# 机器学习
# 1.机器学习
# 1.1.概述
IgniteML(机器学习)是一组简单的、可扩展以及高效的工具,在不需要成本高昂的数据转换的前提下,就可以构建可预测的机器学习模型。
将机器和深度学习加入Ignite的原理是很简单的,当前,如果要想让机器学习成为主流,数据科学家要解决两个主要的问题:
- 首先,模型是在不同的系统中训练和部署(训练结束之后)的,数据科学家需要等待ETL或者其它的数据传输过程,来将数据移至比如Apache Mahout或者Apache Spark这样的系统进行训练,然后还要等待这个过程结束并且将模型部署到生产环境。在系统间移动TB级的数据可能花费数小时的时间,此外,训练部分通常发生在旧的数据集上;
- 第二个问题和扩展性有关。机器学习和深度学习需要处理的数据量不断增长,已经无法放在单一的服务器上。这促使数据科学家要么提出更复杂的解决方案,要么切换到比如Spark或者TensorFlow这样的分布式计算平台上。但是这些平台通常只能解决模型训练的一部分问题,这给开发者之后的生产部署带来了很多的困难。
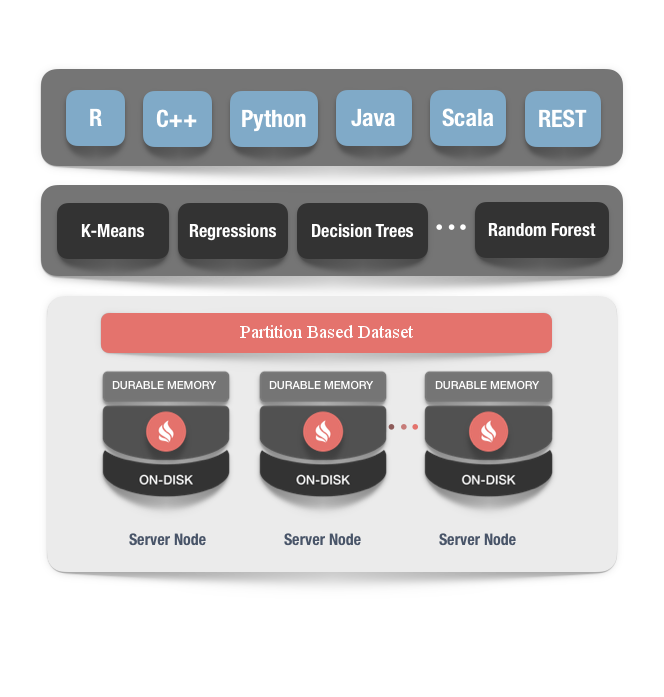
无ETL和大规模可扩展性
IgniteML依赖于Ignite基于内存的存储,这给机器学习和深度学习任务带来了大规模的扩展性,并且取消了在不同系统间进行ETL产生的等待。比如,在Ignite集群的内存和磁盘中存储的数据上,开发者可以直接进行深度学习和机器学习的训练和推理,然后,Ignite提供了一系列的机器学习和深度学习算法,对Ignite的分布式并置处理进行优化,这样在处理大规模的数据集或者不断增长的输入数据流时,这样的实现提供了内存级的速度和近乎无限的扩展性,而不需要将数据移到另外的存储。通过消除数据的移动以及长时间的处理等待,IgniteML可以持续地进行学习,可以在最新数据到来之时实时地对决策进行改进。
容错和持续学习
IgniteML能够对节点的故障容错。这意味着如果在学习期间节点出现故障,所有的恢复过程对用户是透明的,学习过程不会被中断,就像所有节点都正常那样获得结果。
# 1.2.算法和适用领域
分类
根据训练的数据集,对标的的种类进行标识。
适用领域:垃圾邮件检测、图像识别、信用评分、疾病识别。
算法:逻辑回归、线性SVM(支持向量机)、k-NN分类、朴素贝叶斯、决策树、随机森林、多层感知、梯度提升、近似最近邻。
回归
对因变量(y)与一个或多个解释变量(或自变量)(x)之间的关系进行建模。
适用领域:药物反应,股票价格,超市收入。
算法:线性回归、决策树回归、k-NN回归。
聚类
对对象进行分组的方式,即在同一个组(叫做簇)中的对象(某种意义上)比其它组(簇)中的对象更相似。
适用领域:客户细分、实验结果分组、购物项目分组。
算法:K均值聚类、高斯混合(GMM)
推荐
建立推荐系统,它是信息过滤系统的子类,旨在预测用户对项目的“评价”或“偏好”。
适用领域:用于视频和音乐服务的播放列表生成器,用于服务的产品推荐器。
算法:矩阵分解。
预处理
特征提取和归一化。
适用领域:对比如文本这样的输入数据进行转换,以便用于机器学习算法,然后提取需要拟合的特征,对数据进行归一化。
算法:IgniteML支持在分区化的数据集之上自定义预处理器,同时也有默认的预处理器,比如归一化预处理器、独热编码、离差标准化等。
# 1.3.入门
机器学习入门的最快方式是构建和运行示例代码,学习它的输出和代码,机器学习的示例代码位于Ignite二进制包的examples文件夹中。
下面是相关的步骤:
- 下载Ignite的2.8及以后的版本;
- 在比如IntelliJ IDEA或者Eclipse这样的IDE中打开
examples工程; - 在IDE中打开
src/main/java/org/apache/ignite/examples/ml文件夹然后运行机器学习的示例。
这些示例不需要特别的配置,所有的机器学习示例在没有人为干预的情况下,都可以正常地启动、运行、停止,然后在控制台中输出有意义的信息。另外,还支持一个跟踪器API示例,它会启动一个Web浏览器然后生成一些HTML输出。
通过Maven获取
在工程中像下面这样添加Maven依赖后,就可以使用Ignite提供的机器学习功能:
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-ml</artifactId>
<version>${ignite.version}</version>
</dependency>
将${ignite-version}替换为实际使用的Ignite版本。
从源代码构建
IgniteML最新版的jar包已经上传到Maven仓库,如果需要获取该jar包然后部署到特定的环境中,那么要么从Maven仓库中进行下载,或者从源代码进行构建,如果要从源代码进行构建,按照如下步骤进行操作:
- 下载Ignite最新版本的源代码;
- 清空Maven的本地仓库(这个是避免旧版本的可能影响);
- 从工程的根目录构建并安装Ignite;
./mvnw clean install -DskipTests -Dmaven.javadoc.skip=true
- 在本地仓库的
{user_dir}/.m2/repository/org/apache/ignite/ignite-ml/{ignite-version}/ignite-ml-{ignite-version}.jar中找到机器学习的jar包; - 如果要从源代码构建ML或者DL的示例,执行如下的命令:
cd examples
mvn clean package -DskipTests
如果必要,可以参考项目根目录的DEVNOTES.txt文件以及ignite-ml模块的README文件,以了解更多的信息。
# 2.预处理
# 2.1.概述
预处理是将存储于Ignite中的原始数据转换为特征向量,以便于机器学习流水线的进一步使用。
本节介绍用于处理特征的算法,大致分为以下几组:
- 从“原始”数据中提取特征
- 缩放特性
- 转换特性
- 修改特性
注意
通过矢量化器,通常它从标签和特征提取开始,并且可以与其它预处理阶段兼容。
# 2.2.归一化预处理器
通常的流程是从Ignite数据中通过矢量化器提取特征和标签,对特征进行转换然后对其进行归一化。
除了能够构建任何自定义预处理器之外,Ignite还提供了内置的归一化预处理器,该预处理器使用p范数对每个向量进行归一化。
为了进行归一化,需要创建NormalizationTrainer,然后将其与归一化预处理器进行匹配,如下所示:
// Train the preprocessor on the given data
Preprocessor<Integer, Vector> preprocessor = new NormalizationTrainer<Integer, Vector>()
.withP(1)
.fit(ignite, data, vectorizer);
// Create linear regression trainer.
LinearRegressionLSQRTrainer trainer = new LinearRegressionLSQRTrainer();
// Train model.
LinearRegressionModel mdl = trainer.fit(
ignite,
upstreamCache,
preprocessor
);
# 2.3.示例
要了解归一化预处理器在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
# 2.4.二值化预处理器
二值化是将数值特征阈值化为二元(0/1)特征的过程。大于阈值的特征值被二值化为1.0,等于或小于阈值的值被二值化为0.0。
它只包含一个重要参数,即阈值。
// Create binarization trainer.
BinarizationTrainer<Integer, Vector> binarizationTrainer
= new BinarizationTrainer<>().withThreshold(40);
// Build the preprocessor.
Preprocessor<Integer, Vector> preprocessor = binarizationTrainer
.fit(ignite, data, vectorizer);
要了解二值化预处理器在实践中如何使用,可以尝试这个示例。
# 2.5.填补预处理器
填补预处理器是使用缺失值所在的列的平均值或其它统计信息来填补数据集中的缺失值。缺失的值应该表示为Double类型的NaN,输入数据集列应该是Double。目前,填补预处理器不支持分类特性,并且可能为包含分类特性的列创建不正确的值。
在训练阶段,填补训练器收集关于预处理数据集的统计数据,在预处理阶段,它根据收集的统计数据修改数据。
填补训练器只包含一个参数:imputingStgy,它的类型为ImputingStrategy枚举,有两个可用值(注意:将来的版本可能支持更多值):
MEAN:默认策略。如果选择此策略,则使用沿轴的数字特征的平均值替换缺失的值;MOST_FREQUENT:如果选择此策略,则使用沿轴最频繁的值替换缺失的值。
// Create imputer trainer.
ImputerTrainer<Integer, Vector>() imputerTrainer =
new ImputerTrainer<>().withImputingStrategy(ImputingStrategy.MOST_FREQUENT);
// Train imputer preprocessor.
Preprocessor<Integer, Vector> preprocessor = new ImputerTrainer<Integer, Vector>()
.fit(ignite, data, vectorizer);
如果要了解填补预处理器在实践中是如何使用的,可以尝试这两个示例:示例1和示例2。
# 2.6.独热编码器预处理器
独热编码将分类特征,表示为标签索引(双精度值或字符串值)映射到二元向量,该二元向量最多只有一个值,该值表示来自所有特征值集合中的特定特征值的抽象。
该预处理器可以转换多个列,其中在训练过程中处理索引。可以通过.withEncodedFeature(featureIndex)调用定义这些索引。
注意
每个独热编码的二元向量将其单元添加到当前特征向量的末尾:
- 这个预处理器总是为NULL值创建单独的列;
- 与NULL相关联的索引值将根据NULL值的频率位于二元向量中。
在训练阶段,StringEncoderPreprocessor和OneHotEncoderPreprocessor使用相同的EncoderTraining来收集关于分类特征的数据,为了用独热编码预处理器对数据集进行预处理,需要将encoderType配置为EncoderType.ONE_HOT_ENCODER,如下面的代码片段所示:
Preprocessor<Integer, Object[]> encoderPreprocessor = new EncoderTrainer<Integer, Object[]>()
.withEncoderType(EncoderType.ONE_HOT_ENCODER)
.withEncodedFeature(0)
.withEncodedFeature(1)
.withEncodedFeature(4)
.fit(ignite,
dataCache,
vectorizer
);
# 2.7.字符串编码器预处理器
字符串编码器将字符串值(分类)编码为范围[0.0,amountOfCategories]中的Double类型值,其中最流行的值将显示为0.0,最不流行的值将显示为amountOfCategories-1值。
该预处理器可以转换多个列,其中在训练过程中处理索引。可以通过.withEncodedFeature(featureIndex)调用定义这些索引。
注意:它不添加新列,而是直接修改数据。
示例
假定有下面的数据集,有id和category两个特征列:
| Id | Category |
|---|---|
| 0 | a |
| 1 | b |
| 2 | c |
| 3 | a |
| 4 | a |
| 5 | c |
| Id | Category |
|---|---|
| 0 | 0.0 |
| 1 | 2.0 |
| 2 | 1.0 |
| 3 | 0.0 |
| 4 | 0.0 |
| 5 | 1.0 |
a的索引值为0,因为它是最频繁的,随后是c,索引值为1,然后b是2。
注意
就如何处理不可见标签而言,当使用StringEncoder给一个数据集编码然后用它又去转换另一个数据集时,只有一个策略:将不可见标签放入一个特殊的附加桶中,索引值等于amountOfCategories。
在训练阶段,StringEncoderPreprocessor和OneHotEncoderPreprocessor使用相同的EncoderTraning来收集与分类特征有关的数据。要使用StringEncoderPreprocessor对数据集进行预处理,需要将encoderType配置为EncoderType.STRING_ENCODER,如下面的代码片段所示:
Preprocessor<Integer, Object[]> encoderPreprocessor
= new EncoderTrainer<Integer, Object[]>()
.withEncoderType(EncoderType.STRING_ENCODER)
.withEncodedFeature(1)
.withEncodedFeature(4)
.fit(ignite,
dataCache,
vectorizer
);
如果要了解字符串编码器或者OHE在实践中如何使用,可以尝试这个示例。
# 2.8.离差标准化预处理器
最小最大值缩放转换给定的数据集,将每个特性重新缩放到某个范围。
从数学的角度来看,它是将如下函数应用于数据集中的每个元素:
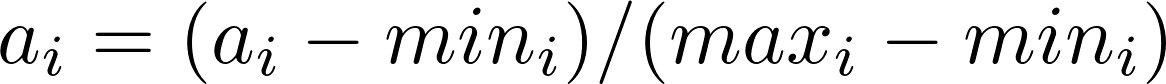
对于所有i,其中i是许多列,max_i是这个列中最大元素的值,min_i是这个列中最小元素的值。
// Create min-max scaler trainer.
MinMaxScalerTrainer<Integer, Vector> trainer = new MinMaxScalerTrainer<>();
// Build the preprocessor.
Preprocessor<Integer, Vector> preprocessor = trainer
.fit(ignite, data, vectorizer);
MinMaxScalerTrainer计算数据集上的汇总统计数据,并生成MinMaxScalerPreprocessor,然后该预处理器可以单独地转换每个特征,使得其在给定范围内。
要了解这个预处理器在实践中是如何使用的,可以尝试这个示例。
# 2.9.绝对值最大标准化预处理器
绝对值最大标准化预处理器转换给定的数据集,通过除以每个特征中的最大绝对值,将每个特征重新调整到范围[-1,1]。
注意
它不会移动/居中数据,因此不会破坏任何稀疏性。
// Create max-abs trainer.
MaxAbsScalerTrainer<Integer, Vector> trainer = new MaxAbsScalerTrainer<>();
// Build the preprocessor.
Preprocessor<Integer, Vector> preprocessor = trainer
.fit(ignite, data, vectorizer);
从数学的角度来看,它是将如下函数应用于数据集中的每个元素:
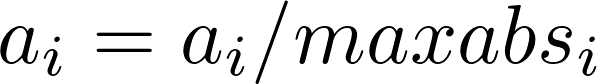
对于所有i,其中i是一些列,maxabs_i是这个列中绝对值最大的元素的值。
MaxAbsScalerTrainer计算数据集上的汇总统计数据,并生成MaxAbsScalerPreprocessor。
要了解这个预处理器在实践中是如何使用的,可以尝试这个示例。
# 3.分区化的数据集
# 3.1.概述
分区化的数据集是在Ignite的计算和存储能力之上构建的抽象层,可以在遵循无ETL和容错的原则下,进行算法运算。
分区化的数据集的主要原理是Ignite的计算网格实现的经典MapReduce范式。
MapReduce的主要优势在于,可以在分布于整个集群的数据上进行计算,而不需要大量的网络数据移动,这个想法通过如下方式对应于分区化的数据集:
- 每个数据集都是分区的;
- 分区在每个节点的本地,持有持久化的训练上下文以及可恢复的训练数据;
- 在一个数据集上执行的计算,会被拆分为Map操作和Reduce操作,Map操作负责在每个分区上执行运算,而Reduce操作会将Map操作的结果汇总为最终的结果。
训练上下文(分区上下文) 是Ignite分区中的持久化部分,因此在分区化的数据集关闭之前,对应于这部分的变更都会被一直维护,训练上下文不用担心节点故障,但是需要额外的时间进行读写,因此只有在无法使用分区数据的时候才使用它。
训练数据(分区数据) 是分区的一部分,可以在任何时候从上游数据以及上下文中恢复,因此没必要在持久化存储中维护分区数据,而是在每个节点的本地存储(堆内、堆外甚至GPU存储)中持有,如果节点故障,可以从其它节点的上游数据以及上下文中恢复。
为什么选择分区而不是节点作为数据集和学习的构建单元呢?
Ignite中的一个基本思想是,分区是原子化的,这意味着分区无法在多个节点上进行拆分。在再平衡或者节点故障的情况下,分区在其它节点恢复时,数据和它在原来节点时保持一致。
而在机器学习算法中,这很重要,因为大多数机器学习算法是迭代的,并且需要在迭代之间保持一定的上下文,该上下文无法被拆分或者合并,并且应该在整个学习期间保持一致的状态。
# 3.2.使用
要构造一个分区化的数据集,可以这么做:
- 有一个上游的数据源,可以是Ignite的缓存或者仅仅是一个数据的Map;
- 分区上下文生成器,它定义了如何从对应于该分区的上游数据构建分区上下文;
- 分区数据生成器,它定义了如何从对应于该分区的上游数据构建分区数据;
基于缓存的数据集:
Dataset<MyPartitionContext, MyPartitionData> dataset =
new CacheBasedDatasetBuilder<>(
ignite, // Upstream Data Source
upstreamCache
).build(
new MyPartitionContextBuilder<>(), // Training Context Builder
new MyPartitionDataBuilder<>() // Training Data Builder
);
本地数据集:
Dataset<MyPartitionContext, MyPartitionData> dataset =
new LocalDatasetBuilder<>(
upstreamMap, // Upstream Data Source
10
).build(
new MyPartitionContextBuilder<>(), // Partition Context Builder
new MyPartitionDataBuilder<>() // Partition Data Builder
);
之后就可以在这个数据集上通过MapReduce的方式执行各种计算了。
int numerOfRows = dataset.compute(
(partitionData, partitionIdx) -> partitionData.getRows(),
(a, b) -> a == null ? b : a + b
);
最后,所有的计算完成后,注意一定要关闭数据集和释放资源。
dataset.close();
# 3.3.示例
要了解分区化的数据集在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
# 4.模型更新
# 4.1.概述
IgniteML中的模型更新接口使用之前训练过的模型的状态,支持在新数据上对已培训模型的重新学习。此接口表示为DatasetTrainer类,它以已学习过的模型作为第一个参数重复训练:
- M update (
M mdl, DatasetBuilder<K, V> datasetBuilder, IgniteBiFunction<K, V, Vector> featureExtractor, IgniteBiFunction<K, V, L> lbExtractor); - M update (
M mdl, Ignite ignite, IgniteCache<K, V> cache, IgniteBiFunction<K, V, Vector> featureExtractor, IgniteBiFunction<K, V, L> lbExtractor); - M update (
M mdl, Ignite ignite, IgniteCache<K, V> cache, IgniteBiPredicate<K, V> filter, IgniteBiFunction<K, V, Vector> featureExtractor, IgniteBiFunction<K, V, L> lbExtractor); - M update(
M mdl, Map<K, V> data, int parts, IgniteBiFunction<K, V, Vector> featureExtractor, IgniteBiFunction<K, V, L> lbExtractor); - M update (
M mdl, Map<K, V> data, IgniteBiPredicate<K, V> filter, int parts, IgniteBiFunction<K, V, Vector> featureExtractor, IgniteBiFunction<K, V, L> lbExtractor)。
该接口提供在线学习和在线批量学习。在线学习意味着可以训练一个模型,当得到一个新的学习样本时,比如点击一个网站,就可以更新这个模型,就像这个模型也是在这个样本上训练的一样。在线批量学习需要一批样本,而不是一个用于模型更新的训练样本。有些模型允许两种更新策略,有些只允许批量更新。这取决于学习算法。有关在线和在线批量学习方面的模型更新功能的更多详细信息,请参见下文。
注意
新的部分数据应该与之前训练的参数和数据集兼容,包括特征向量大小和特征值分布方面。比如,如果训练一个ANN模型,那么应该为训练器提供之前学习阶段的距离测量和候选参数计数。如果更新k均值,则新数据集应至少包含k行。
每个模型都有这个接口的特殊实现。下面会介绍每个算法的更新过程的更多内容。
# 4.2.K均值
模型更新采用已学习的质心,并通过新行更新它们。建议对此模型使用在线批量学习。首先,数据集的大小至少应等于k值。第二,具有少量行的数据集可以将质心移动到无效位置。
# 4.3.KNN
模型更新只是向旧数据集添加一个新的数据集。在这种情况下,模型更新不受限制。
# 4.4.ANN
与KNN一样,新训练器应提供相同的距离测量值和K值。这些参数很重要,因为在内部,人工神经网络使用K均值和K均值提供的质心统计数据。在更新过程中,训练器从之前学习中获取有关质心的统计信息,并用新的观察结果更新。从这个角度来看,ANN允许小批量在线学习,其中批量大小等于k参数。
# 4.5.神经网络(NN)
神经网络更新只是获取当前的神经网络状态,并根据新数据集上的误差梯度进行更新。在这种情况下,神经网络只需要不同数据集之间的特征向量兼容性。
# 4.6.逻辑回归
逻辑回归继承了神经网络训练器的所有限制,因为它在内部使用感知器。
# 4.7.线性回归
LinearRegressionSGD训练器继承了神经网络训练器的所有限制。LinearRegressionLSQRTrainer从上一次学习中恢复状态,并将其用作新数据集学习的第一近似值。这样,LinearRegressionLSQRTrainer也只需要特征向量的兼容性。
# 4.8.SVM
SVM训练器在训练过程中使用学习模型的状态作为第一近似值。从这个角度来看,该算法只需要特征向量的兼容性。
# 4.9.决策树
没有正确的决策树更新实现。更新会在给定的数据集上学习新模型。
# 4.10.GDB
GDB训练器更新已经从组合中学习了模型,并试图通过学习新模型预测梯度来最小化给定数据集上的误差梯度。它还使用收敛检查器,如果新数据集上没有大的误差,那么GDB会跳过更新阶段。因此GDB只需要特征向量兼容性。
注意:每次更新都会增加模型组成大小。所有的模型都互相依赖。因此,基于小数据集的频繁更新可以产生一个需要大量内存的巨大模型。
# 4.11.随机森林(RF)
RF训练器只需在给定的数据集上学习新的决策树,并将它们添加到已经学习过的合成中。通过这种方式,RF需要特征向量兼容性,并且数据集的大小应该大于一个元素,因为决策树不能在如此小的数据集上进行训练。与经过训练的合成中的GDB模型不同,RF模型彼此不依赖,如果合成太大,用户可以手动删除一些模型。
# 5.二元分类
在机器学习和统计学中,分类是基于包含已知类别关系的观察值(或实例)的训练数据集来确定新观察值属于哪个类别(子种群)的问题。
本节介绍的所有训练算法都是为解决二元分类任务而设计的。
# 5.1.线性SVM(支持向量机)
支持向量机(SVM)是相关数据分析学习算法中的监督学习模型,用于分类和回归分析。
给定一组训练样本,每一个被标记为属于两个类别中的一个,SVM训练算法会建立一个模型,该模型将新的样本分配给其中一个类别,使其成为非概率二元线性分类器。
IgniteML模块只支持线性SVM。更多信息请参见维基百科中的SVM。
# 5.1.1.模型
SVM的模型表示为SVMLinearClassificationModel,它通过如下的方式对给定的特征向量进行预测:
SVMLinearClassificationModel model = ...;
double prediction = model.predict(observation);
目前,对于SVMLinearClassificationModel,Ignite支持一组参数:
isKeepingRawLabels:-1,和+1,分别对应false值和从分离超平面的原始距离(默认值false);threshold:如果原始值大于该阈值(默认值:0.0),则向观察者分配1个标签。
SVMLinearBinaryClassificationModel model = ...;
double prediction = model
.withRawLabels(true)
.withThreshold(5)
.predict(observation);
# 5.1.2.训练器
基于具有铰链损失函数的高效通信分布式双坐标上升算法(COCOA),提供软余量SVM线性分类训练器的基类。该训练器将输入作为具有-1和+1两个分类的标签化数据集,并进行二元分类。
关于这个算法的论文可以在这里找到。
目前,Ignite为SVMLinearClassificationTrainer支持如下参数:
amountOfIterations:外部SDCA算法的迭代量。(默认值:200);amountOfLocIterations:本地SDCA算法的迭代量。(默认值:100);lambda:正则化参数(默认值:0.4);seed:有助于重现模型的初始化参数之一(训练器在权重向量更新的局部迭代过程中使用随机数选择观察值)。
// Set up the trainer
SVMLinearClassificationTrainer trainer = new SVMLinearClassificationTrainer()
.withAmountOfIterations(AMOUNT_OF_ITERATIONS)
.withAmountOfLocIterations(AMOUNT_OF_LOC_ITERATIONS)
.withLambda(LAMBDA);
// Build the model
SVMLinearBinaryClassificationModel mdl = trainer.fit(
ignite,
dataCache,
vectorizer
);
# 5.1.3.示例
要了解SVM线性分类器在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
训练数据集可以从UCI机器学习库加载,其是鸢尾花数据集的子集(具有标签1和标签2的分类,它们是线性可分离的两类数据集)。
# 5.2.决策树
决策树及其集成是用于分类和回归的机器学习任务的流行方法。决策树由于其易于解释、处理分类特征,扩展到多类分类设置,不需要特征缩放,并且能够捕获非线性和特征交互等优点而被广泛使用。随机森林和提升等树集成算法是分类和回归任务中表现最好的算法之一。
# 5.2.1.概述
决策树是监督学习中一个简单而强大的模型。其主要思想是将特征空间分割成区域,每个区域中的值变化不大。一个区域中的值变化的度量被称为区域的纯度。
Ignite对于行数据存储,提供了一种优化算法,具体可以看分区化的数据集。
拆分是递归进行的,每次拆分创建的区域又可以进一步拆分,因此,整个过程可以用二叉树来描述,其中每个节点都代表一个特定的区域,其子节点为由另一个拆分派生出来的区域。
让一个训练集的每个样本独属于一些空间S,并且让p_i成为具有索引i的特征的一个预测,然后通过具有索引i的连续特征进行拆分:
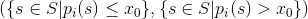 由分类特征和某些集合
由分类特征和某些集合x的值进行拆分:
 这里
这里X_0是x的一个子集。
该模型的工作方式:当算法达到配置的最大深度,或者任何区域的拆分都没有导致明显的纯度损失时,拆分过程就会停止。对从S到点s的值的预测是将树向下遍历,直到节点对应的区域包含s,并返回与此叶子相关联的值。
# 5.2.2.模型
决策树分类的模型由DecisionTreeModel表示,对于给定的特征向量进行预测,如下所示:
DecisionTreeModel mdl = ...;
double prediction = mdl.apply(observation);
模型是完全独立的对象,训练之后可以保存、序列化以及恢复。
# 5.2.3.训练器
决策树算法可用于基于纯度度量和节点实例化方法的分类和回归。
分类
分类决策树可用于Gini纯度度量,使用方法如下:
// Create decision tree classification trainer.
DecisionTreeClassificationTrainer trainer = new DecisionTreeClassificationTrainer(
4, // Max deep.
0 // Min impurity decrease.
);
// Train model.
DecisionTreeModel mdl = trainer.fit(ignite, dataCache, vectorizer);
# 5.2.4.示例
要了解决策树在实践中是如何使用的,可以看这个分类示例,这些示例也会随着每个Ignite版本进行发布。
# 5.3.多层感知
# 5.3.1.概述
多层感知(MLP)是神经网络的基本形式,它由一个输入层和0或多个转换层组成,每个转换层都通过如下的方程依赖于前一个转换层:
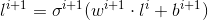 在上面的方程中,点运算符是两个向量的点积,由σ表示的函数称为激活函数,
在上面的方程中,点运算符是两个向量的点积,由σ表示的函数称为激活函数,w表示的向量称为权重,b表示的向量成为偏差。每个转换层都和权重、激活以及可选的偏差有关,MLP中中所有权重和偏差的集合,就被称为MLP的参数集。
# 5.3.2.模型
神经网络的模型由MultilayerPerceptron类表示,它可以对给定的特征向量通过如下方式进行预测:
MultilayerPerceptron mlp = ...
Matrix prediction = mlp.apply(observation);
模型是完全独立的对象, 训练后可以保存、序列化和恢复。
# 5.3.3.训练器
批量训练是监督模型训练的常用方法之一。在这种方法中,训练是迭代进行的,在每次迭代中,提取标记数据的subpart(batch)(由近似函数的输入和该函数的相应值组成的数据,通常称为“地面实况”),在这里使用这个子部分训练和更新模型参数,进行更新以使批处理中的损失函数最小化。
Ignite的MLPTrainer就是用于分布式批量训练的,它运行于MapReduce模式,每个迭代(称为全局迭代)由若干个并行迭代组成,这些迭代又相应地由若干局部步骤组成,每个局部迭代由它自己的工作进程来执行,并执行指定数量的本地步骤(成为同步周期)来计算模型参数的更新,然后会在发起训练的节点上累计所有的更新,并将其转换为全局更新,全局更新会被反馈给所有的工作进程,在达到标准之前,这个过程会一直持续。
MLPTrainer是参数化的,其中包括神经网络架构、损失函数、更新策略(SGD、RProp、Nesterov)、最大迭代数量、批处理大小、本地迭代和种子数量。
// Define a layered architecture.
MLPArchitecture arch = new MLPArchitecture(2).
withAddedLayer(10, true, Activators.RELU).
withAddedLayer(1, false, Activators.SIGMOID);
// Define a neural network trainer.
MLPTrainer<SimpleGDParameterUpdate> trainer = new MLPTrainer<>(
arch,
LossFunctions.MSE,
new UpdatesStrategy<>(
new SimpleGDUpdateCalculator(0.1),
SimpleGDParameterUpdate::sumLocal,
SimpleGDParameterUpdate::avg
),
3000, // Max iterations.
4, // Batch size.
50, // Local iterations.
123L // Random seed.
);
// Train model.
MultilayerPerceptron mlp = trainer.fit(ignite, dataCache, vectorizer);
# 5.3.4.示例
要了解多层感知在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
# 5.4.逻辑回归
# 5.4.1.概述
二元逻辑回归是一种特殊类型的回归,其中二元响应变量与一组解释变量相关,这些解释变量可以是离散的和/或连续的。这里要注意的重要一点是,在线性回归中,响应变量的预期值是基于预测器所取值的组合来建模的。在逻辑回归中,基于由预测器获得的值的组合,对采取特定值的响应的概率或几率进行建模。在Ignite的ML模块中,它通过LogisticRegressionModel实现,解决了二元分类问题。它是在由逻辑损失给出的公式中具有损失函数的线性方法:
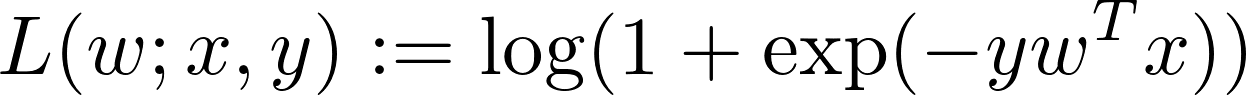
对于二元分类问题,该算法输出二元逻辑回归模型。给定一个新的数据点,用x表示,模型通过应用逻辑函数进行预测:
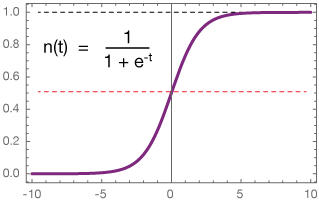
默认情况下,如果f(wTx)>0.5或mathrm{f}(wv^T x) > 0.5(Tex公式),则结果为正,否则为负。不过与线性SVM不同,逻辑回归模型f(z)的原始输出具有概率解释(即,其为正的概率)。
# 5.4.2.模型
该模型由LogisticRegressionModel类表示,并保留权重向量。它可以通过给定的特征向量进行预测,方式如下:
LogisticRegressionModel mdl = …;
double prediction = mdl.predict(observation);
Ignite的LogisticRegressionModel支持若干个参数:
isKeepingRawLabels:控制输出标签格式:0和1表示错误值,否则为分离超平面的原始距离(默认值:false);threshold:阈值,如果原始值大于该阈值,则向观察分配标签1(默认值:0.5)。
LogisticRegressionModel mdl = …;
double prediction = mdl.withRawLabels(true).withThreshold(0.5).predict(observation);
# 5.4.3.训练器
二元逻辑回归模型的训练器会在后台构建MLP 1级训练器。
Ignite的LogisticRegressionSGDTrainer支持下面的参数:
updatesStgy:更新策略;maxIterations:收敛前的最大迭代量;batchSize:批次学习大小;locIterations:SGD算法的局部迭代量;seed:用于内部随机目的以再现训练结果的种子值。
LogisticRegressionSGDTrainer trainer = new LogisticRegressionSGDTrainer()
.withUpdatesStgy(UPDATES_STRATEGY)
.withAmountOfIterations(MAX_ITERATIONS)
.withAmountOfLocIterations(BATCH_SIZE)
.withBatchSize(LOC_ITERATIONS)
.withSeed(SEED);
// Build the model
LogisticRegressionModel mdl = trainer.fit(ignite, dataCache, vectorizer);
# 5.4.4.示例
要了解LogisticRegressionModel在实践中是如何使用的,可以尝试这个示例。
# 5.5.k-NN分类
对于广泛使用的k-NN(k-最近邻)算法,Ignite支持它的两个版本,一个是分类任务,另一个是回归任务。
本章节会描述k-NN作为分类任务的解决方案。
# 5.5.1.训练器&模型
K-NN算法是一种非参数方法,其输入由特征空间中的K-最近训练样本组成。
另外,k-NN分类的输出表示为类的成员。一个对象按其邻居的多数票进行分类。该对象会被分配为K近邻中最常见的某个类。k是正整数,通常很小,当k为1时是一个特殊的情况,该对象会简单地分配给该单近邻的类。
目前,Ignite为k-NN分类算法提供了若干参数:
k:最近邻数量;distanceMeasure:ML框架提供的距离度量之一,例如欧几里得、海明或曼哈顿;isWeighted:默认为false,如果为true,则启用加权KNN算法;dataCache:持有已知分类的对象的训练集;indexType:分布式空间索引,有3个可选值:ARRAY,KD_TREE,BALL_TREE。
// Create trainer
KNNClassificationTrainer trainer = new KNNClassificationTrainer();
// Create trainer
KNNClassificationTrainer trainer = new KNNClassificationTrainer()
.withK(3)
.withIdxType(SpatialIndexType.BALL_TREE)
.withDistanceMeasure(new EuclideanDistance())
.withWeighted(true);
// Train model.
KNNClassificationModel knnMdl = trainer.fit(
ignite,
dataCache,
vectorizer
);
// Make a prediction.
double prediction = knnMdl.predict(observation);
# 5.5.2.示例
要了解k-NN分类在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
训练数据集是可以从UCI机器学习库加载的鸢尾花数据集。
# 5.6.ANN(近似最近邻)
# 5.6.1.概述
近似最近邻搜索算法允许返回点,其距离查询最多为查询到最近点距离的C倍。
这种方法的吸引力在于,在许多情况下,近似最近邻几乎和精确的一样好。尤其是,如果距离度量准确地捕获了用户质量的概念,那么距离中的微小差异就不重要了。
ANN算法能够解决多类分类任务。Ignite的实现是一种启发式算法,它基于搜索较小的有限大小N个候选点(内部使用分布式K均值聚类算法查找质心),可以像KNN算法一样对类标签进行投票。
KNN与ANN的区别在于,在预测阶段,所有训练点都参与了KNN算法中K-最近邻的搜索,而在ANN中,该搜索仅从候选点的一小部分开始。
注意:如果N设置为训练集的大小,则在训练阶段花费大量时间后,ANN将减少到KNN。因此,选择N比K(例如10 x k、100 x k等)。
# 5.6.2.模型
ANN分类输出表示为一个类成员。一个对象是由它的邻居的多数票来分类的。对象被分配给某个类,该类在其K最近邻中最常见。K是一个正整数,通常很小。当K为1时,有一种特殊情况,对象被简单地分配给单个最近邻的类。
目前,对于ANN分类算法,Ignite支持以下参数:
k:最近邻数量;distanceMeasure:机器学习(ML)框架提供的距离度量之一,如欧几里得、汉明或曼哈顿;isWeighted:默认为false,如果为true,则启用加权KNN算法。
NNClassificationModel knnMdl = trainer.fit(
...
).withK(5)
.withDistanceMeasure(new EuclideanDistance())
.withWeighted(true);
// Make a prediction.
double prediction = knnMdl.predict(observation);
# 5.6.3.训练器
ANN模型的训练器使用K均值来计算候选子集的,这就是为什么它具有与K均值算法相同的参数来调整其超参数的原因。它不仅构建了一组候选对象,还构建了它们的类标签分布,以便在预测阶段为类标签投票。
目前,Ignite为ANNClassificationTrainer支持以下参数:
k:可能的簇数量;maxIterations:一个停止标准(另一个是epsilon);epsilon:收敛增量(新旧质心值之间的增量);distance:ML框架提供的距离度量之一,如欧几里得、汉明或曼哈顿;seed:有助于复制模型的初始化参数之一(训练器有一个随机初始化步骤来获取第一个质心)。
// Set up the trainer
ANNClassificationTrainer trainer = new ANNClassificationTrainer()
.withDistance(new ManhattanDistance())
.withK(50)
.withMaxIterations(1000)
.withSeed(1234L)
.withEpsilon(1e-2);
// Build the model
NNClassificationModel knnMdl = trainer.fit(
ignite,
dataCache,
vectorizer
).withK(5)
.withDistanceMeasure(new EuclideanDistance())
.withWeighted(true);
# 5.6.4.示例
要了解ANNClassificationModel在实践中是如何使用的,可以尝试GitHub上的这个示例,它也会随着每个Ignite版本一起发布。训练数据集是鸢尾花数据集,可以从UCI机器学习库获取。
# 5.7.朴素贝叶斯
# 5.7.1.概述
朴素贝叶斯分类是一系列简单的概率分类器,基于贝叶斯定理并在特征之间具有强烈的(朴素)独立性假设。
在所有训练器中,可以预先设置或计算先验概率。同样,也可以选择使用等概率。
# 5.7.2.高斯朴素贝叶斯
高斯朴素贝叶斯算法的介绍在这里。
处理连续数据时,典型的假设是与每个类别关联的连续值是符合正态(或高斯)分布的。
模型预测结果值y属于[0..K]中的类C_k,k,即:
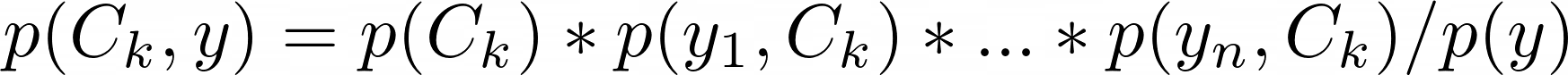 这里:
这里:
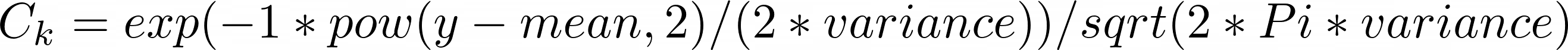 该模型返回最可能分类的编号(索引)。
该模型返回最可能分类的编号(索引)。
训练器为每个分类计算均值和方差。
GaussianNaiveBayesTrainer trainer = new GaussianNaiveBayesTrainer();
GaussianNaiveBayesModel mdl = trainer.fit(ignite, dataCache, vectorizer);
完整的示例代码在这里。
# 5.7.3.离散(伯努利)朴素贝叶斯
基于伯努利或多项式分布的朴素贝叶斯算法的介绍在这里。
可用于非连续特征。将特征转换为离散值的阈值应在训练器中配置(类似于直方图方法)。如果特征是二元的,则离散贝叶斯将成为伯努利贝叶斯。
模型预测结果值y属于[0..K]中的类C_k,k,即:
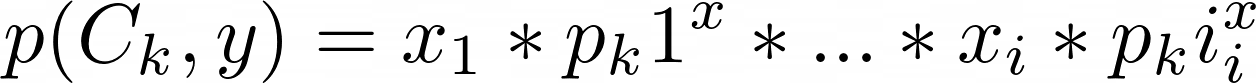 其中
其中x_i是离散特征,p_ki是分类p(C_k)的先验概率。
该模型返回最可能分类的编号(索引)。
double[][] thresholds = new double[][] {{.5}, {.5}, {.5}, {.5}, {.5}};
DiscreteNaiveBayesTrainer trainer = new DiscreteNaiveBayesTrainer()
.setBucketThresholds(thresholds);
DiscreteNaiveBayesModel mdl = trainer.fit(ignite, dataCache, vectorizer);
完整的示例代码在这里。
# 5.7.4.复合朴素贝叶斯
复合朴素贝叶斯是几个朴素贝叶斯分类的组合,其中每个分类代表一种类型的特征的子集。
该模型同时包含高斯和离散贝叶斯,开发者可以选择在每个模型上训练哪些特征集。
该模型返回最可能分类的编号(索引)。
double[] priorProbabilities = new double[] {.5, .5};
double[][] thresholds = new double[][] {{.5}, {.5}, {.5}, {.5}, {.5}};
CompoundNaiveBayesTrainer trainer = new CompoundNaiveBayesTrainer()
.withPriorProbabilities(priorProbabilities)
.withGaussianNaiveBayesTrainer(new GaussianNaiveBayesTrainer())
.withGaussianFeatureIdsToSkip(asList(3, 4, 5, 6, 7))
.withDiscreteNaiveBayesTrainer(new DiscreteNaiveBayesTrainer()
.setBucketThresholds(thresholds))
.withDiscreteFeatureIdsToSkip(asList(0, 1, 2));
CompoundNaiveBayesModel mdl = trainer.fit(ignite, dataCache, vectorizer);
完整的示例在这里。
# 6.回归
回归是一种可以进行训练以预测实际实数输出的机器学习算法,例如温度、股价等。回归基于一个假设,可以是线性、平方、多项式、非线性等,假设是一个函数,是基于一些隐藏参数和输入值。
本节介绍的所有训练算法都是为解决回归任务而设计的。
# 6.1.线性回归
# 6.1.1.概述
Ignite支持普通最小二乘线性回归算法,这是最基本也是最强大的机器学习算法之一,本章节会说明该算法的工作方式以及Ignite是如何实现的。
线性回归算法的基本原理是,假定因变量y和自变量x有如下的关系:
 注意,后续的文档中会使用向量x和b的点积,并且明确地避免使用常数项,当向量x由一个等于1的值补充时,在数学上是正确的。
注意,后续的文档中会使用向量x和b的点积,并且明确地避免使用常数项,当向量x由一个等于1的值补充时,在数学上是正确的。
如果向量b已知,上面的假设可以基于特征向量x进行预测,它反映在Ignite中负责预测的LinearRegressionModel类中。
# 6.1.2.模型
线性回归的模型表示为LinearRegressionModel类,它能够对给定的特征向量进行预测,如下:
LinearRegressionModel model = ...;
double prediction = model.predict(observation);
模型是完全独立的对象,训练之后可以被保存、序列化以及恢复。
# 6.1.3.训练器
线性回归是一种监督学习算法,这意味着为了找到参数(向量b),需要在训练数据集上进行训练,并且使损失函数最小化。
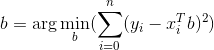
Ignite支持两种线性回归训练器,基于LSQR算法的训练器以及另一个基于随机梯度下降法的训练器。
LSQR训练器
LSQR算法是为线性方程组找到大的、稀疏的最小二乘解,Ignite实现了这个算法的分布式版本。
// Create linear regression trainer.
LinearRegressionLSQRTrainer trainer = new LinearRegressionLSQRTrainer();
// Train model.
LinearRegressionModel mdl = trainer.fit(ignite, dataCache, vectorizer);
// Make a prediction.
double prediction = mdl.apply(coordinates);
SGD训练器
另一个线性回归训练器会使用随机梯度下降法来寻找损失函数的最小值。该训练器的配置类似于多层感知训练器的配置,可以指定更新类型(Nesterov的SGD,RProp)、最大迭代次数、批量大小、局部迭代次数和种子。
// Create linear regression trainer.
LinearRegressionSGDTrainer<?> trainer = new LinearRegressionSGDTrainer<>(
new UpdatesStrategy<>(
new RPropUpdateCalculator(),
RPropParameterUpdate::sumLocal,
RPropParameterUpdate::avg
),
100000, // Max iterations.
10, // Batch size.
100, // Local iterations.
123L // Random seed.
);
// Train model.
LinearRegressionModel mdl = trainer.fit(ignite, dataCache, vectorizer);
// Make a prediction.
double prediction = mdl.apply(coordinates);
# 6.1.4.示例
要了解线性回归在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
# 6.2.决策树回归
决策树及其集成是用于分类和回归的机器学习任务的流行方法。决策树由于其易于解释、处理分类特征,扩展到多类分类设置,不需要特征缩放,并且能够捕获非线性和特征交互等优点而被广泛使用。随机森林和提升等树集成算法是分类和回归任务中表现最好的算法之一。
# 6.2.1.概述
在有监督的机器学习中,决策树是一个简单而强大的模型。主要思想是将特征空间划分为多个区域,以使每个区域中的值略有变化,区域中值变化的度量称为区域的纯度。
Ignite对于行数据存储,提供了一种优化算法,具体可以看分区化的数据集。
拆分是递归完成的,从拆分创建的每个区域都可以进一步拆分。因此,整个过程可以用二叉树来描述,其中每个节点是一个特定区域,其子节点是通过另一个拆分从其派生的区域。
令训练集中的每个样本都属于某个空间S,并使p_i成为索引值为i的特征的的投影,然后按索引值为i的连续特征进行拆分,形式为:
具有来自某些集合X的值的按类别划分的特征,具有以下形式:
这里X_0是X的子集。
该模型的工作方式:当算法达到配置的最大深度,或者任何区域的拆分都没有导致明显的纯度损失时,拆分过程就会停止。对从S到点s的值的预测是将树向下遍历,直到节点对应的区域包含s,并返回与此叶子相关联的值。
# 6.2.2.模型
决策树分类中的模型由类DecisionTreeModel表示,可以通过以下方式对给定的特征向量进行预测:
DecisionTreeModel mdl = ...;
double prediction = mdl.apply(observation);
模型是完全独立的对象,经过训练后可以保存,序列化和还原。
# 6.2.3.训练器
根据纯度度量和节点实例化方法,决策树算法可用于分类和回归。
回归决策树使用MSE纯度度量,使用方式如下:
// Create decision tree classification trainer.
DecisionTreeRegressionTrainer trainer = new DecisionTreeRegressionTrainer(
4, // Max deep.
0 // Min impurity decrease.
);
// Train model.
DecisionTreeModel mdl = trainer.fit(ignite, dataCache, vectorizer);
# 6.2.4.示例
要了解决策树在实践中是如何使用的,可以看这个回归示例,这些示例也会随着每个Ignite版本进行发布。
# 6.3.k-NN回归
对于广泛使用的k-NN(k-最近邻)算法,Ignite支持它的两个版本,一个是分类任务,另一个是回归任务。
本章节会描述k-NN作为回归任务的解决方案。
# 6.3.1.训练器&模型
K-NN算法是一种非参数方法,其输入由特征空间中的K-最近训练样本组成。每个训练样本具有与给定的训练样本相关联的数值形式的属性值。
K-NN算法使用所有训练集来预测给定测试样本的属性值,这个预测的属性值是其k最近邻值的平均值。如果k是1,那么测试样本会被简单地分配给单个最近邻的属性值。
目前,Ignite为k-NN回归算法支持若干参数:
k:最近邻数量;distanceMeasure:ML框架提供的距离度量之一,例如欧几里得、海明或曼哈顿;isWeighted:默认为false,如果为true,则启用加权KNN算法;dataCache:持有已知分类的对象的训练集;indexType:分布式空间索引,有三个可选值:ARRAY、KD_TREE、BALL_TREE。
// Create trainer
KNNRegressionTrainer trainer = new KNNRegressionTrainer()
.withK(5)
.withIdxType(SpatialIndexType.BALL_TREE)
.withDistanceMeasure(new ManhattanDistance())
.withWeighted(true);
// Train model.
KNNClassificationModel knnMdl = trainer.fit(
ignite,
dataCache,
vectorizer
);
// Make a prediction.
double prediction = knnMdl.predict(observation);
# 6.3.2.示例
要了解k-NN回归在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
训练数据集是可以从UCI机器学习库加载的鸢尾花数据集。
# 7.聚类
IgniteML模块提供了K-均值和GMM算法,可以将未标记的数据分组到簇中。
本节中介绍的所有训练算法均旨在解决无监督(聚类)任务。
提示
K-均值可以看作是高斯混合模型的特例,每个分量具有相同的协方差。
# 7.1.K-均值聚类
K-均值是最常用的聚类算法之一,它将数据点聚集成预定数量的聚类。
# 7.1.1.模型
K-均值聚类的目标是,将n个待观测值分为k个簇,这里每个观测值和所属的簇都有最近的均值,这被称为簇的原型。
该模型持有一个k中心向量以及距离指标,这些由比如欧几里得、海明或曼哈顿这样的机器学习框架提供。
它通过以下方式定义标签:
KMeansModel mdl = trainer.fit(
ignite,
dataCache,
vectorizer
);
double clusterLabel = mdl.predict(inputVector);
# 7.1.2.训练器
K-均值是一种无监督学习算法,它解决了将对象分组的聚类问题,即在同一个组(叫做簇)中的对象(某种意义上)比其它簇中的对象更相似。
K均值是一种参数化的迭代算法,在每个迭代中,计算每个簇中的新的均值,作为观测值的质心。
目前,Ignite为K均值分类算法支持若干个参数:
k:可能的簇的数量;maxIterations:一个停止条件(另一个是epsilon);epsilon:收敛增量(新旧质心值之间的增量);distance:机器学习框架提供的距离指标之一,例如欧几里得、海明或曼哈顿;seed:有助于重现模型的初始化参数之一(训练器具有随机的初始化步骤来获取第一个质心)。
// Set up the trainer
KMeansTrainer trainer = new KMeansTrainer()
.withDistance(new EuclideanDistance())
.withK(AMOUNT_OF_CLUSTERS)
.withMaxIterations(MAX_ITERATIONS)
.withEpsilon(PRECISION);
// Build the model
KMeansModel mdl = trainer.fit(
ignite,
dataCache,
vectorizer
);
# 7.1.3.示例
要了解K-均值聚类在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
训练数据集是鸢尾花数据集的一个子集(具有标签1和标签2,它们是线性可分离的两类数据集),可以从UCL机器学习库加载。
# 7.2.高斯混合(GMM)
高斯混合模型是一种概率模型,它假定所有数据点都是从有限数量的、符合高斯分布的混合参数中生成的。
注意
可以将混合模型视为对k-均值聚类进行泛化,以合并有关数据协方差结构以及潜在高斯中心的信息。
# 7.2.1.模型
该算法表示一个软聚类模型,其中每个聚类都具有自己的平均值和协方差矩阵的高斯分布。这样的模型可以使用最大似然原理预测聚类。
它通过以下方式定义标签:
KMeansModel mdl = trainer.fit(
ignite,
dataCache,
vectorizer
);
double clusterLabel = mdl.predict(inputVector);
# 7.2.2.训练器
GMM是一种无监督的学习算法。GaussianMixture对象实现了期望最大化(EM)算法,以拟合高斯混合模型。它可以计算贝叶斯信息准则以评估数据中的簇数。
目前,Ignite为GMM分类算法支持如下的参数:
maxCountOfClusters:可能的簇数;maxCountOfIterations:一个停止条件(另一个是epsilon);epsilon:收敛增量(新旧质心值之间的增量);countOfComponents:组件数量;maxLikelihoodDivergence:数据集中向量的最大似然与其他异常识别之间的最大差异;minElementsForNewCluster:根据maxLikelihoodDivergence创建新簇所需的最小异常;minClusterProbability:最小聚类概率。
// Set up the trainer
GmmTrainer trainer = new GmmTrainer(COUNT_OF_COMPONENTS);
// Build the model
GmmModel mdl = trainer
.withMaxCountIterations(MAX_COUNT_ITERATIONS)
.withMaxCountOfClusters(MAX_AMOUNT_OF_CLUSTERS)
.fit(ignite, dataCache, vectorizer);
# 7.2.3.示例
要了解GMM在实践中是如何使用的,可以看这个示例,该示例也会随着每个Ignite版本进行发布。
# 8.模型选择
# 8.1.模型选择
本节介绍如何调整机器学习算法和管道,内置的交叉验证和其他工具可以优化算法和管道中的超参数。
模型选择是一组工具,可以高效地准备和评估模型,可以根据训练和测试数据拆分数据,并执行交叉验证。
# 8.1.1.概述
学习预测函数的参数并在相同数据上对其进行验证不是一个好的实践,这会导致过度拟合。为避免此问题,最有效的解决方案之一是将部分训练数据保存为验证集。不过通过对可用数据进行分区并从训练集中排除一个或多个部分,可以大大减少用于学习模型的样本数量,并且结果可以依赖于(训练,验证)集对的特定随机选择。
解决此问题的一个方法是称为交叉验证的过程。在称为k-fold CV的基本方法中,将训练集拆分为k个较小的集,然后执行以下过程:使用k-1个折叠(部分)作为训练数据训练模型,结果模型在数据的其余部分进行验证(用作测试集以计算准确性等指标)。
Ignite提供了交叉验证功能,该功能允许其参数化要验证的训练器,在每个步骤中训练的模型要计算的指标以及训练数据的折叠次数。
# 8.2.评估器
IgniteML附带了许多机器学习算法,可用于从数据中学习并进行数据预测。将这些算法用于构建机器学习模型时,需要根据某些标准评估模型的性能,具体取决于应用及其要求。IgniteML还提供了一套分类和回归指标,用于评估机器学习模型的性能。
# 8.2.1.分类模型评估
尽管分类算法有许多不同的类型,但是分类模型的评估都具有相似的原理。在监督分类问题中,每个数据点都存在真实输出和模型生成的预测输出。因此可以将每个数据点的结果分配给以下四个类别之一:
真阳性(TP):标签为阳性,预测也为阳性真阴性(TN):标签为阴性,预测也为阴性;假阳性(FP):标签为阴性,但预测为阳性;假阴性(FN):标签为阳性,但预测为阴性。
尤其是,这些指标对于二元分类很重要。
多类分类
IgniteML尚不支持多类分类评估。
接下来是IgniteML支持的二元分类指标的完整列表:
- Accuracy
- Balanced accuracy
- F-Measure
- FallOut
- FN
- FP
- FDR
- MissRate
- NPV
- Precision
- Recall
- Specificity
- TN
- TP
这些指标的说明和公式可以在此处找到。
// Define the vectorizer.
Vectorizer<Integer, Vector, Integer, Double> vectorizer = new DummyVectorizer<Integer>()
.labeled(Vectorizer.LabelCoordinate.FIRST);
// Define the trainer.
SVMLinearClassificationTrainer trainer = new SVMLinearClassificationTrainer();
// Train the model.
SVMLinearClassificationModel mdl = trainer.fit(ignite, dataCache, vectorizer);
// Calculate all classification metrics.
EvaluationResult res = Evaluator
.evaluateBinaryClassification(dataCache, mdl, vectorizer);
double accuracy = res.get(MetricName.ACCURACY)
# 8.2.2.回归模型评估
从多个自变量预测连续输出变量时,将使用回归分析。
IgniteML支持的回归指标的完整列表如下:
- MAE
- R2
- RMSE
- RSS
- MSE
// Define the vectorizer.
Vectorizer<Integer, Vector, Integer, Double> vectorizer = new DummyVectorizer<Integer>()
.labeled(Vectorizer.LabelCoordinate.FIRST);
// Define the trainer.
KNNRegressionTrainer trainer = new KNNRegressionTrainer()
.withK(5)
.withDistanceMeasure(new ManhattanDistance())
.withIdxType(SpatialIndexType.BALL_TREE)
.withWeighted(true);
// Train the model.
KNNRegressionModel knnMdl = trainer.fit(ignite, dataCache, vectorizer);
// Calculate all classification metrics.
EvaluationResult res = Evaluator
.evaluateRegression(dataCache, mdl, vectorizer);
double mse = res.get(MetricName.MSE)
# 8.3.在测试和训练数据集上拆分数据集
数据拆分旨在将存储在缓存中的数据拆分为两个部分:用于训练模型的训练部分和用于估计模型质量的测试部分。
所有的fit()方法都有一个特殊的参数,用于将过滤条件传递给每个缓存。
深度解读
由于数据集操作的分布式和惰性性质,数据集拆分也是惰性操作,可以定义为可应用于初始缓存以形成训练和测试数据集的过滤条件。
在下面的示例中,仅在初始数据集的75%上训练模型。过滤器参数值是split.getTrainFilter()的结果,可以继续或拒绝初始数据集中的行以在训练期间进行处理。
// Define the cache.
IgniteCache<Integer, Vector> dataCache = ...;
// Define the percentage of the train sub-set of the initial dataset.
TrainTestSplit<Integer, Vector> split = new TrainTestDatasetSplitter<>().split(0.75);
IgniteModel<Vector, Double> mdl = trainer
.fit(ignite, dataCache, split.getTrainFilter(), vectorizer);
该split.getTestFilter()可用于验证测试数据模型。
下面是直接使用缓存的示例:从初始数据集的测试子集中打印预测值和实际回归值:
// Define the cache query and set the filter.
ScanQuery<Integer, Vector> qry = new ScanQuery<>();
qry.setFilter(split.getTestFilter());
try (QueryCursor<Cache.Entry<Integer, Vector>> observations = dataCache.query(qry)) {
for (Cache.Entry<Integer, Vector> observation : observations) {
Vector val = observation.getValue();
Vector inputs = val.copyOfRange(1, val.size());
double groundTruth = val.get(0);
double prediction = mdl.predict(inputs);
System.out.printf(">>> | %.4f\t\t| %.4f\t\t|\n", prediction, groundTruth);
}
}
# 8.4.交叉验证
Ignite中的交叉验证功能由CrossValidation表示。这是一个由模型类型、标签类型和数据的键值类型参数化的计算器。实例化后(构造函数不接受任何其他参数),就可以使用score方法执行交叉验证。
假定有一个训练器,一个训练集,并且希望使用准确度作为度量标准并使用4个折叠进行交叉验证。Ignite中的做法如下所示:
# 8.4.1.交叉验证(不使用管道API)
// Create classification trainer
DecisionTreeClassificationTrainer trainer = new DecisionTreeClassificationTrainer(4, 0);
// Create cross-validation instance
CrossValidation<DecisionTreeModel, Integer, Vector> scoreCalculator
= new CrossValidation<>();
// Set up the cross-validation process
scoreCalculator
.withIgnite(ignite)
.withUpstreamCache(trainingSet)
.withTrainer(trainer)
.withMetric(MetricName.ACCURACY)
.withPreprocessor(vectorizer)
.withAmountOfFolds(4)
.isRunningOnPipeline(false)
// Calculate accuracy for each fold
double[] accuracyScores = scoreCalculator.scoreByFolds();
在此示例中,将训练器和指标指定为参数,之后传递常规训练参数,例如Ignite实例、缓存、矢量化器的引用,最后指定折叠次数。此方法返回一个数组,其中包含针对训练集的所有可能拆分的选定指标。
# 8.4.2.交叉验证(使用管道API)
定义管道并将其作为参数传递给交叉验证实例,以在管道运行交叉验证。
实验性API
Pipeline API是试验性的,在以后的版本中可能会更改。
// Create classification trainer
DecisionTreeClassificationTrainer trainer = new DecisionTreeClassificationTrainer(4, 0);
Pipeline<Integer, Vector, Integer, Double> pipeline
= new Pipeline<Integer, Vector, Integer, Double>()
.addVectorizer(vectorizer)
.addPreprocessingTrainer(new ImputerTrainer<Integer, Vector>())
.addPreprocessingTrainer(new MinMaxScalerTrainer<Integer, Vector>())
.addTrainer(trainer);
// Create cross-validation instance
CrossValidation<DecisionTreeModel, Integer, Vector> scoreCalculator
= new CrossValidation<>();
// Set up the cross-validation process
scoreCalculator
.withIgnite(ignite)
.withUpstreamCache(trainingSet)
.withPipeline(pipeline)
.withMetric(MetricName.ACCURACY)
.withPreprocessor(vectorizer)
.withAmountOfFolds(4)
.isRunningOnPipeline(false)
// Calculate accuracy for each fold
double[] accuracyScores = scoreCalculator.scoreByFolds();
# 8.4.3.示例
如果要了解交叉验证在实践中如何使用,可以尝试这个示例,以及机器学习教程的第8个步骤,该示例也会随着每个Ignite版本进行发布。
# 8.5.超参数调整
在机器学习中,超参数优化或调整是为学习算法选择一组最佳超参数的问题。超参数是一个参数,其值用于控制学习过程。而其他参数的值(通常是节点权重)是被学习的。
在IgniteML中,可以通过更改超参数(预处理器和训练器的超参数)来调整模型。
保留超参数的所有可能值的主要对象是ParamGrid对象。
DecisionTreeClassificationTrainer trainerCV = new DecisionTreeClassificationTrainer();
ParamGrid paramGrid = new ParamGrid()
.addHyperParam("maxDeep", trainerCV::withMaxDeep,
new Double[] {1.0, 2.0, 3.0, 4.0, 5.0, 10.0})
.addHyperParam("minImpurityDecrease", trainerCV::withMinImpurityDecrease,
new Double[] {0.0, 0.25, 0.5});
有几种方法可以找到最佳的超参数集:
暴力破解(网格搜索):执行超参数优化的传统方法是网格搜索或参数扫描,它只是对学习算法的超参数空间的手动指定子集的详尽搜索;随机搜索:通过随机选择所有组合来替换穷举枚举;进化优化:进化优化是一种噪声黑箱函数全局优化的方法。在超参数优化中,进化优化使用进化算法来搜索给定算法的超参数空间。
随机搜索ParamGrid可以设置如下:
ParamGrid paramGrid = new ParamGrid()
.withParameterSearchStrategy(
new RandomStrategy()
.withMaxTries(10)
.withSeed(12L))
.addHyperParam("p", normalizationTrainer::withP,
new Double[] {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0})
.addHyperParam("maxDeep", trainerCV::withMaxDeep,
new Double[] {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0})
.addHyperParam("minImpurityDecrease", trainerCV::withMinImpurityDecrease,
new Double[] {0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 1.0});
性能提示
网格搜索(暴力破解)和进化优化方法可以很容易地并行化,因为所有训练的运行都是相互独立的。
# 8.6.管道API
IgniteML标准化了用于机器学习算法的API,从而使将多种算法组合到单个管道或工作流中变得更加容易。本节介绍了PipelinesAPI引入的关键概念,其中管道概念主要受scikit-learn和Apache Spark项目的启发。
预处理器模型:这是一种可以将一个数据集转换为另一个数据集的算法;预处理器训练器:这是一种算法,可以在一个数据集上产生预处理器模型;管道:管道将多个训练器和预处理器链接在一起,以指定机器学习工作流程;参数:所有机器学习训练器和预处理器训练器现在共享用于指定参数的通用API。
实验性API
Pipeline API是试验性的,在以后的版本中可能会更改。
管道可以使用.fit()方法调用替换代码段,如以下示例所示:
不使用管道API的用法:
final Vectorizer<Integer, Vector, Integer, Double> vectorizer = new DummyVectorizer<Integer>(0, 3, 4, 5, 6, 8, 10).labeled(1);
TrainTestSplit<Integer, Vector> split = new TrainTestDatasetSplitter<Integer, Vector>()
.split(0.75);
Preprocessor<Integer, Vector> imputingPreprocessor = new ImputerTrainer<Integer, Vector>()
.fit(ignite,
dataCache,
vectorizer
);
Preprocessor<Integer, Vector> minMaxScalerPreprocessor = new MinMaxScalerTrainer<Integer, Vector>()
.fit(ignite,
dataCache,
imputingPreprocessor
);
Preprocessor<Integer, Vector> normalizationPreprocessor = new NormalizationTrainer<Integer, Vector>()
.withP(1)
.fit(ignite,
dataCache,
minMaxScalerPreprocessor
);
// Tune hyper-parameters with K-fold Cross-Validation on the split training set.
DecisionTreeClassificationTrainer trainerCV = new DecisionTreeClassificationTrainer();
CrossValidation<DecisionTreeModel, Integer, Vector> scoreCalculator = new CrossValidation<>();
ParamGrid paramGrid = new ParamGrid()
.addHyperParam("maxDeep", trainerCV::withMaxDeep, new Double[] {1.0, 2.0, 3.0, 4.0, 5.0, 10.0})
.addHyperParam("minImpurityDecrease", trainerCV::withMinImpurityDecrease, new Double[] {0.0, 0.25, 0.5});
scoreCalculator
.withIgnite(ignite)
.withUpstreamCache(dataCache)
.withTrainer(trainerCV)
.withMetric(MetricName.ACCURACY)
.withFilter(split.getTrainFilter())
.isRunningOnPipeline(false)
.withPreprocessor(normalizationPreprocessor)
.withAmountOfFolds(3)
.withParamGrid(paramGrid);
CrossValidationResult crossValidationRes = scoreCalculator.tuneHyperParameters();
使用管道API的用法:
final Vectorizer<Integer, Vector, Integer, Double> vectorizer = new DummyVectorizer<Integer>(0, 4, 5, 6, 8).labeled(1);
TrainTestSplit<Integer, Vector> split = new TrainTestDatasetSplitter<Integer, Vector>()
.split(0.75);
DecisionTreeClassificationTrainer trainerCV = new DecisionTreeClassificationTrainer();
Pipeline<Integer, Vector, Integer, Double> pipeline = new Pipeline<Integer, Vector, Integer, Double>()
.addVectorizer(vectorizer)
.addPreprocessingTrainer(new ImputerTrainer<Integer, Vector>())
.addPreprocessingTrainer(new MinMaxScalerTrainer<Integer, Vector>())
.addTrainer(trainer);
CrossValidation<DecisionTreeModel, Integer, Vector> scoreCalculator = new CrossValidation<>();
ParamGrid paramGrid = new ParamGrid()
.addHyperParam("maxDeep", trainer::withMaxDeep, new Double[] {1.0, 2.0, 3.0, 4.0, 5.0, 10.0})
.addHyperParam("minImpurityDecrease", trainer::withMinImpurityDecrease, new Double[] {0.0, 0.25, 0.5});
scoreCalculator
.withIgnite(ignite)
.withUpstreamCache(dataCache)
.withPipeline(pipeline)
.withMetric(MetricName.ACCURACY)
.withFilter(split.getTrainFilter())
.withAmountOfFolds(3)
.withParamGrid(paramGrid);
CrossValidationResult crossValidationRes = scoreCalculator.tuneHyperParameters();
完整的示例代码在这里。
# 9.多类别分类
在机器学习中,多类别或多项式分类是将实例分类为三个或更多类之一的问题。
当前,IgniteML支持最流行的多类别分类方法,即一对多法(One-vs-Rest)。
“一对多”策略涉及每个类别训练一个分类器,该类别的样本作为阳性样本,所有其他样本作为阴性样本。
在内部,它使用一个数据集,但每个训练的分类器具有不同的变更标签。如果有N个类别,则将训练N个分类器成为MultiClassModel。
MultiClassModel使用软边距技术来预测实际标签,这意味着MultiClassModel会返回更适合于预测矢量的类别标签。
# 9.1.示例
要了解如何在实践中使用由二元SVM分类器参数化的一对多训练器,可以尝试此示例,并且随每个Ignite版本一起发布。
预处理的Glass数据集来自UCI机器学习存储库。
共有3个带有标签的类:1(building_windows_float_processed),3(vehicle_windows_float_processed),7(headlamps)和特征名称:Na-Sodium,Mg-Magnesium,Al-Aluminum,Ba-Barium,Fe-Iron。
OneVsRestTrainer<SVMLinearClassificationModel> trainer
= new OneVsRestTrainer<>(new SVMLinearClassificationTrainer()
.withAmountOfIterations(20)
.withAmountOfLocIterations(50)
.withLambda(0.2)
.withSeed(1234L)
);
MultiClassModel<SVMLinearClassificationModel> mdl = trainer.fit(
ignite,
dataCache,
new DummyVectorizer<Integer>().labeled(0)
);
double prediction = mdl.predict(inputVector);
# 10.集成方法
在统计学和机器学习中,集成方法使用多种学习算法和仅使用任何单个学习算法相比,可以获得更好的预测性能。通常,ML集成仅由一组具体的有限备选模型组成。
集成方法是将几种机器学习技术组合到一个预测模型中的元算法,以减少方差(装袋),偏差(提升)或改善预测(堆叠)。
# 10.1.堆叠
堆叠(有时称为堆叠泛化)涉及训练一种学习算法,以结合其他几种学习算法的预测。
首先,使用可用数据训练所有其他算法,然后训练组合算法以使用其他算法的所有预测作为附加输入进行最终预测。如果使用任意组合器算法,则堆叠理论上可以表示任何一种广为人知的集成技术,尽管在实践中,像下面的示例一样,经常使用逻辑回归模型作为组合器:
DecisionTreeClassificationTrainer trainer = new DecisionTreeClassificationTrainer(5, 0);
DecisionTreeClassificationTrainer trainer1 = new DecisionTreeClassificationTrainer(3, 0);
DecisionTreeClassificationTrainer trainer2 = new DecisionTreeClassificationTrainer(4, 0);
LogisticRegressionSGDTrainer aggregator = new LogisticRegressionSGDTrainer()
.withUpdatesStgy(new UpdatesStrategy<>(new SimpleGDUpdateCalculator(0.2),
SimpleGDParameterUpdate.SUM_LOCAL,
SimpleGDParameterUpdate.AVG));
StackedModel<Vector, Vector, Double, LogisticRegressionModel> mdl = new StackedVectorDatasetTrainer<>(aggregator)
.addTrainerWithDoubleOutput(trainer)
.addTrainerWithDoubleOutput(trainer1)
.addTrainerWithDoubleOutput(trainer2)
.fit(ignite,
dataCache,
vectorizer
);
评估
评估器可以与StackedModel配合使用。
# 10.1.1.示例
完整的示例在这里。
# 10.2.装袋
装袋即自举汇聚法。其减少估值方差的一种方法是将多个估值平均在一起。例如,可以在数据的不同子集上训练M个不同的树(通过替换随机选择)并计算集合:
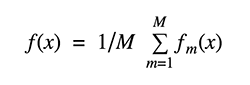 装袋使用自举抽样来获取数据子集,以训练基础学习者。为了汇总基础学习者的输出,装袋使用投票进行分类,使用平均值进行回归。
装袋使用自举抽样来获取数据子集,以训练基础学习者。为了汇总基础学习者的输出,装袋使用投票进行分类,使用平均值进行回归。
// Define the weak classifier.
DecisionTreeClassificationTrainer trainer = new DecisionTreeClassificationTrainer(5, 0);
// Set up the bagging process.
BaggedTrainer<Double> baggedTrainer = TrainerTransformers.makeBagged(
trainer, // Trainer for making bagged
10, // Size of ensemble
0.6, // Subsample ratio to whole dataset
4, // Feature vector dimensionality
3, // Feature subspace dimensionality
new OnMajorityPredictionsAggregator())
.withEnvironmentBuilder(LearningEnvironmentBuilder
.defaultBuilder()
.withRNGSeed(1)
);
// Train the Bagged Model.
BaggedModel mdl = baggedTrainer.fit(
ignite,
dataCache,
vectorizer
);
最流行的案例
常用的一类集成算法是随机森林。
# 10.2.1.示例
完整的示例在这里。
# 10.3.随机森林
# 10.3.1.概述
随机森林是解决任何分类和回归问题的集成学习方法。随机森林训练建立一种类型的模型组合(集成),并使用一些模型答案的聚合算法。每个模型在训练数据集的一部分上进行训练。该部分是根据装袋法和特征子空间法定义的。关于这些概念的更多信息可以在这里找到:随机子空间法、装袋法和随机森林。
在IgniteML中有几种聚合算法的实现:
MeanValuePredictionsAggregator:计算随机森林的回答作为给定组合中所有模型的预测的平均值。这通常用于回归任务;OnMajorityPredictionsAggegator:从给定组合中的所有模型中获取预测模式。这对于分类任务很有用。注意:这个聚合器支持多分类任务。
# 10.3.2.模型
在IgniteML中,随机森林算法是作为具有针对不同问题的特定聚合器的模型组合的一个特例存在的(MeanValuePredictionsAggregator针对回归,OnMajorityPredictionsAggegator针对分类)。
这里是模型使用的示例:
ModelsComposition randomForest = ….
double prediction = randomForest.apply(featuresVector);
# 10.3.3.训练器
随机森林训练算法通过RandomForestRegressionTrainer和RandomForestClassifierTrainer实现,参数如下:
meta:特征元数据,特征类型列表,比如:featureId:特征向量的索引;isCategoricalFeature:如果特征是分类的,则为true;- 特证名。
该元信息对于随机森林训练算法很重要,因为它建立特征直方图,并且分类特征应该在所有特征值的直方图中表示:
featuresCountSelectionStrgy:为学习一棵树设置定义随机特征计数的策略。有几种策略:在FeaturesCountSelectionStrategies类中实现:有SQRT、LOG2、ALL和ONE_THIRD策略;maxDepth:设置最大树深度;minInpurityDelta:如果两个节点上的impurity值小于未拆分节点的minImpurityDecrease值,则决策树中的节点被分成两个节点;subSampleSize:值位于[0;MAX_DOUBLE]区间中。此参数定义在具有替换的统一采样中采样重复的计数;seed:用于随机生成器的种子值。
随机森林训练使用方法如下:
RandomForestClassifierTrainer trainer = new RandomForestClassifierTrainer(featuresMeta)
.withCountOfTrees(101)
.withFeaturesCountSelectionStrgy(FeaturesCountSelectionStrategies.ONE_THIRD)
.withMaxDepth(4)
.withMinImpurityDelta(0.)
.withSubSampleSize(0.3)
.withSeed(0);
ModelsComposition rfModel = trainer.fit(
ignite,
dataCache,
vectorizer
);
# 10.3.4.示例
要了解如何在实践中使用随机森林分类器,可以尝试这个GitHub上的示例,它也会随着每个Ignite版本一起发布。在这个例子中,使用了一个葡萄酒识别数据集,该数据集和数据的描述可从UCI机器学习存储库获得。
# 10.4.梯度提升
在机器学习中,提升是一个主要用于减少偏差和监督学习方差的集成元算法,是一个将弱学习者转化为强学习者的机器学习算法家族。
卡恩斯和瓦兰特提出的问题(1988、1989)
“一组弱学习者可以创造一个单一的强学习者吗?”
弱学习者被定义为仅与真实分类稍微相关的分类器(与随机猜测相比,它可以更好地标记示例)。而强学习者是与真实分类任意相关的分类器。
后来,1990年,罗伯特·夏皮尔(Robert Schapire)证明了这一点,并推动了技术的发展。
在IgniteML库中是以梯度提升(最流行的提升实现)的形式提供提升功能的。
# 10.4.1.概述
梯度提升是一种产生弱预测模型集合形式预测模型的机器学习算法。梯度提升算法试图解决函数空间中每个函数都是模型的学习样本的最小化误差问题。这个组合中的每个模型都试图预测特征空间中点的误差梯度,并且这些预测将用一些权重求和以建模答案。该算法可用于回归和分类问题。更多信息可以参见维基百科。
在IgniteML中有一个通用GDB算法和GDB-on-tree算法的实现。通用GDB(GDBRegressionTrainer和GDBBinaryClassifierTrainer)允许任何训练器对每个模型进行组合训练。GDB-on-trees使用一些特定于树的优化,例如索引,以避免在决策树构建阶段进行排序。
# 10.4.2.模型
IgniteML的目的是使用GDB算法的所有实现来使用GDBModel,包装ModelsComposition来表示几个模型的组成。ModelsComposition实现了一个通用的模型接口,使用方式如下:
GDBModel model = ...;
double prediction = model.predict(observation);
GDBModel使用WeightedPredictionsAggregator作为模型应答还原器。此聚合器计算元模型的答案,因为result = bias + p1w1 + p2w2 + ...,其中:
pi:第i个模型的答案;wi:合成中模型的权重。GDB使用标签的平均值作为聚合器中的偏差参数。
# 10.4.3.训练器
GDB的训练分别由GDBRegressionTrainer、GDBBinaryClassificationTrainer和GDBRegressionOnTreesTrainer以及GDBBinaryClassificationOnTreesTrainer表示,分别用于通用GDB和GDB-on-trees,所有训练器都有以下参数:
gradStepSize:设置合成中每个模型的恒定权重;在IgniteML的未来版本中,该参数可以动态计算;cntOfIterations:在训练之后设置合成中的最大模型;checkConvergenceFactory:设置收敛检查器的工厂,用于在训练时防止过拟合和学习许多无用的模型。
对于分类器训练器,有附加参数:
loss:从训练数据集中在部分训练样本上配置损失计算器;
收敛检查器有若干个工厂:
ConvergenceCheckerStubFactory:创建一个始终返回false进行收敛检查的检查器。因此,在这种情况下,模型的组成大小将具有cntofiterations模型;MeanAbsValueConvergenceCheckerFactory:创建一个检查器,该检查器从数据集中计算每个样本的绝对梯度值的平均值,如果该平均值小于已定义的阈值,则返回true;MedianOfMedianConvergenceCheckerFactory:创建一个检查器,用于计算每个数据分区上的绝对梯度值的中间值。该方法对学习数据集的异常不敏感,但GDB收敛时间较长。
训练示例:
// Set up trainer
GDBTrainer trainer = new GDBBinaryClassifierOnTreesTrainer(
learningRate, countOfIterations, new LogLoss()
).withCheckConvergenceStgyFactory(new MedianOfMedianConvergenceCheckFactory(precision));
// Build the model
GDBModel mdl = trainer.fit(
ignite,
dataCache,
vectorizer
);
# 10.4.4.示例
要了解在实践中如何使用GDB分类器,可以尝试GitHub上的示例,它也会随着每个Ignite版本一起发布。
# 11.推荐系统
实验性API
这是一个实验性API,在以后的版本中可能会更改。
协同过滤通常用于推荐系统。这些技术旨在填充用户项关联矩阵的缺失条目。IgniteML当前支持基于模型的协同过滤,其中通过一小部分潜在因素来描述用户和产品,这些潜在因素可用于预测缺失的条目。
基于矩阵分解的协同过滤的标准方法是将用户项矩阵中的条目视为用户对项目(例如用户给电影评分)赋予的明确偏好。
基于MovieLens数据集的推荐系统示例。
IgniteCache<Integer, RatingPoint> movielensCache = loadMovieLensDataset(ignite, 10_000);
RecommendationTrainer trainer = new RecommendationTrainer()
.withMaxIterations(-1)
.withMinMdlImprovement(10)
.withBatchSize(10)
.withLearningRate(10)
.withLearningEnvironmentBuilder(envBuilder)
.withTrainerEnvironment(envBuilder.buildForTrainer());
RecommendationModel<Integer, Integer> mdl = trainer.fit(new CacheBasedDatasetBuilder<>(ignite, movielensCache));
评估器API兼容性
评估器尚不支持推荐系统。
下面的示例演示如何在给定的缓存在本地客户端节点上手动计算指标:
double mean = 0;
try (QueryCursor<Cache.Entry<Integer, RatingPoint>> cursor = movielensCache.query(new ScanQuery<>())) {
for (Cache.Entry<Integer, RatingPoint> e : cursor) {
ObjectSubjectRatingTriplet<Integer, Integer> triplet = e.getValue();
mean += triplet.getRating();
}
mean /= movielensCache.size();
}
double tss = 0, rss = 0;
try (QueryCursor<Cache.Entry<Integer, RatingPoint>> cursor = movielensCache.query(new ScanQuery<>())) {
for (Cache.Entry<Integer, RatingPoint> e : cursor) {
ObjectSubjectRatingTriplet<Integer, Integer> triplet = e.getValue();
tss += Math.pow(triplet.getRating() - mean, 2);
rss += Math.pow(triplet.getRating() - mdl.predict(triplet), 2);
}
}
double r2 = 1.0 - rss / tss;
# 12.导入模型
自2.8版本开始,Ignite支持从外部平台(包括Apache SparkML和XGBoost)导入机器学习模型,通过使用导入的模型,可以:
- 将导入的模型存储在Ignite中以进行进一步推断;
- 使用导入的模型作为管道的一部分;
- 对这些模型应用于诸如提升、装袋或堆叠之类的集成方法。
此外,可以在Ignite中更新导入的预训练模型。
Ignite为在Apache SparkML,XGBoost和H2O中训练的模型提供了用于分布式推理的API。
# 12.1.从XGBoost中导入模型
在Ignite中可以从XGBoost导入预训练的模型,这些模型将转换为IgniteML模型。IgniteML还提供了导入预训练的XGBoost模型以进行本地或分布式推理的功能。
将模型转换成IgniteML模型与执行分布式推理之间的区别在于解析器的实现。本示例说明如何从XGBoost导入模型并将其转换为IgniteML模型以进行分布式推理:
File mdlRsrc = IgniteUtils.resolveIgnitePath(TEST_MODEL_RES);
ModelReader reader = new FileSystemModelReader(mdlRsrc.getPath());
XGModelParser parser = new XGModelParser();
AsyncModelBuilder mdlBuilder = new IgniteDistributedModelBuilder(ignite, 4, 4);
Model<NamedVector, Future<Double>> mdl = mdlBuilder.build(reader, parser);
# 12.2.从SparkML中导入模型
# 12.2.1.通过Parquet文件从Apache Spark导入模型
从Ignite 2.8版本开始,可以导入以下Apache SparkML模型:
- 逻辑回归(
org.apache.spark.ml.classification.LogisticRegressionModel); - 线性回归(
org.apache.spark.ml.classification.LogisticRegressionModel); - 决策树(
org.apache.spark.ml.classification.DecisionTreeClassificationModel); - 支持向量机(
org.apache.spark.ml.classification.LinearSVCModel); - 随机森林(
org.apache.spark.ml.classification.RandomForestClassificationModel); - K均值(
org.apache.spark.ml.clustering.KMeansModel); - 决策树回归(
org.apache.spark.ml.regression.DecisionTreeRegressionModel); - 随机森林回归(
org.apache.spark.ml.regression.RandomForestRegressionModel); - 梯度提升树回归(
org.apache.spark.ml.regression.GBTRegressionModel); - 梯度提升树(
org.apache.spark.ml.classification.GBTClassificationModel)。
此功能适用于保存在snappy.parquet文件中的模型。
支持和经过测试的Spark版本:2.3.0。
可能适用于下面的Spark版本:2.1、2.2、2.3、2.4。
要从SparkML中获取模型,需要将在SparkML中训练后生成的模型保存到parquet文件中,如下例所示:
val spark: SparkSession = TitanicUtils.getSparkSession
val passengers = TitanicUtils.readPassengersWithCasting(spark)
.select("survived", "pclass", "sibsp", "parch", "sex", "embarked", "age")
// Step - 1: Make Vectors from dataframe's columns using special VectorAssmebler
val assembler = new VectorAssembler()
.setInputCols(Array("pclass", "sibsp", "parch", "survived"))
.setOutputCol("features")
// Step - 2: Transform dataframe to vectorized dataframe with dropping rows
val output = assembler.transform(
passengers.na.drop(Array("pclass", "sibsp", "parch", "survived", "age"))
).select("features", "age")
val lr = new LinearRegression()
.setMaxIter(100)
.setRegParam(0.1)
.setElasticNetParam(0.1)
.setLabelCol("age")
.setFeaturesCol("features")
// Fit the model
val model = lr.fit(output)
model.write.overwrite().save("/home/models/titanic/linreg")
要加载到IgniteML中,应通过SparkModelParser类,调用parse()方法:
DecisionTreeModel mdl = (DecisionTreeModel)SparkModelParser.parse(
SPARK_MDL_PATH,
SupportedSparkModels.DECISION_TREE
);
可以在org.apache.ignite.examples.ml.inference.spark.modelparser包的示例模块中查看使用此API的更多示例。
注意
不支持从Spark中的PipelineModel加载。
由于Ignite和Spark方面的预处理的不同性质,不支持Spark的中间特征转换器。
18624049226

← 代码部署 Ignite持续查询 →