,就可以为Ignite Pod准备一套Kubernetes环境然后部署了。
# 4.2.1.3.Ignite Pod部署
最后,需要为Ignite Pod定义一个yaml格式配置文件。
ignite-deployment.yaml:
# An example of a Kubernetes configuration for Ignite pods deployment.
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
# Custom Ignite cluster's name.
name: ignite-cluster
spec:
# A number of Ignite pods to be started by Kubernetes initially.
replicas: 2
template:
metadata:
labels:
app: ignite
spec:
containers:
# Custom Ignite pod name.
- name: ignite-node
image: apacheignite/ignite:2.5.0
env:
- name: OPTION_LIBS
value: ignite-kubernetes
- name: CONFIG_URI
value: https://raw.githubusercontent.com/apache/ignite/master/modules/kubernetes/config/example-kube-persistence.xml
ports:
# Ports to open.
# Might be optional depending on your Kubernetes environment.
- containerPort: 11211 # REST port number.
- containerPort: 47100 # communication SPI port number.
- containerPort: 47500 # discovery SPI port number.
- containerPort: 49112 # JMX port number.
- containerPort: 10800 # SQL port number.
- containerPort: 10900 # Thin clients port number.
如上所示,该配置定义了一组环境变量(OPTION_LIBS和CONFIG_URIL),Ignite的Docker镜像使用的一个shell脚本会用到它。Docker镜像的完整配置参数列表可以查看Docker部署的相关章节。
Ignite Docker镜像版本
Kubernetes支持Ignite的1.9及其以后的版本,一定要使用有效的Docker镜像版本,完整的标签列表在这里。
下一步,在Kubernetes中使用上述的配置部署Ignite Pod:
kubectl create -f ignite-deployment.yaml
检查Pod是否启动运行:
kubectl get pods
选择一个可用的Pod的名字:
NAME READY STATUS RESTARTS AGE
ignite-cluster-3454482164-d4m6g 1/1 Running 0 25m
ignite-cluster-3454482164-w0xtx 1/1 Running 0 25m
可以获取日志,确认Pod之间可以在集群内相互发现:
kubectl logs ignite-cluster-3454482164-d4m6g
# 4.2.1.4.调整Ignite集群大小
可以使用标准的Kubernetes API随时调整Ignite集群的大小。比如,如果想把集群从2个节点扩容到5个节点,那么可以使用下面的命令:
kubectl scale --replicas=5 -f ignite-deployment.yaml
再次检查集群已经成功扩容:
kubectl get pods
输出会显示有5个Pod正在运行:
NAME READY STATUS RESTARTS AGE
ignite-cluster-3454482164-d4m6g 1/1 Running 0 34m
ignite-cluster-3454482164-ktkrr 1/1 Running 0 58s
ignite-cluster-3454482164-r20f8 1/1 Running 0 58s
ignite-cluster-3454482164-vf8kh 1/1 Running 0 58s
ignite-cluster-3454482164-w0xtx 1/1 Running 0 34m
# 4.2.1.5.在OpenShift环境中部署
对于使用Docker容器的Kubernetes,OpenShift也是支持的,但是它有自己的RBAC(基于角色的访问控制)特性,这与Kubernetes直接提供的机制不完全兼容,这也是为什么部分命令会导致拒绝访问错误的原因,这时就需要一些额外的配置,如下:
1.使用OpenShift的CLI创建一个具有view角色的服务账户;
$ oc create sa ignite
$ oc policy add-role-to-user view system:serviceaccount:<project>:ignite
注意,<project>是OpenShift的项目名。
2.指定TcpDiscoveryKubernetesIpFinder的namespace参数;
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.kubernetes.TcpDiscoveryKubernetesIpFinder">
<!-- Set a project name as the namespace. -->
<property name="namespace" value="<project>"/>
</bean>
</property>
</bean>
</property>
</bean>
3.在部署配置中添加serviceAccountName;
apiVersion: v1
kind: DeploymentConfig
metadata:
name: ignite-cluster
spec:
# Start two Ignite nodes by default.
replicas: 2
template:
metadata:
labels:
app: ignite
spec:
serviceAccountName: ignite
...
# 4.2.2.有状态部署
如果Ignite部署为内存数据库,并且打开了原生持久化,那么就需要按照有状态的解决方案进行部署。
# 4.2.2.1.要求
确保如下事项已经完成
- 环境中已经部署了Kubernetes集群;
- 已经配置了RBAC授权;
- 已经部署了Ignite服务;
# 4.2.2.2.Kubernetes IP探测器
要开启Kubernetes环境下Ignite节点的自动发现,需要在IgniteConfiguration中启用TcpDiscoveryKubernetesIpFinder,下面会创建一个名为example-kube-persistence.xml的配置文件,然后像下面这样定义相关的配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:util="http://www.springframework.org/schema/util" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util.xsd">
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="workDirectory" value="/persistence/work"/>
<!-- Enabling Apache Ignite Persistent Store. -->
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
</bean>
</property>
<!--
Sets a path to the root directory where data and indexes are
to be persisted. It's assumed the directory is on a dedicated disk.
-->
<property name="storagePath" value="/persistence"/>
<!--
Sets a path to the directory where WAL is stored.
It's assumed the directory is on a dedicated disk.
-->
<property name="walPath" value="/wal"/>
<!--
Sets a path to the directory where WAL archive is stored.
It's assumed the directory is on the same drive with the WAL files.
-->
<property name="walArchivePath" value="/wal/archive"/>
</bean>
</property>
<!-- Explicitly configure TCP discovery SPI to provide list of initial nodes. -->
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<!--
Enables Kubernetes IP finder and setting custom namespace name.
-->
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.kubernetes.TcpDiscoveryKubernetesIpFinder">
<property name="namespace" value="ignite"/>
</bean>
</property>
</bean>
</property>
</bean>
</beans>
该配置开启了Ignite的原生持久化,确保数据能够保存在磁盘上。
下面,就可以为Ignite Pod准备一套Kubernetes有状态集配置然后部署了。
# 4.2.2.3.有状态集部署
最后一步是以有状态集的形式在Kubernetes中部署Ignite Pod。
建议为预写日志文件(WAL)和数据库文件提供单独的磁盘设备,以获得更好的性能。这就是为什么本节提供了两种部署方案的说明:当WAL和数据库文件位于同一个存储中以及分别存储时。
有状态集部署时间
Kubernetes环境可能需要一段时间来分配需要的持久化存储,从而成功地部署所有Pod。在分配时,Pod的部署状态可能会显示如下消息:“pod has unbound persistentvolumeclaims(repeated 4 times)”。
WAL使用独立磁盘
为了确保WAL存储在不同的磁盘上,需要求Kuberenetes提供一个专用的存储类。依赖于Kubernetes环境,存储类将有所不同。在本章节中会为Amazon AWS、Google Compute Engine和Microsoft Azure提供存储类模板。
使用以下模板为WAL请求存储类:
ignite-wal-storage-class.yaml:
通过执行以下命令为WAL文件请求存储:
#Request storage class
kubectl create -f ignite-wal-storage-class.yaml
执行类似的操作,为数据库文件请求专用存储类:
ignite-persistence-storage-class.yaml:
通过执行以下命令为数据库文件请求存储:
#Request storage class
kubectl create -f ignite-persistence-storage-class.yaml
存储类参数
可以根据需要自由调整存储类配置的区域、存储类型和其它参数。
确认两个存储类都已创建并可使用:
kubectl get sc
接下来,继续在Kubernetes中部署有状态集:
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: ignite
namespace: ignite
spec:
selector:
matchLabels:
app: ignite
serviceName: ignite
replicas: 2
template:
metadata:
labels:
app: ignite
spec:
serviceAccountName: ignite
containers:
- name: ignite
image: apacheignite/ignite:2.6.0
env:
- name: OPTION_LIBS
value: ignite-kubernetes,ignite-rest-http
- name: CONFIG_URI
value: https://raw.githubusercontent.com/apache/ignite/master/modules/kubernetes/config/example-kube-persistence-and-wal.xml
- name: IGNITE_QUIET
value: "false"
- name: JVM_OPTS
value: "-Djava.net.preferIPv4Stack=true"
ports:
- containerPort: 11211 # JDBC port number.
- containerPort: 47100 # communication SPI port number.
- containerPort: 47500 # discovery SPI port number.
- containerPort: 49112 # JMX port number.
- containerPort: 10800 # SQL port number.
- containerPort: 8080 # REST port number.
- containerPort: 10900 #Thin clients port number.
volumeMounts:
- mountPath: "/wal"
name: ignite-wal
- mountPath: "/persistence"
name: ignite-persistence
volumeClaimTemplates:
- metadata:
name: ignite-persistence
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "ignite-persistence-storage-class"
resources:
requests:
storage: "1Gi"
- metadata:
name: ignite-wal
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "ignite-wal-storage-class"
resources:
requests:
storage: "1Gi"
# Create the stateful set
kubectl create -f ignite-stateful-set.yaml
确认Ignite Pod正在运行:
kubectl get pods --namespace=ignite
数据库和WAL文件使用相同的存储
如果出于某种原因,需要将WAL和数据库文件存储在同一个磁盘设备中,那么可以使用下面的配置模板来部署和启动有状态集:
ignite-stateful-set.yaml:
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: ignite
namespace: ignite
spec:
selector:
matchLabels:
app: ignite
serviceName: ignite
replicas: 2
template:
metadata:
labels:
app: ignite
spec:
serviceAccountName: ignite
containers:
- name: ignite
image: apacheignite/ignite:2.6.0
env:
- name: OPTION_LIBS
value: ignite-kubernetes,ignite-rest-http
- name: CONFIG_URI
value: https://raw.githubusercontent.com/apache/ignite/master/modules/kubernetes/config/example-kube-persistence.xml
- name: IGNITE_QUIET
value: "false"
- name: JVM_OPTS
value: "-Djava.net.preferIPv4Stack=true"
ports:
- containerPort: 11211 # JDBC port number.
- containerPort: 47100 # communication SPI port number.
- containerPort: 47500 # discovery SPI port number.
- containerPort: 49112 # JMX port number.
- containerPort: 10800 # SQL port number.
- containerPort: 8080 # REST port number.
- containerPort: 10900 #Thin clients port number.
volumeMounts:
- mountPath: "/data/ignite"
name: ignite-storage
volumeClaimTemplates:
- metadata:
name: ignite-storage
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
# Create the stateful set
kubectl create -f ignite-stateful-set.yaml
如上所示,该配置定义了一组环境变量(OPTION_LIBS和CONFIG_URI),Ignite的Docker镜像使用的一个shell脚本会用到它。Docker镜像的完整配置参数列表可以查看Docker部署的相关章节。
确认Ignite的Pod已经启动运行:
kubectl get pods --namespace=ignite
获取Ignite Pod的日志
通过下面的过程,可以获取Ignite的Pod生成的日志。
获取正在运行的Ignite Pod的列表:
kubectl get pods --namespace=ignite
选择一个可用的Pod的名字:
NAME READY STATUS RESTARTS AGE
ignite-0 1/1 Running 0 7m
ignite-1 1/1 Running 0 4m
然后从中获取日志:
kubectl logs ignite-0 --namespace=ignite
# 4.2.2.4.调整Ignite集群大小
属于标准的Kubernetes API,可以随时调整Ignite集群的大小。比如希望将集群从2个节点扩容到4个节点,可以使用下面的命令:
kubectl scale sts ignite --replicas=4 --namespace=ignite
再次确认集群扩容成功:
kubectl get pods --namespace=ignite
输出显示有4个Ignite Pod正在运行:
NAME READY STATUS RESTARTS AGE
ignite-0 1/1 Running 0 21m
ignite-1 1/1 Running 0 18m
ignite-2 1/1 Running 0 12m
ignite-3 1/1 Running 0 9m
# 4.2.2.5.Ignite集群激活
因为部署使用了Ignite的原生持久化,因此启动之后集群需要激活,怎么做呢,接入一个Pod:
kubectl exec -it ignite-0 --namespace=ignite -- /bin/bash
转到下面的目录:
cd /opt/ignite/apache-ignite-fabric/bin/
然后使用下面的命令可以激活集群:
./control.sh --activate
# 4.2.3.RBAC授权
# 4.2.3.1.概述
基于角色的访问控制(RBAC)是一种企业内基于单个用户的角色来调节对计算机或网络资源访问的常规方法。
RBAC使用rbac.authorization.k8s.ioAPI组来驱动授权决策,允许管理员通过Kubernetes API动态地配置策略。
建议为Ignite部署配置RBAC,以对部署进行细粒度的控制,避免与安全有关的问题。
# 4.2.3.2.要求
假定已经部署好了一套Kubernetes集群环境。
# 4.2.3.3.创建命名空间
需要为Ignite部署创建一个唯一的命名空间,在本案例中命名空间名字为ignite:
ignite-namespace.yaml:
apiVersion: v1
kind: Namespace
metadata:
name: ignite
执行下面的命令配置命名空间:
kubectl create -f ignite-namespace.yaml
# 4.2.3.4.创建服务账户
通过下面的方式配置Ignite服务账户:
ignite-service-account.yaml:
apiVersion: v1
kind: ServiceAccount
metadata:
name: ignite
namespace: ignite
执行下面的命令创建账户:
kubectl create -f ignite-service-account.yaml
# 4.2.3.5.创建角色
通过下面的方式创建Ignite服务使用的角色,该服务用于节点的自动发现,并且用作远程应用的负载平衡器。
ignite-account-role.yaml:
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: Role
metadata:
name: ignite
namespace: ignite
rules:
- apiGroups:
- ""
resources: # Here are resources you can access
- pods
- endpoints
verbs: # That is what you can do with them
- get
- list
- watch
注意
如果不打算将Ignite服务用作外部应用的负载平衡器,那么建议赋予其更少的权限,具体见这里。
执行下面的命令创建角色:
kubectl create -f ignite-account-role.yaml
下一步,使用下面的配置将该角色绑定到服务账户和命名空间上:
ignite-role-binding.yaml:
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: ignite
roleRef:
kind: Role
name: ignite
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: ignite
namespace: ignite
执行下面的命令执行绑定:
kubectl create -f ignite-role-binding.yaml
最后,将命名空间切换到ignite,然后就可以看到所有所属的资源:
kubectl config set-context $(kubectl config current-context) --namespace=ignite
# 4.2.4.Ignite服务
Ignite服务用于Ignite节点的自动发现,还有做为要接入集群的外部应用的负载平衡器。
本章节描述如何配置和部署Ignite服务。
# 4.2.4.1.Ignite服务部署
Ignite的KubernetesIPFinder需要用户配置和部署一个专用的Kubernetes服务,它会维护一个所有有效的Ignite Pod的IP地址列表。
每次启动一个新的Ignite Pod,IP探测器会通过Kubernetes API接入服务来获取已有的Ignite Pod地址列表。通过这些地址,新的节点就可以发现集群中的其它节点从而最终加入Ignite集群。
同时,也可以将该服务复用为预接入集群的外部应用的负载平衡器。
通过下面的方式可以配置服务,它考虑了所有的必要条件:
会话关联属性
只有在Kubernetes中部署了Ignite集群并且应用不在其中时,才需要下面使用的sessionAffinity。该属性确保Ignite瘦客户端、JDBC/ODBC驱动保留与特定的Ignite Pod的连接。
如果集群和应用都由Kubernetes管理,那么该属性是冗余的,可以删除。
ignite-service.yaml:
apiVersion: v1
kind: Service
metadata:
# The name must be equal to KubernetesConnectionConfiguration.serviceName
name: ignite-service
# The name must be equal to KubernetesConnectionConfiguration.namespace
namespace: ignite
spec:
type: LoadBalancer
ports:
- name: rest
port: 8080
targetPort: 8080
- name: sql
port: 10800
targetPort: 10800
- name: thinclients
port: 10900
targetPort: 10900
sessionAffinity: ClientIP
selector:
# Must be equal to the label set for Ignite pods.
app: ignite
然后使用如下的命令将其部署进Kubernetes(确认事先已经配置好了唯一的命名空间和RBAC):
kubectl create -f ignite-service.yaml
确认服务已经正在运行:
kubectl get svc ignite --namespace=ignite
# 4.2.5.Kubernetes IP探测器
# 4.2.5.1.概述
将Ignite节点以KubernetesPod的形式进行部署,对Ignite节点的发现机制有一定的要求。因为防火墙通常会阻止组播通信的原因,很可能无法直接使用基于组播的IP探测器。但是,只要Kubernetes动态地分配了地址,就可以列出所有节点的IP地址,然后使用静态IP探测器。
也可以考虑Amazon AWS IP探测器、Google Compute Engine IP探测器或者JClouds IP探测器,但是Kubernetes必须部署在这些云环境中。另外,也可以使用共享文件系统或者关系型数据库用于节点的自动发现,但是必须单独维护数据库或者共享文件系统。
本章节会描述有关针对使用Kubernetes技术容器化的Ignite节点,专门开发的IP探测器,该IP探测器会自动搜索所有在线的Ignite Pod的IP地址,它是通过与一个持有所有最新端点的Kubernetes服务进行通信实现的。
# 4.2.5.2.基于Kubernetes服务的发现
如果要开启Kubernetes环境的节点自动发现,需要在下面的配置中使用TcpDiscoveryKubernetesIpFinder:
Maven构件
如果要使用TcpDiscoveryKubernetesIpFinder,需要在Maven中添加ignite-kubernetes依赖。
Ignite的KubernetesIPFinder需要用户配置和部署一个Kubernetes服务,它负责维护所有在线Ignite Pod(节点)的IP地址列表。
每当启动一个新的Ignite Pod,IP探测器会通过Kubernetes的API访问Kubernetes服务,获取已有的Ignite Pod的地址列表,通过这些地址,新的节点就可以与其它节点互相连接,然后最终加入集群。
该服务需要手工配置,然后需要优先于Ignite Pod先行启动,下面是代码样例:
Service Configuration:
apiVersion: v1
kind: Service
metadata:
# Name of Ignite Service used by Kubernetes IP finder for IP addresses lookup.
name: ignite
spec:
clusterIP: None # custom value.
ports:
- port: 9042 # custom value.
selector:
# Must be equal to one of the labels set in Ignite pods'
# deployement configuration.
app: ignite
默认的服务名为ignite,如果修改了名字,一定要同时调用TcpDiscoveryKubernetesIpFinder.setServiceName(String)方法进行修改。
另外,建议通过某种方式对Ignite的Pod打标签,然后在服务的selector配置段中配置标签。比如,通过上面的配置启动的服务,会关注于标注为app: ignite的Pod。
从外部接入容器化的Ignite集群
TcpDiscoveryKubernetesIpFinder的设计是用于Kubernetes环境内部的,这意味着所有的Ignite节点、与集群交互的应用都需要通过Kubernetes容器化。
但是,如果希望从Kubernetes外部接入Ignite集群,那么:
- 需要在Ignite Pod的yaml文件中配置
hostNetwork=true,这样就可以从外部与容器化的Ignite Pod建立TCP/IP连接; - 在Kubernetes环境外部,使用同样的
TcpDiscoveryKubernetesIpFinder。
# 4.2.5.3.配置参数
通常,TcpDiscoveryKubernetesIpFinder的设计是直接可用,但是通过下面的参数也可以进行细粒度的控制:
| 属性 | 描述 | 默认值 |
|---|---|---|
setServiceName(String) | 配置Kubernetes服务的名字,该服务用于Ignite Pod的IP地址搜索,服务名必须与Kubernetes配置中的服务名一致。 | ignite |
setNamespace(String) | 配置Kubernetes服务所属的命名空间。 | default |
setMasterUrl(String) | 配置Kubernetes API服务器的主机名。 | https://kubernetes.default.svc.cluster.local:443 |
setAccountToken(String) | 配置服务令牌文件的路径。 | /var/run/secrets/kubernetes.io/serviceaccount/token |
# 4.3.Microsoft Azure Kubernetes Service部署
本章节会一步步介绍如何在Microsoft Azure Kubernetes Service中部署Ignite集群。
需要考虑两个部署模式:有状态和无状态。无状态部署适用于纯内存场景,这时应用的数据保存在内存中,有更好的性能,有状态部署和无状态部署的区别是,他需要为集群的存储配置持久化卷。
警告
本章节聚焦于在Kubernetes中部署服务端节点,如果要运行的Kubernetes中的客户端节点位于其他的位置,则需要启用为运行在NAT之后的客户端节点设计的通信模式,具体请参见这个章节的内容。
警告
本章节基于kubectl的1.17版本撰写。
# 4.3.1.创建AKS集群
第一步是配置Azure Kubernetes服务(AKS)集群,具体可以看下面的资料:
本章节中会讲解如何使用Azure门户进行AKS部署。
- 如果没有Microsoft账号,需要先创建一个,然后转到https://portal.azure.com 然后选择
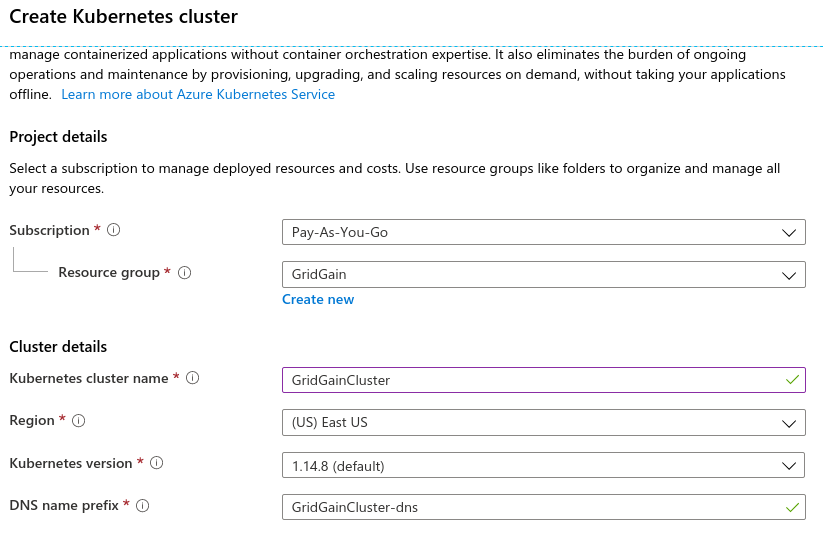
Create a resource> 选择Kubernetes Service>Create; - 在下一页中,配置本次部署的常规参数,集群名处填写
IgniteCluster,资源组处填写Ignite:
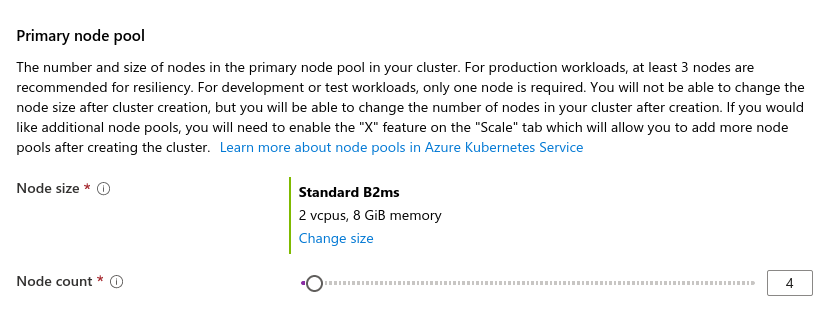
- 在同一个页面中,输入AKS集群中需要的节点数:
- 配置其他必要的参数;
- 配置完成之后,点击
Review + create按钮; - 再次确认配置参数,然后点击
Create,Azure会花一点时间部署集群; - 在
All Resources>IgniteCluster中可以看到集群的状态。
# 4.3.2.访问AKS集群
要配置kubectl可以接入Kubernetes集群,要执行下面的命令:
az aks get-credentials --resource-group Ignite --name IgniteCluster
如果遇到任何问题,需要确认一下官方的文档。、
执行下面的命令,可以检查所有节点是否为Ready状态:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-25545244-vmss000000 Ready agent 6h23m v1.14.8
aks-agentpool-25545244-vmss000001 Ready agent 6h23m v1.14.8
aks-agentpool-25545244-vmss000002 Ready agent 6h23m v1.14.8
下面就可以创建Kubernetes资源了。
# 4.3.3.Kubernetes配置
Kubernetes配置涉及创建如下的资源:
- 命名空间;
- 集群角色;
- 节点配置文件的ConfigMap;
- 用于发现以及为外部应用接入集群提供负载平衡的服务;
- 运行Ignite节点的Pod配置。
创建命名空间
为集群创建一个唯一的命名空间,在本例中,命名空间命名为ignite。
可以使用下面的命令创建命名空间:
kubectl create namespace ignite
创建服务
Kubernetes服务用于自动发现以及为外部应用接入集群提供负载平衡,
每次一个新节点启动(在一个单独的Pod中),IP探测器会通过Kubernetes API接入服务来获取已有的Pod地址列表,使用这些地址,新的节点就会发现所有的集群节点。
service.yaml:
apiVersion: v1
kind: Service
metadata:
# The name must be equal to KubernetesConnectionConfiguration.serviceName
name: ignite-service
# The name must be equal to KubernetesConnectionConfiguration.namespace
namespace: ignite
labels:
app: ignite
spec:
type: LoadBalancer
ports:
- name: rest
port: 8080
targetPort: 8080
- name: thinclients
port: 10800
targetPort: 10800
# Optional - remove 'sessionAffinity' property if the cluster
# and applications are deployed within Kubernetes
# sessionAffinity: ClientIP
selector:
# Must be equal to the label set for pods.
app: ignite
status:
loadBalancer: {}
创建服务:
kubectl create -f service.yaml
创建集群角色和服务账户
创建服务账户:
kubectl create sa ignite -n ignite
集群角色用于Pod的授权访问,下面的文件内容为集群角色的配置示例:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: ignite
namespace: ignite
rules:
- apiGroups:
- ""
resources: # Here are the resources you can access
- pods
- endpoints
verbs: # That is what you can do with them
- get
- list
- watch
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: ignite
roleRef:
kind: Role
name: ignite
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: ignite
namespace: ignite
执行下面的命令创建角色和角色绑定:
kubectl create -f cluster-role.yaml
为节点配置创建ConfigMap
需要创建一个ConfigMap,用于持有每个节点使用的配置文件,这样可以使所有的节点共享同一个配置文件实例。
首先要创建一个配置文件,根据是否持久化,选择下面某个选项卡:
IP探测器配置的namespace和serviceName属性必须与服务配置中指定的一致,其他的属性可以按需配置。
在上述配置文件所在的目录中执行下面的命令,可以创建一个ConfigMap:
kubectl create configmap ignite-config -n ignite --from-file=node-configuration.xml
创建Pod配置
下面需要创建Pod的配置,对于无状态部署,需要使用Deployment,对于有状态的部署,需要使用StatefulSet。
$ kubectl get pods -n ignite
NAME READY STATUS RESTARTS AGE
ignite-cluster-5b69557db6-lcglw 1/1 Running 0 44m
ignite-cluster-5b69557db6-xpw5d 1/1 Running 0 44m
确认节点的日志:
$ kubectl logs ignite-cluster-5b69557db6-lcglw -n ignite
...
[14:33:50] Ignite documentation: http://gridgain.com
[14:33:50]
[14:33:50] Quiet mode.
[14:33:50] ^-- Logging to file '/opt/gridgain/work/log/ignite-b8622b65.0.log'
[14:33:50] ^-- Logging by 'JavaLogger [quiet=true, config=null]'
[14:33:50] ^-- To see **FULL** console log here add -DIGNITE_QUIET=false or "-v" to ignite.{sh|bat}
[14:33:50]
[14:33:50] OS: Linux 4.19.81 amd64
[14:33:50] VM information: OpenJDK Runtime Environment 1.8.0_212-b04 IcedTea OpenJDK 64-Bit Server VM 25.212-b04
[14:33:50] Please set system property '-Djava.net.preferIPv4Stack=true' to avoid possible problems in mixed environments.
[14:33:50] Initial heap size is 30MB (should be no less than 512MB, use -Xms512m -Xmx512m).
[14:33:50] Configured plugins:
[14:33:50] ^-- None
[14:33:50]
[14:33:50] Configured failure handler: [hnd=StopNodeOrHaltFailureHandler [tryStop=false, timeout=0, super=AbstractFailureHandler [ignoredFailureTypes=UnmodifiableSet [SYSTEM_WORKER_BLOCKED, SYSTEM_CRITICAL_OPERATION_TIMEOUT]]]]
[14:33:50] Message queue limit is set to 0 which may lead to potential OOMEs when running cache operations in FULL_ASYNC or PRIMARY_SYNC modes due to message queues growth on sender and receiver sides.
[14:33:50] Security status [authentication=off, tls/ssl=off]
[14:34:00] Nodes started on local machine require more than 80% of physical RAM what can lead to significant slowdown due to swapping (please decrease JVM heap size, data region size or checkpoint buffer size) [required=918MB, available=1849MB]
[14:34:01] Performance suggestions for grid (fix if possible)
[14:34:01] To disable, set -DIGNITE_PERFORMANCE_SUGGESTIONS_DISABLED=true
[14:34:01] ^-- Enable G1 Garbage Collector (add '-XX:+UseG1GC' to JVM options)
[14:34:01] ^-- Specify JVM heap max size (add '-Xmx[g|G|m|M|k|K]' to JVM options)
[14:34:01] ^-- Set max direct memory size if getting 'OOME: Direct buffer memory' (add '-XX:MaxDirectMemorySize=[g|G|m|M|k|K]' to JVM options)
[14:34:01] ^-- Disable processing of calls to System.gc() (add '-XX:+DisableExplicitGC' to JVM options)
[14:34:01] Refer to this page for more performance suggestions: https://apacheignite.readme.io/docs/jvm-and-system-tuning
[14:34:01]
[14:34:01] To start Console Management & Monitoring run ignitevisorcmd.{sh|bat}
[14:34:01] Data Regions Configured:
[14:34:01] ^-- default [initSize=256.0 MiB, maxSize=370.0 MiB, persistence=false, lazyMemoryAllocation=true]
[14:34:01]
[14:34:01] Ignite node started OK (id=b8622b65)
[14:34:01] Topology snapshot [ver=2, locNode=b8622b65, servers=2, clients=0, state=ACTIVE, CPUs=2, offheap=0.72GB, heap=0.88GB]
最后一行的servers=2,显示两个节点已经组成了集群。
就绪探针 Ignite的probeREST命令可用于确定Ignite内核是否已经启动。
存活探针
Ignite的versionREST命令可用于确定Ignite正在正常运行。
# 4.3.4.激活集群
如果部署的是无状态的集群,那么可以忽略这一步,未开启持久化的集群不需要激活。
如果开启了持久化,那么启动后必须激活集群。这需要接入某个Pod:
kubectl exec -it <pod_name> -n ignite -- /bin/bash
然后执行如下的命令:
/opt/ignite/apache-ignite/bin/control.sh --set-state ACTIVE --yes
还可以使用REST API激活集群,下面的章节会介绍如何通过REST API接入集群。
# 4.3.5.集群扩容
可以使用kubectl scale命令对集群进行扩容。
警告
首先要确认AKS集群上有足够的资源添加新的节点。
下面的示例中,会添加一个新的节点(现在是两个)。
警告
如果减少的节点数多于分区备份数,可能会丢失数据,缩容的正确方式是通过调整基线拓扑删除节点后,进行数据重新分布。
# 4.3.6.接入集群
如果应用也运行于Kubernetes中,可以使用瘦客户端,也可以使用客户端节点接入集群。
获取服务的开放IP地址:
$ kubectl describe svc ignite-service -n ignite
Name: ignite-service
Namespace: ignite
Labels: app=ignite
Annotations: <none>
Selector: app=ignite
Type: LoadBalancer
IP: 10.0.144.19
LoadBalancer Ingress: 13.86.186.145
Port: rest 8080/TCP
TargetPort: 8080/TCP
NodePort: rest 31912/TCP
Endpoints: 10.244.1.5:8080
Port: thinclients 10800/TCP
TargetPort: 10800/TCP
NodePort: thinclients 31345/TCP
Endpoints: 10.244.1.5:10800
Session Affinity: None
External Traffic Policy: Cluster
可以使用LoadBalancer Ingress的地址来接入开放的端口之一,端口列表在命令的输出中已经列出。
客户端节点接入
客户端节点需要接入集群中的每个节点,唯一的方式就是在Kubernetes中启动一个客户端节点,需要将发现机制配置为使用TcpDiscoveryKubernetesIpFinder,前述创建ConfigMap时已经介绍过。
瘦客户端接入
下面的代码片段说明了如何通过Java瘦客户端接入集群,其他瘦客户端也是同样的方式,注意这里使用了服务的开放IP地址(LoadBalancer Ingress)。
ClientConfiguration cfg = new ClientConfiguration().setAddresses("13.86.186.145:10800");
IgniteClient client = Ignition.startClient(cfg);
ClientCache<Integer, String> cache = client.getOrCreateCache("test_cache");
cache.put(1, "first test value");
System.out.println(cache.get(1));
client.close();
分区感知
分区感知使得瘦客户端可以将请求直接发给待处理数据所在的节点。
在没有分区感知时,通过瘦客户端接入集群的应用,实际是通过某个作为代理的服务端节点执行所有查询和操作,然后将这些操作重新路由到数据所在的节点,这会导致瓶颈,可能会限制应用的线性扩展能力。
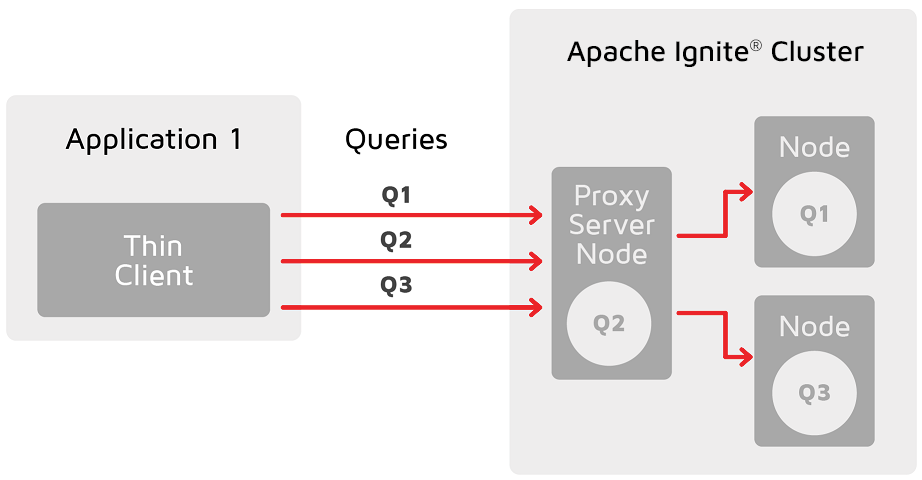
注意查询必须通过代理服务端节点,然后路由到正确的节点。
有了分区感知之后,瘦客户端可以将查询和操作直接路由到持有待处理数据的主节点,这消除了瓶颈,使应用更易于扩展。
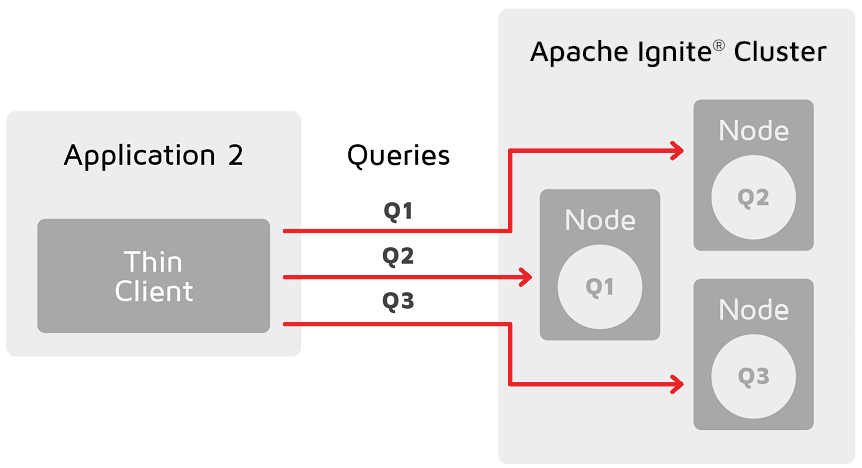
要在Kubernetes环境中启用分区感知功能,应在集群中启动一个客户端,并使用KubernetesConnectionConfiguration对其进行配置,这时客户端就可以接入集群中的每个Pod。
KubernetesConnectionConfiguration kcfg = new KubernetesConnectionConfiguration();
kcfg.setNamespace("ignite");
kcfg.setServiceName("ignite-service");
ClientConfiguration ccfg = new ClientConfiguration();
ccfg.setAddressesFinder(new ThinClientKubernetesAddressFinder(kcfg));
IgniteClient client = Ignition.startClient(cfg);
ClientCache<Integer, String> cache = client.getOrCreateCache("test_cache");
cache.put(1, "first test value");
System.out.println(cache.get(1));
client.close();
REST API接入
REST API接入集群的方式如下:
$ curl http://13.86.186.145:8080/ignite?cmd=version
{"successStatus":0,"error":null,"response":"2.14.0","sessionToken":null}
# 4.4.Google Kubernetes Engine部署
本章节会一步步介绍如何在Google Kubernetes Engine中部署Ignite集群。
需要考虑两个部署模式:有状态和无状态。无状态部署适用于纯内存场景,这时应用的数据保存在内存中,有更好的性能,有状态部署和无状态部署的区别是,他需要为集群的存储配置持久化卷。
警告
本章节聚焦于在Kubernetes中部署服务端节点,如果要运行的Kubernetes中的客户端节点位于其他的位置,则需要启用为运行在NAT之后的客户端节点设计的通信模式,具体请参见这个章节的内容。
警告
本章节基于kubectl的1.17版本撰写。
# 4.4.1.创建GKE集群
GKE集群是为部署在集群中的应用提供资源的一组节点,用户必须针对自身场景创建具有足够资源(CPU、RAM以及存储)的GKE集群。
创建集群的最简单方式是使用gcloud命令行工具。
$ gcloud container clusters create my-cluster --zone us-west1
...
Creating cluster my-cluster in us-west1... Cluster is being health-checked (master is healthy)...done.
Created [https://container.googleapis.com/v1/projects/gmc-development/zones/us-west1/clusters/my-cluster].
To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/us-west1/my-cluster?project=my-project
kubeconfig entry generated for my-cluster.
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS
my-cluster us-west1 1.14.10-gke.27 35.230.126.102 n1-standard-1 1.14.10-gke.27 9 RUNNING
验证kubectl是否配置正确:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gke-my-cluster-default-pool-6e9f3e45-8k0w Ready <none> 73s v1.14.10-gke.27
gke-my-cluster-default-pool-6e9f3e45-b7lb Ready <none> 72s v1.14.10-gke.27
gke-my-cluster-default-pool-6e9f3e45-cmzc Ready <none> 74s v1.14.10-gke.27
gke-my-cluster-default-pool-a2556b36-85z6 Ready <none> 73s v1.14.10-gke.27
gke-my-cluster-default-pool-a2556b36-xlbj Ready <none> 72s v1.14.10-gke.27
gke-my-cluster-default-pool-a2556b36-z8fp Ready <none> 74s v1.14.10-gke.27
gke-my-cluster-default-pool-e93974f2-hwkj Ready <none> 72s v1.14.10-gke.27
gke-my-cluster-default-pool-e93974f2-jqj3 Ready <none> 72s v1.14.10-gke.27
gke-my-cluster-default-pool-e93974f2-v8xv Ready <none> 74s v1.14.10-gke.27
下面就可以创建Kubernetes资源了。
# 4.4.2.Kubernetes配置
Kubernetes配置涉及创建如下的资源:
- 命名空间;
- 集群角色;
- 节点配置文件的ConfigMap;
- 用于发现以及为外部应用接入集群提供负载平衡的服务;
- 运行Ignite节点的Pod配置。
创建命名空间
为集群创建一个唯一的命名空间,在本例中,命名空间命名为ignite。
可以使用下面的命令创建命名空间:
kubectl create namespace ignite
创建服务
Kubernetes服务用于自动发现以及为外部应用接入集群提供负载平衡,
每次一个新节点启动(在一个单独的Pod中),IP探测器会通过Kubernetes API接入服务来获取已有的Pod地址列表,使用这些地址,新的节点就会发现所有的集群节点。
service.yaml:
apiVersion: v1
kind: Service
metadata:
# The name must be equal to KubernetesConnectionConfiguration.serviceName
name: ignite-service
# The name must be equal to KubernetesConnectionConfiguration.namespace
namespace: ignite
labels:
app: ignite
spec:
type: LoadBalancer
ports:
- name: rest
port: 8080
targetPort: 8080
- name: thinclients
port: 10800
targetPort: 10800
# Optional - remove 'sessionAffinity' property if the cluster
# and applications are deployed within Kubernetes
# sessionAffinity: ClientIP
selector:
# Must be equal to the label set for pods.
app: ignite
status:
loadBalancer: {}
创建服务:
kubectl create -f service.yaml
创建集群角色和服务账户
创建服务账户:
kubectl create sa ignite -n ignite
集群角色用于Pod的授权访问,下面的文件内容为集群角色的配置示例:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: ignite
namespace: ignite
rules:
- apiGroups:
- ""
resources: # Here are the resources you can access
- pods
- endpoints
verbs: # That is what you can do with them
- get
- list
- watch
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: ignite
roleRef:
kind: Role
name: ignite
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: ignite
namespace: ignite
执行下面的命令创建角色和角色绑定:
kubectl create -f cluster-role.yaml
为节点配置创建ConfigMap
需要创建一个ConfigMap,用于持有每个节点使用的配置文件,这样可以使所有的节点共享同一个配置文件实例。
首先要创建一个配置文件,根据是否持久化,选择下面某个选项卡:
IP探测器配置的namespace和serviceName属性必须与服务配置中指定的一致,其他的属性可以按需配置。
在上述配置文件所在的目录中执行下面的命令,可以创建一个ConfigMap:
kubectl create configmap ignite-config -n ignite --from-file=node-configuration.xml
创建Pod配置
下面需要创建Pod的配置,对于无状态部署,需要使用Deployment,对于有状态的部署,需要使用StatefulSet。
$ kubectl get pods -n ignite
NAME READY STATUS RESTARTS AGE
ignite-cluster-5b69557db6-lcglw 1/1 Running 0 44m
ignite-cluster-5b69557db6-xpw5d 1/1 Running 0 44m
确认节点的日志:
$ kubectl logs ignite-cluster-5b69557db6-lcglw -n ignite
...
[14:33:50] Ignite documentation: http://gridgain.com
[14:33:50]
[14:33:50] Quiet mode.
[14:33:50] ^-- Logging to file '/opt/gridgain/work/log/ignite-b8622b65.0.log'
[14:33:50] ^-- Logging by 'JavaLogger [quiet=true, config=null]'
[14:33:50] ^-- To see **FULL** console log here add -DIGNITE_QUIET=false or "-v" to ignite.{sh|bat}
[14:33:50]
[14:33:50] OS: Linux 4.19.81 amd64
[14:33:50] VM information: OpenJDK Runtime Environment 1.8.0_212-b04 IcedTea OpenJDK 64-Bit Server VM 25.212-b04
[14:33:50] Please set system property '-Djava.net.preferIPv4Stack=true' to avoid possible problems in mixed environments.
[14:33:50] Initial heap size is 30MB (should be no less than 512MB, use -Xms512m -Xmx512m).
[14:33:50] Configured plugins:
[14:33:50] ^-- None
[14:33:50]
[14:33:50] Configured failure handler: [hnd=StopNodeOrHaltFailureHandler [tryStop=false, timeout=0, super=AbstractFailureHandler [ignoredFailureTypes=UnmodifiableSet [SYSTEM_WORKER_BLOCKED, SYSTEM_CRITICAL_OPERATION_TIMEOUT]]]]
[14:33:50] Message queue limit is set to 0 which may lead to potential OOMEs when running cache operations in FULL_ASYNC or PRIMARY_SYNC modes due to message queues growth on sender and receiver sides.
[14:33:50] Security status [authentication=off, tls/ssl=off]
[14:34:00] Nodes started on local machine require more than 80% of physical RAM what can lead to significant slowdown due to swapping (please decrease JVM heap size, data region size or checkpoint buffer size) [required=918MB, available=1849MB]
[14:34:01] Performance suggestions for grid (fix if possible)
[14:34:01] To disable, set -DIGNITE_PERFORMANCE_SUGGESTIONS_DISABLED=true
[14:34:01] ^-- Enable G1 Garbage Collector (add '-XX:+UseG1GC' to JVM options)
[14:34:01] ^-- Specify JVM heap max size (add '-Xmx[g|G|m|M|k|K]' to JVM options)
[14:34:01] ^-- Set max direct memory size if getting 'OOME: Direct buffer memory' (add '-XX:MaxDirectMemorySize=[g|G|m|M|k|K]' to JVM options)
[14:34:01] ^-- Disable processing of calls to System.gc() (add '-XX:+DisableExplicitGC' to JVM options)
[14:34:01] Refer to this page for more performance suggestions: https://apacheignite.readme.io/docs/jvm-and-system-tuning
[14:34:01]
[14:34:01] To start Console Management & Monitoring run ignitevisorcmd.{sh|bat}
[14:34:01] Data Regions Configured:
[14:34:01] ^-- default [initSize=256.0 MiB, maxSize=370.0 MiB, persistence=false, lazyMemoryAllocation=true]
[14:34:01]
[14:34:01] Ignite node started OK (id=b8622b65)
[14:34:01] Topology snapshot [ver=2, locNode=b8622b65, servers=2, clients=0, state=ACTIVE, CPUs=2, offheap=0.72GB, heap=0.88GB]
最后一行的servers=2,显示两个节点已经组成了集群。
就绪探针 Ignite的probeREST命令可用于确定Ignite内核是否已经启动。
存活探针
Ignite的versionREST命令可用于确定Ignite正在正常运行。
# 4.4.3.激活集群
如果部署的是无状态的集群,那么可以忽略这一步,未开启持久化的集群不需要激活。
如果开启了持久化,那么启动后必须激活集群。这需要接入某个Pod:
kubectl exec -it <pod_name> -n ignite -- /bin/bash
然后执行如下的命令:
/opt/ignite/apache-ignite/bin/control.sh --set-state ACTIVE --yes
还可以使用REST API激活集群,下面的章节会介绍如何通过REST API接入集群。
# 4.4.4.集群扩容
可以使用kubectl scale命令对集群进行扩容。
警告
首先要确认GKE集群上有足够的资源添加新的节点。
下面的示例中,会添加一个新的节点(现在是两个)。
警告
如果减少的节点数多于分区备份数,可能会丢失数据,缩容的正确方式是通过调整基线拓扑删除节点后,进行数据重新分布。
# 4.4.5.接入集群
如果应用也运行于Kubernetes中,可以使用瘦客户端,也可以使用客户端节点接入集群。
获取服务的开放IP地址:
$ kubectl describe svc ignite-service -n ignite
Name: ignite-service
Namespace: ignite
Labels: app=ignite
Annotations: <none>
Selector: app=ignite
Type: LoadBalancer
IP: 10.0.144.19
LoadBalancer Ingress: 13.86.186.145
Port: rest 8080/TCP
TargetPort: 8080/TCP
NodePort: rest 31912/TCP
Endpoints: 10.244.1.5:8080
Port: thinclients 10800/TCP
TargetPort: 10800/TCP
NodePort: thinclients 31345/TCP
Endpoints: 10.244.1.5:10800
Session Affinity: None
External Traffic Policy: Cluster
可以使用LoadBalancer Ingress的地址来接入开放的端口之一,端口列表在命令的输出中已经列出。
客户端节点接入
客户端节点需要接入集群中的每个节点,唯一的方式就是在Kubernetes中启动一个客户端节点,需要将发现机制配置为使用TcpDiscoveryKubernetesIpFinder,前述创建ConfigMap时已经介绍过。
瘦客户端接入
下面的代码片段说明了如何通过Java瘦客户端接入集群,其他瘦客户端也是同样的方式,注意这里使用了服务的开放IP地址(LoadBalancer Ingress)。
ClientConfiguration cfg = new ClientConfiguration().setAddresses("13.86.186.145:10800");
IgniteClient client = Ignition.startClient(cfg);
ClientCache<Integer, String> cache = client.getOrCreateCache("test_cache");
cache.put(1, "first test value");
System.out.println(cache.get(1));
client.close();
分区感知
分区感知使得瘦客户端可以将请求直接发给待处理数据所在的节点。
在没有分区感知时,通过瘦客户端接入集群的应用,实际是通过某个作为代理的服务端节点执行所有查询和操作,然后将这些操作重新路由到数据所在的节点,这会导致瓶颈,可能会限制应用的线性扩展能力。
注意查询必须通过代理服务端节点,然后路由到正确的节点。
有了分区感知之后,瘦客户端可以将查询和操作直接路由到持有待处理数据的主节点,这消除了瓶颈,使应用更易于扩展。
要在Kubernetes环境中启用分区感知功能,应在集群中启动一个客户端,并使用KubernetesConnectionConfiguration对其进行配置,这时客户端就可以接入集群中的每个Pod。
KubernetesConnectionConfiguration kcfg = new KubernetesConnectionConfiguration();
kcfg.setNamespace("ignite");
kcfg.setServiceName("ignite-service");
ClientConfiguration ccfg = new ClientConfiguration();
ccfg.setAddressesFinder(new ThinClientKubernetesAddressFinder(kcfg));
IgniteClient client = Ignition.startClient(cfg);
ClientCache<Integer, String> cache = client.getOrCreateCache("test_cache");
cache.put(1, "first test value");
System.out.println(cache.get(1));
client.close();
REST API接入
REST API接入集群的方式如下:
$ curl http://13.86.186.145:8080/ignite?cmd=version
{"successStatus":0,"error":null,"response":"2.14.0","sessionToken":null}
# 4.5.AWS EKS部署
本章节会一步步介绍如何在Amazon EKS中部署Ignite集群。
需要考虑两个部署模式:有状态和无状态。无状态部署适用于纯内存场景,这时应用的数据保存在内存中,有更好的性能,有状态部署和无状态部署的区别是,他需要为集群的存储配置持久化卷。
警告
本章节聚焦于在Kubernetes中部署服务端节点,如果要运行的Kubernetes中的客户端节点位于其他的位置,则需要启用为运行在NAT之后的客户端节点设计的通信模式,具体请参见这个章节的内容。
警告
本章节基于kubectl的1.17版本撰写。
本章节中,会使用eksctl命令行工具来创建Kubernetes集群,可以参照这个文档来安装必要的资源并且熟悉该工具。
# 4.5.1.创建Amazon EKS集群
首先,需要创建一个具有足够资源的Amazon EKS集群,创建集群可以使用如下的命令:
eksctl create cluster --name ignitecluster --nodes 2 --nodes-min 1 --nodes-max 4
查看EKS文档可以了解所有可用选项的列表。配置一个集群可能需要15分钟,使用如下命令可以检查集群的状态:
$ eksctl get cluster -n ignitecluster
NAME VERSION STATUS CREATED VPC SUBNETS SECURITYGROUPS
ignitecluster 1.14 ACTIVE 2019-12-16T09:57:09Z vpc-0ebf4a6ee3de12c63 subnet-00fa7e85aaebcd54d,subnet-06134ae545a5cc04c,subnet-063d9fdb481e727d2,subnet-0a087062ddc47c341 sg-06a6800a67ea95528
当集群的状态处于ACTIVE时,就可以创建Kubernetes资源了。
验证kubectl是否配置正确:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 6m49s
# 4.5.2.Kubernetes配置
Kubernetes配置涉及创建如下的资源:
- 命名空间;
- 集群角色;
- 节点配置文件的ConfigMap;
- 用于发现以及为外部应用接入集群提供负载平衡的服务;
- 运行Ignite节点的Pod配置。
创建命名空间
为集群创建一个唯一的命名空间,在本例中,命名空间命名为ignite。
可以使用下面的命令创建命名空间:
kubectl create namespace ignite
创建服务
Kubernetes服务用于自动发现以及为外部应用接入集群提供负载平衡,
每次一个新节点启动(在一个单独的Pod中),IP探测器会通过Kubernetes API接入服务来获取已有的Pod地址列表,使用这些地址,新的节点就会发现所有的集群节点。
service.yaml:
apiVersion: v1
kind: Service
metadata:
# The name must be equal to KubernetesConnectionConfiguration.serviceName
name: ignite-service
# The name must be equal to KubernetesConnectionConfiguration.namespace
namespace: ignite
labels:
app: ignite
spec:
type: LoadBalancer
ports:
- name: rest
port: 8080
targetPort: 8080
- name: thinclients
port: 10800
targetPort: 10800
# Optional - remove 'sessionAffinity' property if the cluster
# and applications are deployed within Kubernetes
# sessionAffinity: ClientIP
selector:
# Must be equal to the label set for pods.
app: ignite
status:
loadBalancer: {}
创建服务:
kubectl create -f service.yaml
创建集群角色和服务账户
创建服务账户:
kubectl create sa ignite -n ignite
集群角色用于Pod的授权访问,下面的文件内容为集群角色的配置示例:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: ignite
namespace: ignite
rules:
- apiGroups:
- ""
resources: # Here are the resources you can access
- pods
- endpoints
verbs: # That is what you can do with them
- get
- list
- watch
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: ignite
roleRef:
kind: Role
name: ignite
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: ignite
namespace: ignite
执行下面的命令创建角色和角色绑定:
kubectl create -f cluster-role.yaml
为节点配置创建ConfigMap
需要创建一个ConfigMap,用于持有每个节点使用的配置文件,这样可以使所有的节点共享同一个配置文件实例。
首先要创建一个配置文件,根据是否持久化,选择下面某个选项卡:
IP探测器配置的namespace和serviceName属性必须与服务配置中指定的一致,其他的属性可以按需配置。
在上述配置文件所在的目录中执行下面的命令,可以创建一个ConfigMap:
kubectl create configmap ignite-config -n ignite --from-file=node-configuration.xml
创建Pod配置
下面需要创建Pod的配置,对于无状态部署,需要使用Deployment,对于有状态的部署,需要使用StatefulSet。
$ kubectl get pods -n ignite
NAME READY STATUS RESTARTS AGE
ignite-cluster-5b69557db6-lcglw 1/1 Running 0 44m
ignite-cluster-5b69557db6-xpw5d 1/1 Running 0 44m
确认节点的日志:
$ kubectl logs ignite-cluster-5b69557db6-lcglw -n ignite
...
[14:33:50] Ignite documentation: http://gridgain.com
[14:33:50]
[14:33:50] Quiet mode.
[14:33:50] ^-- Logging to file '/opt/gridgain/work/log/ignite-b8622b65.0.log'
[14:33:50] ^-- Logging by 'JavaLogger [quiet=true, config=null]'
[14:33:50] ^-- To see **FULL** console log here add -DIGNITE_QUIET=false or "-v" to ignite.{sh|bat}
[14:33:50]
[14:33:50] OS: Linux 4.19.81 amd64
[14:33:50] VM information: OpenJDK Runtime Environment 1.8.0_212-b04 IcedTea OpenJDK 64-Bit Server VM 25.212-b04
[14:33:50] Please set system property '-Djava.net.preferIPv4Stack=true' to avoid possible problems in mixed environments.
[14:33:50] Initial heap size is 30MB (should be no less than 512MB, use -Xms512m -Xmx512m).
[14:33:50] Configured plugins:
[14:33:50] ^-- None
[14:33:50]
[14:33:50] Configured failure handler: [hnd=StopNodeOrHaltFailureHandler [tryStop=false, timeout=0, super=AbstractFailureHandler [ignoredFailureTypes=UnmodifiableSet [SYSTEM_WORKER_BLOCKED, SYSTEM_CRITICAL_OPERATION_TIMEOUT]]]]
[14:33:50] Message queue limit is set to 0 which may lead to potential OOMEs when running cache operations in FULL_ASYNC or PRIMARY_SYNC modes due to message queues growth on sender and receiver sides.
[14:33:50] Security status [authentication=off, tls/ssl=off]
[14:34:00] Nodes started on local machine require more than 80% of physical RAM what can lead to significant slowdown due to swapping (please decrease JVM heap size, data region size or checkpoint buffer size) [required=918MB, available=1849MB]
[14:34:01] Performance suggestions for grid (fix if possible)
[14:34:01] To disable, set -DIGNITE_PERFORMANCE_SUGGESTIONS_DISABLED=true
[14:34:01] ^-- Enable G1 Garbage Collector (add '-XX:+UseG1GC' to JVM options)
[14:34:01] ^-- Specify JVM heap max size (add '-Xmx[g|G|m|M|k|K]' to JVM options)
[14:34:01] ^-- Set max direct memory size if getting 'OOME: Direct buffer memory' (add '-XX:MaxDirectMemorySize=[g|G|m|M|k|K]' to JVM options)
[14:34:01] ^-- Disable processing of calls to System.gc() (add '-XX:+DisableExplicitGC' to JVM options)
[14:34:01] Refer to this page for more performance suggestions: https://apacheignite.readme.io/docs/jvm-and-system-tuning
[14:34:01]
[14:34:01] To start Console Management & Monitoring run ignitevisorcmd.{sh|bat}
[14:34:01] Data Regions Configured:
[14:34:01] ^-- default [initSize=256.0 MiB, maxSize=370.0 MiB, persistence=false, lazyMemoryAllocation=true]
[14:34:01]
[14:34:01] Ignite node started OK (id=b8622b65)
[14:34:01] Topology snapshot [ver=2, locNode=b8622b65, servers=2, clients=0, state=ACTIVE, CPUs=2, offheap=0.72GB, heap=0.88GB]
最后一行的servers=2,显示两个节点已经组成了集群。
就绪探针 Ignite的probeREST命令可用于确定Ignite内核是否已经启动。
存活探针
Ignite的versionREST命令可用于确定Ignite正在正常运行。
# 4.5.3.激活集群
如果部署的是无状态的集群,那么可以忽略这一步,未开启持久化的集群不需要激活。
如果开启了持久化,那么启动后必须激活集群。这需要接入某个Pod:
kubectl exec -it <pod_name> -n ignite -- /bin/bash
然后执行如下的命令:
/opt/ignite/apache-ignite/bin/control.sh --set-state ACTIVE --yes
还可以使用REST API激活集群,下面的章节会介绍如何通过REST API接入集群。
# 4.5.4.集群扩容
可以使用kubectl scale命令对集群进行扩容。
警告
首先要确认Amazon EKS集群上有足够的资源添加新的节点。
下面的示例中,会添加一个新的节点(现在是两个)。
警告
如果减少的节点数多于分区备份数,可能会丢失数据,缩容的正确方式是通过调整基线拓扑删除节点后,进行数据重新分布。
# 4.5.5.接入集群
如果应用也运行于Kubernetes中,可以使用瘦客户端,也可以使用客户端节点接入集群。
获取服务的开放IP地址:
$ kubectl describe svc ignite-service -n ignite
Name: ignite-service
Namespace: ignite
Labels: app=ignite
Annotations: <none>
Selector: app=ignite
Type: LoadBalancer
IP: 10.0.144.19
LoadBalancer Ingress: 13.86.186.145
Port: rest 8080/TCP
TargetPort: 8080/TCP
NodePort: rest 31912/TCP
Endpoints: 10.244.1.5:8080
Port: thinclients 10800/TCP
TargetPort: 10800/TCP
NodePort: thinclients 31345/TCP
Endpoints: 10.244.1.5:10800
Session Affinity: None
External Traffic Policy: Cluster
可以使用LoadBalancer Ingress的地址来接入开放的端口之一,端口列表在命令的输出中已经列出。
客户端节点接入
客户端节点需要接入集群中的每个节点,唯一的方式就是在Kubernetes中启动一个客户端节点,需要将发现机制配置为使用TcpDiscoveryKubernetesIpFinder,前述创建ConfigMap时已经介绍过。
瘦客户端接入
下面的代码片段说明了如何通过Java瘦客户端接入集群,其他瘦客户端也是同样的方式,注意这里使用了服务的开放IP地址(LoadBalancer Ingress)。
ClientConfiguration cfg = new ClientConfiguration().setAddresses("13.86.186.145:10800");
IgniteClient client = Ignition.startClient(cfg);
ClientCache<Integer, String> cache = client.getOrCreateCache("test_cache");
cache.put(1, "first test value");
System.out.println(cache.get(1));
client.close();
分区感知
分区感知使得瘦客户端可以将请求直接发给待处理数据所在的节点。
在没有分区感知时,通过瘦客户端接入集群的应用,实际是通过某个作为代理的服务端节点执行所有查询和操作,然后将这些操作重新路由到数据所在的节点,这会导致瓶颈,可能会限制应用的线性扩展能力。
注意查询必须通过代理服务端节点,然后路由到正确的节点。
有了分区感知之后,瘦客户端可以将查询和操作直接路由到持有待处理数据的主节点,这消除了瓶颈,使应用更易于扩展。
要在Kubernetes环境中启用分区感知功能,应在集群中启动一个客户端,并使用KubernetesConnectionConfiguration对其进行配置,这时客户端就可以接入集群中的每个Pod。
KubernetesConnectionConfiguration kcfg = new KubernetesConnectionConfiguration();
kcfg.setNamespace("ignite");
kcfg.setServiceName("ignite-service");
ClientConfiguration ccfg = new ClientConfiguration();
ccfg.setAddressesFinder(new ThinClientKubernetesAddressFinder(kcfg));
IgniteClient client = Ignition.startClient(cfg);
ClientCache<Integer, String> cache = client.getOrCreateCache("test_cache");
cache.put(1, "first test value");
System.out.println(cache.get(1));
client.close();
REST API接入
REST API接入集群的方式如下:
$ curl http://13.86.186.145:8080/ignite?cmd=version
{"successStatus":0,"error":null,"response":"2.14.0","sessionToken":null}
# 5.在VMWare中安装Ignite
# 5.1.概述
Ignite可以部署于VMWare管理的虚拟和云环境,没有什么和VMWare有关的特性,不过建议将Ignite实例绑定到一个单一专用的主机,这样可以:
- 避免当Ignite实例与其它应用程序争用主机资源时,导致Ignite集群的性能出现峰值;
- 确保高可用,如果一台主机宕机并且有两个或者多个Ignite服务端节点绑定到上面,那么可能导致数据丢失。
下面的内容会说明和Ignite节点迁移有关的vMotion的使用。
# 5.2.使用vMotion进行节点迁移
vMotion可以将一个在线的实例从一台主机迁移到另一台,但是迁移之后Ignite依赖的一些基本要求要得到满足:
- 新主机有相同的内存状态;
- 新主机有相同的磁盘状态(或新主机使用相同的磁盘);
- IP地址、可用的端口以及其它的网络参数没有变化;
- 所有的网络资源可用,TCP连接没有中断。
如果vMotion按照上述规则设置并工作,则Ignite节点将正常工作。
不过vMotion迁移将影响Ignite实例的性能。在传输过程中,许多资源(主要是CPU和网络)将服务于vMotion的需要。
为了避免集群一段时间内的性能下降甚至无响应,建议如下:
- 在Ignite集群的低活跃和负载期间执行迁移。这确保了更快的传输,同时对集群性能影响最小;
- 如果必须迁移多个节点,则需要一个个按顺序地执行节点的迁移;
- 将
IgniteConfiguration.failureDetectionTimeout参数设置为高于Ignite实例的可能停机时间的值。这是因为当剩下一小块状态要传输时,vMotion将停止Ignite实例的CPU。假定传输该数据块需要X时间,那么IgniteConfiguration.failureDetectionTimeout必须大于X;否则节点将从集群中删除; - 使用高吞吐量网络。最好vMotion迁移器和Ignite集群使用不同的网络来避免网络饱和;
- 优先选择内存较少的节点,较小内存的Ignite实例确保更快的vMotion迁移,更快的迁移确保Ignite集群更稳定的操作;
- 如果业务允许,甚至可以考虑在Ignite实例停机时进行迁移。假设集群中的其它节点上有数据的备份副本,则可以先将该节点关闭,然后在vMotion迁移结束后恢复该节点,这样和在线迁移相比,可能总体性能更好(集群的性能和vMotion传输时间)。
# 6.版本升级
升级是任何软件系统生命周期的重要组成部分,本章节介绍了升级Apache Ignite版本的基本建议。
# 6.1.升级注意事项
升级节点版本就像用新版本替换Apache Ignite二进制文件一样简单。但是,在执行升级时如下几点需要注意:
- Ignite集群的各个节点,需要运行相同的Ignite版本,因此升级时需要停止整个集群,然后在新的版本上重新启动。
- 在升级过程中,可能会意外覆盖持久化文件或其他重要数据,所以建议事先将此数据文件移出安装文件夹:
18624049226

← 快速入门 Ignite配置入门 →