# 性能和故障排除
# 1.常规性能提示
Ignite作为一个分布式存储和计算平台,是需要做出优化的,在深入更高级的优化技术之前,需要了解如下的基本要点:
- Ignite是为分布式计算场景设计和优化的,因此建议在多节点集群而不是单节点上部署和测试;
- Ignite可以水平扩展也可以垂直扩展,因此建议将本地主机上的所有可用CPU和RAM资源分配给Ignite节点,建议每台主机一个节点;
- 如果将Ignite部署在虚拟机或云环境中,则将Ignite节点固定到单个主机是理想的(但并非严格要求),这提供了两个好处:
- 避免了Ignite节点会与其他应用竞争主机资源的问题,这可能会导致Ignite节点上的性能波动;
- 确保高可用性。如果主机发生故障,并且该主机部署有两个或多个Ignite服务端节点,则可能导致数据丢失。
- 如果资源允许,请将整个数据集存储在内存中。即使Ignite可以存储并使用磁盘上的数据,它的架构还是内存优先的。换句话说,在内存中缓存的数据越多,性能就越快;
- 仅将数据放入内存还不能期望性能可以提高一个数量级,还需要调整数据模型和现有应用(如果有)。在数据建模阶段,应使用关联并置概念来进行正确的数据分发。如果数据正确地实现了并置,则可以运行大规模带有关联的SQL查询,并获得显著的性能表现;
- 如果使用了原生持久化,请参考下面的持久化调优技术;
- 如果要使用Ignite运行SQL,请参考下面的SQL调优技术;
- 调整数据再平衡设置,以确保在集群拓扑更改时再平衡可以更快地完成。
# 2.内存和JVM调优
本章节会介绍内存调优的最佳实践,这些最佳实践与环境中开启或不开启原生持久化或外部存储有关。虽然Ignite在Java堆外存储数据和索引,但是Java堆仍用于存储由查询和应用执行的操作生成的对象,因此对于JVM和垃圾回收(GC)相关的优化,还是应遵循下面的建议。
提示
与磁盘相关的优化实践,请参见持久化调优章节的介绍。
# 2.1.交换参数调优
当内存的使用达到阈值时,操作系统就会开始进行从内存到磁盘的页面交换,交换会显著影响Ignite节点进程的性能,这个问题可以通过调整操作系统参数来避免。如果使用的是Linux,最佳选项是或者降低vm.swappiness的值到10,或者如果开启了原生持久化,也可以将其配置为0。
sysctl –w vm.swappiness=0
此参数值也可以调整GC暂停时间。例如如果GC日志显示low user time, high system time, long GC pause这样的记录,这可能是由于Java堆页面被换入和换出所致。要解决此问题,也需要使用上面的swappiness设置。
# 2.2.操作系统和应用共享内存
操作系统、Ignite和其他应用之间会共享整个主机的内存。通常来说,如果以纯内存模式部署Ignite集群(禁用原生持久化),则不应为Ignite节点分配超过90%的内存量。
另一方面,如果使用了原生持久化,则操作系统需要额外的内存用于其页面缓存,以便以最佳方式将数据同步到磁盘。如果未禁用页面缓存,则不应将超过70%的内存分配给Ignite。
有关配置示例,请参见内存配置章节的介绍。
除此之外,由于使用原生持久化可能会导致较高的页面缓存利用率,因此kswapd守护进程可能无法跟上页面回收(页面缓存在后台使用)。因此由于直接页面回收,可能导致高延迟,并导致长GC暂停。
要解决Linux上页面内存回收造成的影响,需要使用/proc/sys/vm/extra_free_kbytes在wmark_min和wmark_low之间添加额外的字节:
sysctl -w vm.extra_free_kbytes=1240000
要更深入地了解页面缓存设置、高延迟和长时间GC暂停之间的关系,请参见这个资源。
# 2.3.Java堆和GC调优
虽然Ignite将数据保存在Java垃圾收集器看不到的堆外数据区中,但Java堆仍用于由应用生成的对象。例如每当执行SQL查询时,查询将访问堆外内存中存储的数据和索引,在应用读取结果集期间,此类查询的结果集会保留在Java堆中。因此根据吞吐量和操作类型,仍然可以大量使用Java堆,这也需要针对工作负载进行JVM和GC相关的调优。
下面提供了一些常规的建议和最佳实践,可以以下面的配置为基础,然后根据实际情况做进一步的调整。
提示
有关GC日志和堆转储收集的最佳实践,请参考GC调试章节的内容。
# 2.3.1.常规GC配置
下面是一些应用的JVM配置集示例,这些应用会在服务端节点上大量使用Java堆,从而触发长时间或频繁的短期GC暂停。
对于JDK 1.8+环境,应使用G1垃圾收集器,如果10GB的堆可以满足服务端节点的需要,则以下配置是个好的起点:
-server
-Xms10g
-Xmx10g
-XX:+AlwaysPreTouch
-XX:+UseG1GC
-XX:+ScavengeBeforeFullGC
-XX:+DisableExplicitGC
如果G1不适用,则可以考虑使用CMS收集器,并以下面的设置为起点。注意10GB的堆空间仅为示例,也许较小的堆空间即可满足业务需要:
-server
-Xms10g
-Xmx10g
-XX:+AlwaysPreTouch
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSClassUnloadingEnabled
-XX:+CMSPermGenSweepingEnabled
-XX:+ScavengeBeforeFullGC
-XX:+CMSScavengeBeforeRemark
-XX:+DisableExplicitGC
提示
如果使用了Ignite原生持久化,建议将MaxDirectMemorySizeJVM参数设置为walSegmentSize * 4,对于默认的WAL设置,该值等于256MB。
# 2.3.2.高级内存调优
在Linux和Unix环境中,由于I/O或内核特定参数配置导致的内存不足,应用可能面临长时间的GC暂停或性能下降。本章节会介绍有关如何修改内核参数配置以克服长时间GC暂停的一些准则。
警告
下面给出的所有shell命令均已在RedHat 7上进行了测试,其他的Linux发行版可能会有所不同。在更改内核参数配置之前,请检查系统统计信息/日志以确认确实有问题。在生产环境中对Linux内核进行修改之前,需要和运维部门确认。
如果GC日志显示,low user time, high system time, long GC pause则很可能是内存限制触发了交换或扫描可用内存空间:
- 检查并调整交换设置;
- 启动时添加
-XX:+AlwaysPreTouchJVM参数; - 禁用NUMA区域回收优化:
sysctl -w vm.zone_reclaim_mode=0 - 如果使用RedHat发行版,请关闭透明大页:
echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag
# 2.3.3.高级I/O调优
如果GC日志显示low user time, low system time, long GC pause,则GC线程可能在内核空间上花费了太多时间,被各种I/O活动所阻塞,这可能是由日志提交、gzip或日志轮转过程等引起的。
作为解决方案,可以尝试将页面刷新间隔从默认的30秒更改为5秒:
sysctl -w vm.dirty_writeback_centisecs=500
sysctl -w vm.dirty_expire_centisecs=500
提示
磁盘相关的优化,请参见持久化调优章节的介绍,这些优化可能会对GC产生积极影响。
# 3.持久化调优
本章节总结了和Ignite原生持久化有关的最佳实践,如果因为业务需要使用了外部(第三方)存储,则需要参见第三方厂商的优化方案。
# 3.1.调整页面大小
Ignite的页面大小(DataStorageConfiguration.pageSize)不要小于存储设备(SSD、HDD、闪存等)和操作系统缓存页面的大小的较小者,默认值是4KB。
操作系统的缓存页面大小很容易就可以通过系统工具和参数获取到。
存储设备比如SSD的页面大小可以在设备的说明上找到,如果厂商未提供这些信息,可以运行SSD的基准测试来算出这个数值,如果还是难以拿到这个数值,可以使用4KB作为Ignite的页面大小。很多厂商为了适应4KB的随机写工作负载不得不调整驱动,因为很多标准基准测试都是默认使用4KB,来自英特尔的白皮书也确认4KB足够了。
选定最优值之后,可以将其用于集群的配置:
# 3.2.WAL单独存储
考虑为Ignite原生持久化的数据文件以及预写日志(WAL)使用单独的磁盘设备,Ignite会主动地写入数据文件以及WAL文件。
下面的示例会显示如何为数据存储、WAL和WAL存档配置单独的路径:
# 3.3.增加WAL段大小
WAL段的默认大小(64MB)在高负载情况下可能是低效的,因为它导致WAL在段之间频繁切换,并且切换是有点昂贵的操作。将段大小设置为较大的值(最多2GB)有助于减少切换操作的次数,不过代价是这将增加预写日志的占用空间。
具体请参见修改WAL段大小章节的介绍。
# 3.4.调整WAL模式
考虑其它WAL模式替代默认模式。每种模式在节点故障时提供不同程度的可靠性,并且可靠性与速度成反比,即,WAL模式越可靠,则速度越慢。因此,如果具体业务不需要高可靠性,那么可以切换到可靠性较低的模式。
具体可以看WAL模式章节的介绍。
# 3.5.禁用WAL
有时禁用WAL有助于改善性能。
# 3.6.页面写入限流
Ignite会定期地启动检查点进程,以在内存和磁盘间同步脏页面。脏页是指页面已经在内存中更新,但是还未写入对应的分区文件(更新只是添加到了WAL)。这个进程在后台进行,对应用的逻辑没有影响。
但是,如果由检查点进程调度的一个脏页面,在写入磁盘前被更新,它之前的状态会被复制进某个区域,叫做检查点缓冲区。如果这个缓冲区溢出,那么在检查点处理过程中,Ignite会停止所有的更新。因此,在检查点周期完成之前写入性能可能降为0,如下图所示:
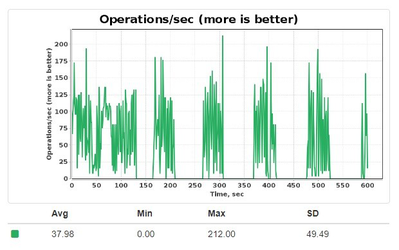
当检查点处理正在进行中时,如果脏页面数达到阈值,同样的情况也会发生,这会使Ignite强制安排一个新的检查点执行,并停止所有的更新操作直到第一个检查点周期执行完成。
当磁盘较慢或者更新过于频繁时,这两种情况都会发生,要减少或者防止这样的性能下降,可以考虑启用页面写入限流算法。这个算法会在检查点缓冲区填充过快或者脏页面占比过高时,将更新操作的性能降低到磁盘的速度。
页面写入限流剖析
要了解与限流及其触发原因的更多信息,可以看相关专家维护的Wiki页面。
下面的示例显示了如何开启页面写入限流:
# 3.7.调整检查点缓冲区大小
前述章节中描述的检查点缓冲区大小,是检查点处理的触发器之一。
缓冲区的默认大小是根据数据区大小计算的。
| 数据区大小 | 默认检查点缓冲区大小 |
|---|---|
< 1GB | MIN (256 MB, 数据区大小) |
1GB ~ 8GB | 数据区大小/4 |
> 8GB | 2GB |
默认的缓冲区大小并没有为写密集型应用进行优化,因为在大小接近标称值时,页面写入限流算法会降低写入的性能,因此在正在进行检查点处理时,可以考虑增加DataRegionConfiguration.checkpointPageBufferSize,并且开启写入限流来阻止性能的下降:
在上例中,默认内存区的检查点缓冲区大小配置为1GB。
# 3.8.启用直接IO
通常当应用访问磁盘上的数据时,操作系统拿到数据后会将其写入一个文件缓冲区缓存,写操作也是同样,操作系统首先将数据写入缓存,然后才会传输到磁盘,要消除这个过程,可以打开直接IO,这时数据会忽略文件缓冲区缓存,直接从磁盘进行读写。
Ignite中的直接I/O插件用于加速检查点进程,它的作用是将内存中的脏页面写入磁盘,建议将直接IO插件用于写密集型环境中。
提示
注意,无法专门为WAL文件开启直接I/O,但是开启直接I/O可以为WAL文件带来一点好处,就是WAL数据不会在操作系统的缓冲区缓存中存储过长时间,它会在下一次页面缓存扫描中被刷新(依赖于WAL模式),然后从页面缓存中删除。
要启用直接I/O插件,需要将二进制包的libs/optional/ignite-direct-io文件夹上移一层至libs/optional/ignite-direct-io文件夹,或者添加该插件的Maven依赖,具体见这里的介绍。
使用IGNITE_DIRECT_IO_ENABLED系统属性,可以在运行时启用/禁用该插件。
相关的Wiki页面有更多的细节。
# 3.9.购买产品级SSD
限于SSD的操作特性,在经历几个小时的高强度写入负载之后,Ignite原生持久化的性能可能会下降,因此需要考虑购买快速的产品级SSD来保证长时间高水平的性能,或者改为非易失性存储设备,比如Intel的傲腾持久化内存。
# 3.10.SSD预留空间
由于SSD预留空间的原因,50%使用率的磁盘的随机写性能要好于90%使用率的磁盘,因此需要考虑购买高预留空间比率的SSD,然后还要确保厂商能提供工具来进行相关的调整。
Intel 3D XPoint
考虑使用3D XPoint驱动器代替常规SSD,以避免由SSD级别上的低预留空间设置和恒定垃圾收集造成的瓶颈。具体可以看这里。
# 4.SQL调优
本章节概述了Ignite中SQL查询的常规和高级优化技术,其中一些内容对于调试和故障排除也很有用。
# 4.1.Ignite和RDBMS之间对比的基本要点
Ignite经常被与关系数据库的SQL功能进行比较,以期为RDBMS创建的已有SQL查询可以直接使用,并且在Ignite中无需任何更改就可以更快地执行。通常这种假设是基于Ignite在内存中存储和处理数据。但是仅将数据放入内存并期望性能提高一个数量级是不够的,因为需要额外的调整。下面是一个标准的最佳实践清单,在RDBMS和Ignite之间进行对比测试或进行任何性能测试之前,应考虑这些项目:
- Ignite针对使用内存作为主存储的多节点集群进行了优化。不要尝试将单节点Ignite与关系数据库进行比较,应该部署多节点集群,并将整个数据集放到内存中;
- 准备调整数据模型和现有的SQL查询。在数据建模阶段,应使用关联并置概念来进行正确的数据分布,注意仅将数据放入内存是不够的。如果数据放置在适当的位置,则可以运行大规模的SQL关联查询,并获得显著的性能提升;
- 定义二级索引,并使用下面描述的其他标准和Ignite特有的优化技术;
- 注意,关系型数据库通过本地缓存技术,并且根据总数据大小,即使在多节点配置中,RDBMS也可能比Ignite更快地完成某些查询。例如,如果数据集大约为10-100GB,并且RDBMS有足够的内存用于本地缓存数据,那么它的性能可能会优于多节点的Ignite集群,这时可以在Ignite中存储更多的数据以查看两者间的差异。
# 4.2.使用EXPLAIN语句
Ignite支持EXPLAIN语句,该语句可用于读取查询的执行计划。使用此命令可以分析查询以进行可能的优化。注意执行计划将包含多行:最后一行对应汇总阶段(通常是应用端)的查询,其他行是对应映射阶段(通常是服务端节点)的查询。要了解查询在Ignite中的执行方式,请参见分布式查询章节的介绍。
EXPLAIN SELECT name FROM Person WHERE age = 26;
关于H2中执行计划的生成,请参见这里的介绍。
# 4.3.OR操作符和选择性
如果查询使用了操作符OR,那么根据查询的复杂度可能不是以期望的方式使用索引。比如对于查询:select name from Person where gender='M' and (age = 20 or age = 30),会使用gender字段上的索引而不是age上的索引,虽然后者选择性更强。要解决这个问题需要用UNION ALL重写这个查询(注意没有ALL的UNION会返回去重的行,这会改变查询的语义而且引入了额外的性能开销),比如:
SELECT name FROM Person WHERE gender='M' and age = 20
UNION ALL
SELECT name FROM Person WHERE gender='M' and age = 30
# 4.4.避免过多的列
尽量避免在SELECT查询的结果集中有过多的列,因为H2查询解析器的限制,带有100列以上的查询,执行速度可能比预期要差。
# 4.5.延迟加载
Ignite默认会启用延迟加载,这会以适度降低性能为代价,最小化内存的消耗。
否则,Ignite会试图将所有结果集加载到内存然后将其发送给查询发起方(通常为应用端),这个方式在查询结果集不太大时提供了比较好的性能,并最小化了内部数据库锁的锁定时间,因此增加了并行处理能力。
**警告:**不过如果相对于可用内存来说结果集过大,就是导致长期的GC暂停甚至OutOfMemoryError错误,该参数在Ignite的2.15.0版本之后被废弃。
要改变默认的行为,做法如下:
# 4.6.查询并置的数据
当Ignite执行分布式查询时,它将子查询发送给各个集群节点,并在汇总节点(通常是应用端)上对结果集进行分组。如果预先知道查询的数据是按GROUP BY条件并置处理的,可以使用SqlFieldsQuery.collocated = true来通知SQL引擎在远程节点进行分组处理,这会减少节点之间的网络流量和查询执行时间。当此标志设置为true时,首先对单个节点执行查询,并将结果发送到汇总节点进行最终计算。
考虑下面的示例,假设数据通过department_id进行并置(或者说department_id字段被配置为关联键):
SELECT SUM(salary) FROM Employee GROUP BY department_id
由于SUM操作的性质,Ignite将对存储在各个节点上的数据的薪水求和,然后将这些总和发送到汇总节点,在此处计算最终结果。此操作已经是分布式的,因此启用collocated标志只会稍微提高性能。
下面看一个稍微不同的示例:
SELECT AVG(salary) FROM Employee GROUP BY department_id
在这个示例中,Ignite会在汇总节点拿到所有的(salary,department_id)对然后在该节点计算结果。但是,如果员工通过department_id字段做了并置处理,即同一部门的员工数据存储在同一节点上,则设置SqlFieldsQuery.collocated = true将减少查询执行时间,因为Ignite会在各个节点上计算每个部门的平均值并将结果发送到汇总节点做最终的计算。
# 4.7.强制关联顺序
设置此标志后,查询优化器将不会对关联中的表进行重新排序。换句话说,在查询执行期间实际关联的顺序将与查询中指定的顺序相同。没有此标志,查询优化器可以对关联重新排序以提高性能。但是,有时可能会做出错误的决定。该标志有助于控制和显式指定关联顺序,而不是依赖优化器。
考虑以下示例:
SELECT * FROM Person p
JOIN Company c ON p.company = c.name where p.name = 'John Doe'
AND p.age > 20
AND p.id > 5000
AND p.id < 100000
AND c.name NOT LIKE 'O%';
该查询包含两个表之间的关联:Person和Company。为了获得最佳性能,应了解哪个关联将返回最小的结果集。结果集较小的表应在关联对中首先给出。为了获得每个结果集的大小,下面会测试每个部分:
Q1:
SELECT count(*)
FROM Person p
where
p.name = 'John Doe'
AND p.age > 20
AND p.id > 5000
AND p.id < 100000;
Q2:
SELECT count(*)
FROM Company c
where
c.name NOT LIKE 'O%';
运行Q1和Q2之后,可以看到2个不同的结果:
案例1:
Q1:30000
Q2:100000
Q2的结果集数量大于Q1,这时就不需要修改原始的查询,因为较小的子集已经位于关联的左侧。
案例2:
Q1:50000
Q2:10000
Q1的结果集数量大于Q2,因此需要修改初始的查询,如下所示:
SELECT *
FROM Company c
JOIN Person p
ON p.company = c.name
where
p.name = 'John Doe'
AND p.age > 20
AND p.id > 5000
AND p.id < 100000
AND c.name NOT LIKE 'O%';
强制关联顺序提示的配置方式如下:
- JDBC驱动连接参数;
- ODBC驱动连接属性;
- 如果使用SqlFieldsQuery执行SQL查询,可以调用
SqlFieldsQuery.setEnforceJoinOrder(true)方法。
# 4.8.增加索引内联值
索引中的每个条目都有恒定的大小,该值是在索引创建期间计算的,称为索引内联值。理想情况下,该值应足以存储序列化形式的整个索引条目。如果值未完全包含在索引中,则Ignite可能需要在索引查找期间执行其他数据页读取,如果启用了持久化,则这可能会降低性能。
值在索引中的存储方式如下:
int
0 1 5
| tag | value |
Total: 5 bytes
long
0 1 9
| tag | value |
Total: 9 bytes
String
0 1 3 N
| tag | size | UTF-8 value |
Total: 3 + string length
POJO (BinaryObject)
0 1 5
| tag | BO hash |
Total: 5
对于基本数据类型(boolean、byte、short、int等),Ignite会自动计算索引内联值,以便将值全部包含在内。例如对于int类型字段,内联值为5(1字节为标记,值本身为4字节)。对于long类型字段,内联值为9(1字节为标记,值本身为8字节)。
对于二进制对象,索引包括每个对象的哈希,这足以避免冲突,内联值为5。
对于可变长度字段,索引仅包含值的前几个字节。因此,在为具有可变长度数据的字段建立索引时,建议估计字段值的长度,并将内联值设置为包含大多数(约95%)或所有值的值。例如如果String字段中有95%的值包含10个字符或更少,则可以将该字段索引的内联值设置为13。
上面解释的内联值适用于单个字段索引。但是当在值对象中的字段或非主键列上定义索引时,Ignite会通过将主键附加到索引值来创建组合索引,因此在计算组合索引的内联值时,需要加上主键的内联值。
以下是键和值均为复杂对象的缓存的索引内联值计算示例:
public class Key {
@QuerySqlField
private long id;
@QuerySqlField
@AffinityKeyMapped
private long affinityKey;
}
public class Value {
@QuerySqlField(index = true)
private long longField;
@QuerySqlField(index = true)
private int intField;
@QuerySqlField(index = true)
private String stringField; // we suppose that 95% of the values are 10 symbols
}
下表总结了上例中定义的索引的索引内联值:
| 索引 | 类型 | 建议内联值 | 备注 |
|---|---|---|---|
| (_key) | 主键索引 | 5 | 二进制对象哈希内联值(5) |
| (affinityKey, _key) | 关联键索引 | 14 | long内联值(9)+二进制对象哈希(5) |
| (longField, _key) | 二级索引 | 14 | long内联值(9)+二进制对象哈希(5) |
| (intField, _key) | 二级索引 | 10 | int内联值(5)+二进制对象哈希(5) |
| (stringField, _key) | 二级索引 | 18 | String内联值(13)+二进制对象哈希(5)(假定字符串约10个字符) |
注意,只需要在stringField上设置索引的内联值,对于其他索引,Ignite将自动计算内联值。
关于如何修改内联值的更多信息,请参见配置索引内联值章节的介绍。
可以在INDEXES系统视图中查看现有索引的内联值。
警告
注意,由于Ignite将字符串编码为UTF-8,因此某些字符使用的字节数会超过1个。
# 4.9.查询并行度
SQL查询在每个涉及的节点上,默认是以单线程模式执行的,这种方式对于使用索引返回一个小的结果集的查询是一种优化,比如:
SELECT * FROM Person WHERE p.id = ?;
某些查询以多线程模式执行会更好,这个和带有表扫描以及聚合的查询有关,这在OLAP/HTAP的场景中比较常见,比如:
SELECT SUM(salary) FROM Person;
每个节点上创建的用于查询执行的线程数是缓存级的配置,默认值为1。通过设置CacheConfiguration.queryParallelism参数可以修改该值。如果使用CREATE TABLE命令创建SQL表,则可以使用缓存模板来设置此参数。
如果查询包含关联,则所有参与的缓存必须具有相同的并行度。
# 4.10.索引提示
当知道一个索引比另一个索引更适合某些查询时,索引提示会很有用,可以使用它们来指示查询优化器选择更有效的执行计划。为此,可以使用USE INDEX(indexA,…,indexN)语句,如下例所示:
SELECT * FROM Person USE INDEX(index_age)
WHERE salary > 150000 AND age < 35;
# 4.11.分区精简
分区精简是一种在WHERE条件中使用关联键来对查询进行优化的技术。当执行这样的查询时,Ignite将只扫描存储请求数据的那些分区。这将减少查询时间,因为查询将只发送到存储所请求分区的节点。
在下面的示例中,Employee对象通过id字段并置处理(如果未指定关联键,则Ignite将使用主键来并置数据):
CREATE TABLE employee (id BIGINT PRIMARY KEY, department_id INT, name VARCHAR)
/* This query is sent to the node where the requested key is stored */
SELECT * FROM employee WHERE id=10;
/* This query is sent to all nodes */
SELECT * FROM employee WHERE department_id=10;
下面的示例中,关联键显式指定,因此会被用于并置化的数据,然后查询会直接发给数据对应的主分区所在的节点:
CREATE TABLE employee (id BIGINT PRIMARY KEY, department_id INT, name VARCHAR) WITH "AFFINITY_KEY=department_id"
/* This query is sent to all nodes */
SELECT * FROM employee WHERE id=10;
/* This query is sent to the node where the requested key is stored */
SELECT * FROM employee WHERE department_id=10;
提示
有关数据如何并置以及如何帮助提高Ignite性能的详细信息,请参见关联并置章节的介绍。
# 4.12.更新时忽略汇总
当Ignite执行DML操作时,首先,它会获取所有受影响的中间行用于汇总节点的分析(通常为应用端),然后才准备将要发送到远程节点的一批更新值。
如果一个DML操作需要移动大量数据,这个方式可能导致性能问题以及网络的堵塞。
使用这个标志可以作为一个提示,它使Ignite会在对应的远程节点上进行中间行的分析和更新,JDBC和ODBC连接都支持这个提示:
jdbc:ignite:thin://192.168.0.15/skipReducerOnUpdate=true
# 4.13.SQL堆内行缓存
Ignite会在Java堆外存储数据和索引,这意味着每次数据访问,就会有一部分数据从堆外数据区复制到堆内,只要应用或者服务端节点引用它,就有可能被反序列化并且一直保持在堆内。
SQL堆内行缓存的目的就是在Java堆内存储热点数据(键-值对象),使反序列化和数据复制的资源消耗最小化,每个缓存的行都会指向堆外数据区的一个数据条目,并且在如下情况下会失效:
- 存储在堆外数据区的主条目被更新或者删除;
- 存储主条目的数据页面从内存中退出。
堆内行缓存是缓存/表级的(如果使用CREATE TABLE语句来创建表/缓存,相关的参数可以通过缓存模板传递)。
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="cacheConfiguration">
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="myCache"/>
<property name="sqlOnheapCacheEnabled" value="true"/>
</bean>
</property>
</bean>
如果启用了行缓存,则会以内存换性能。通过为行缓存分配更多的内存,对于某些SQL查询和场景,可能会获得2倍的性能提升。
SQL堆内行缓存大小
目前,该缓存没有限制,可以和堆外数据区一样,占用更多的内存,但是:
- 如果开启了堆内行缓存,需要配置JVM的最大堆大小为存储缓存的所有数据区的总大小;
- 调整JVM的垃圾回收。
# 4.14.使用TIMESTAMP替代DATE
尽可能地使用TIMESTAMP替代DATE,目前DATE类型的序列化/反序列化效率较低,导致性能下降。
# 5.线程池调优
# 5.1.概述
Ignite创建并且维护着一组线程池,根据使用的API不同分别用于不同的目的。本章节中会列出一些常规的内部线程池,然后会展示如何自定义线程池。
# 5.2.系统线程池
系统线程池处理所有与缓存相关的操作,除了SQL以及其它的查询类型,它们会使用查询线程池,同时这个线程池也负责处理Ignite计算任务的取消操作。
默认的线程池数量为max(8,CPU总核数),使用IgniteConfiguration.setSystemThreadPoolSize(...)或者使用的编程语言的类似API可以进行调整。
# 5.3.查询线程池
查询线程池处理集群内所有的SQL、扫描和SPI查询。
默认的线程池数量为max(8,CPU总核数),使用IgniteConfiguration.setQueryThreadPoolSize(...)或者使用的编程语言的类似API可以进行调整。
# 5.4.公共线程池
公共线程池负责Ignite的计算网格,所有的计算任务都由这个线程池接收然后处理。
默认的线程池数量为max(8,CPU总核数),使用IgniteConfiguration.setPublicThreadPoolSize(...)或者使用的编程语言的类似API可以进行调整。
# 5.5.服务线程池
Ignite的服务网格调用使用的是服务线程池,Ignite的服务和计算网格组件都有专用的线程池,可以避免当一个服务实现希望调用一个计算(或者反之)时的线程争用和死锁。
默认的线程池数量为max(8,CPU总核数),使用IgniteConfiguration.setServiceThreadPoolSize(...)或者使用的编程语言的类似API可以进行调整。
# 5.6.平行线程池
平行线程池通过将操作展开为多个平行的执行,有助于显著加速基本的缓存操作以及事务,因为可以避免相互竞争。
默认的线程池数量为max(8,CPU总核数),使用IgniteConfiguration.setStripedPoolSize(...)或者使用的编程语言的类似API可以进行调整。
# 5.7.数据流处理器线程池
数据流处理器线程池用于处理来自IgniteDataStreamer的所有消息和请求,各种内置的使用IgniteDataStreamer的流适配器也可以。
默认的线程池数量为max(8,CPU总核数),使用IgniteConfiguration.setDataStreamerThreadPoolSize(...)或者使用的编程语言的类似API可以进行调整。
# 5.8.快照线程池
快照线程池用于处理和集群快照的生成或恢复有关的所有集群操作。
默认的线程池大小为4(参见IgniteConfiguration.DFLT_SNAPSHOT_THREAD_POOL_SIZE),使用IgniteConfiguration.setSnapshotThreadPoolSize()可以调整该线程池大小。
# 5.9.自定义线程池
对于Ignite的计算任务,也可以配置自定义的线程池,当希望同步地从一个计算任务调用另一个的时候很有用,因为可以避免死锁。要保证这一点,需要确保执行嵌套任务的线程池不同于上级任务的线程池。
自定义线程池需要在IgniteConfiguration中进行定义,并且需要有一个唯一的名字:
这样,假定下面的计算任务由上面定义的myPool线程池中的线程执行:
public class InnerRunnable implements IgniteRunnable {
@Override public void run() {
System.out.println("Hello from inner runnable!");
}
}
为此,需要使用IgniteCompute.withExecutor(),它会从上级任务马上执行该任务,如下所示:
public class OuterRunnable implements IgniteRunnable {
@IgniteInstanceResource
private Ignite ignite;
@Override public void run() {
// Synchronously execute InnerRunnable in custom executor.
ignite.compute().withExecutor("myPool").run(new InnerRunnable());
}
}
上级任务的执行可通过如下方式触发,对于这个场景,它会由公共线程池执行:
ignite.compute().run(new OuterRunnable());
未定义线程池
如果应用请求在自定义线程池执行计算任务,而该线程池在Ignite节点中未定义,那么一个固定的警告消息就会在节点的日志中输出,然后任务就会被公共线程池接管执行。
# 6.故障排除和调试
本章节会介绍一些对Ignite集群进行调试和故障排除的常见提示和技巧。
# 6.1.调试工具:一致性检查命令
./control.sh|bat工具包括了一组一致性检查命令,可帮助验证内部数据一致性问题。
# 6.2.重启后持久化文件丢失
在某些系统上,Ignite持久化文件的默认位置可能在temp文件夹下。这可能导致以下情况:每当重启节点进程时,操作系统都会删除持久化文件。为了避免这种情况:
- 确保Ignite启用
WARN日志记录级别。如果将持久化文件写入临时目录,则会看到警告; - 使用
DataStorageConfigurationAPI,例如setStoragePath(…)、setWalPath(…)和setWalArchivePath(…)更改持久化文件的位置。
# 6.3.字段类型变更后集群无法启动
在开发应用时,可能需要修改字段的类型。举例来说,假设有对象A的字段A.range为int类型,然后将A.range类型更改为long,执行此操作后,集群或应用将无法重启,因为Ignite不支持字段/列类型的更改。
这时,如果仍处于开发阶段,则需要进入文件系统并删除以下目录:位于Ignite工作目录的marshaller/、db/和wal/(如果调整了位置,db和wal可能位于其他地方)。
但是,如果在生产环境,则不要更改字段类型,而是在对象模型中添加一个不同名的新字段,并删除旧字段,此操作是完全支持的。同时,ALTER TABLE命令可用于在运行时添加新列或删除现有列。
# 6.4.GC问题调试
本章节的内容在需要调试和解决与Java堆使用或GC暂停有关的问题时会有所帮助。
# 6.4.1.堆转储
如果JVM抛出了OutOfMemoryException异常,则下次发生异常时会自动转储堆。这会有助于了解此异常的根本原因,并可以更深入地了解发生故障时的堆状态。
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/path/to/heapdump
-XX:OnOutOfMemoryError=“kill -9 %p”
-XX:+ExitOnOutOfMemoryError
# 6.4.2.详细GC日志
为了捕获有关GC相关活动的详细信息,确认已在集群节点的JVM设置中配置了以下参数:
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=10
-XX:GCLogFileSize=100M
-Xloggc:/path/to/gc/logs/log.txt
将/path/to/gc/logs/用实际路径替换。
此外,对于G1收集器,需配置下面的属性。它提供了许多有意未包含在-XX:+PrintGCDetails参数中的其他细节信息:
-XX:+PrintAdaptiveSizePolicy
# 6.4.3.使用Flight Recorder进行性能分析
如果需要调试性能或内存问题,则可以使用Java Flight Recorder持续收集底层的运行时统计信息,从而可以进行事后分析。要启用Java Flight Recorder,请使用以下JVM参数:
-XX:+UnlockCommercialFeatures
-XX:+FlightRecorder
-XX:+UnlockDiagnosticVMOptions
-XX:+DebugNonSafepoints
要在固定的Ignite节点上开始记录状态,请使用以下命令:
jcmd <PID> JFR.start name=<recordcing_name> duration=60s filename=/var/recording/recording.jfr settings=profile
有关Flight Recorder的详细信息,请参考Oracle的官方文档。
# 6.4.4.JVM暂停
有时可能会看到有关JVM暂停时间太长的警告消息,例如可能在批量加载期间发生这个问题。
调整IGNITE_JVM_PAUSE_DETECTOR_THRESHOLD超时设置可以增加处理时间以等待完成而不产生警告。可以通过环境变量设置该阈值,或将其作为JVM参数(-DIGNITE_JVM_PAUSE_DETECTOR_THRESHOLD=5000)或作为ignite.sh的参数(-J-DIGNITE_JVM_PAUSE_DETECTOR_THRESHOLD=5000)。
该值以毫秒为单位。
# 7.处理异常
本章节会介绍Ignite可以生成的基本异常,还会解释如何配置和使用严重故障处理器。
# 7.1.处理Ignite异常
下表描述了Ignite API支持的异常以及可以用来处理这些异常的操作。可以查看javadoc中的throws子句,查看是否存在已检查异常。
| 异常 | 描述 | 要采取的动作 | 运行时异常 |
|---|---|---|---|
CacheInvalidStateException | 当在分区发生丢失的缓存上执行操作时会抛出此异常。根据缓存配置的分区丢失策略,读/写操作都可能抛出此异常,具体请参见分区丢失策略章节的介绍。 | 重置丢失的分区,通过将触发分区丢失的节点恢复到集群可以恢复数据。 | 是 |
IgniteException | 此异常表示网格中存在错误。 | 操作失败,从方法退出。 | 是 |
IgniteClientDisconnectedException | 当客户端节点与集群断开连接时,Ignite API(缓存操作、计算API和数据结构操作)会抛出此异常。 | 在Future中等待并重试。 | 是 |
IgniteAuthenticationException | 当节点身份验证失败或安全身份验证失败时,会抛出此异常。 | 操作失败,从方法退出。 | 否 |
IgniteClientException | 缓存操作会抛出此异常。 | 根据异常消息确定下一步的动作。 | 是 |
IgniteDeploymentException | 当Ignite API(计算网格相关)未能在节点上部署作业或任务时,会抛出此异常。 | 操作失败,从方法退出。 | 是 |
IgniteInterruptedException | 此异常用于将标准InterruptedException包装为IgniteException。 | 清除中断标志后重试。 | 是 |
IgniteSpiException | SPI引发的异常,如CollisionSpi、LoadBalancingSpi、TcpDiscoveryIpFinder、FailoverSpi、UriDeploymentSpi等。 | 操作失败,从方法退出。 | 是 |
IgniteSQLException | SQL查询处理失败会抛出此异常,该异常会包含相关规范定义的错误代码。 | 操作失败,从方法退出。 | 是 |
IgniteAccessControlException | 认证/授权失败时会抛出此异常。 | 操作失败,从方法退出。 | 否 |
IgniteCacheRestartingException | 如果缓存正在重启,Ignite的缓存API会抛出此异常。 | 在Future中等待并重试。 | 是 |
IgniteFutureTimeoutException | 当Future的计算超时时,会抛出此异常。 | 要么增加超时限制要么方法退出。 | 是 |
IgniteFutureCancelledException | 当Future的计算因为被取消而无法获得结果时,会抛出此异常。 | 可进行重试。 | 是 |
IgniteIllegalStateException | 此异常表示Ignite实例对于请求的操作处于无效状态。 | 操作失败,从方法退出。 | 是 |
IgniteNeedReconnectException | 此异常显示节点应尝试重新连接到集群。 | 可进行重试。 | 否 |
IgniteDataIntegrityViolationException | 如果发现数据完整性冲突,会抛出此异常。 | 操作失败,从方法退出。 | 是 |
IgniteOutOfMemoryException | 系统没有足够内存处理Ignite操作(缓存操作)时,会抛出此异常。 | 操作失败,从方法退出。 | 是 |
IgniteTxOptimisticCheckedException | 当事务以乐观方式失败时,会抛出此异常。 | 可进行重试 | 否 |
IgniteTxRollbackCheckedException | 当事务自动回滚时,会抛出此异常。 | 可进行重试。 | 否 |
IgniteTxTimeoutCheckedException | 当事务超时时,会抛出此异常。 | 可进行重试。 | 否 |
ClusterTopologyException | 当集群拓扑发生错误(比如节点故障)时会抛出此异常(针对计算和事件API)。 | 在Future中等待并重试。 | 是 |
# 7.2.严重故障处理
Ignite是一个强大且容错的系统。但是在现实中总会出现一些无法预测的问题,这些问题会影响单个节点甚至整个集群的状态。可以在运行时检测到此类问题,并使用预配置的严重故障处理器进行相应的处理。
# 7.2.1.严重故障
以下故障被视为严重故障:
- 系统级严重错误(
OutOfMemoryError); - 意外的系统工作进程终止(未处理的异常);
- 系统工作进程被终止;
- 集群脑裂。
系统级严重错误会导致系统无法操作,比如:
- 文件I/O错误:通常
IOException由文件读/写抛出,通常在开启持久化时会发生(比如磁盘空间不足或者设备故障),或者在内存模式中,Ignite会使用磁盘来存储部分元数据(比如达到了文件描述符限制或者文件访问被禁止); - 内存溢出错误:Ignite内存管理系统无法分配更多的空间(
IgniteOutOfMemoryException); - 内存溢出错误:集群节点堆溢出(
OutOfMemoryError);
# 7.2.2.故障处理
Ignite检测到严重的错误后,会通过预配置的故障处理器进行处理,配置方法如下:
Ignite支持如下的故障处理器:
| 类 | 描述 |
|---|---|
NoOpFailureHandler | 忽略任何故障,用于测试和调试环境。 |
RestartProcessFailureHandler | 只能用于ignite.(sh|bat)的特定实现,进程必须使用Ignition.restart(true)调用进行终止。 |
StopNodeFailureHandler | 出现严重错误时,使用Ignition.stop(true)或者Ignition.stop(nodeName, true)调用停止节点。 |
StopNodeOrHaltFailureHandler | 默认处理器,它会试图停止节点,如果无法停止,那么它会试图终止JVM进程。 |
# 7.2.3.关键工作进程健康检查
Ignite内部有一些工作进程,它们对集群的正常运行非常重要。如果它们中的一个终止了,Ignite节点可能变为失效状态。
下面的系统级工作进程为关键进程:
- 发现进程:发现事件处理;
- TCP通信进程:节点间的点对点通信;
- 交换进程:分区映射交换;
- 系统级平行线程池进程;
- 数据流处理器平行线程池进程;
- 超时进程:超时处理;
- 检查点线程:Ignite持久化的检查点;
- WAL进程:预写日志、段存档和压缩;
- 过期进程:基于TTL的过期;
- NIO进程:基础拓扑操作;
Ignite有一个内部机制用于验证关键进程是否正常,会定期检查每个进程是否在线,并更新其心跳时间戳。如果某个进程不在线并正在更新,则该进程会被视为阻塞,然后Ignite会在日志文件中输出信息。通过IgniteConfiguration.systemWorkerBlockedTimeout属性可以配置该不在线的时间段。
尽管Ignite认为无响应的系统工作进程是严重错误,但除了将消息输出到日志文件之外,它不会自动处理这种情况。如果要为所有类型的无响应系统工作进程启用固定的故障处理器,需清除处理器的ignoredFailureTypes属性,如下所示:
# 8.Yardstick基准测试
# 8.1.Yardstick Ignite基准测试
Ignite的基准测试是在Yardstick框架之上实现的,通过它可以测试Ignite各种组件和模块的性能。下面的章节介绍了如何配置和执行预编译的测试,如果需要添加新的基准测试或者构建已有的测试,那么请参照源代码目录中的DEVNOTES.txt文件中的介绍。
访问Yardstick库可以了解更多的细节,比如生成的测试报告以及框架的工作原理。
# 8.2.在本机运行Ignite的基准测试
进行测试的最简单方式是使用benchmarks/bin目录中的可执行脚本。
./bin/benchmark-run-all.sh config/benchmark-sample.properties
上面的命令会测试一个分布式原子化缓存的put操作,测试结果会被添加到一个自动生成的output/results-{DATE-TIME}目录中。
如果./bin/benchmark-run-all.sh命令执行时没有传递任何参数,并且也没有修改配置文件,那么所有的可用测试会在本地主机使用config/benchmark.properties配置文件执行,遇到问题,会在一个自动生成的目录output/logs-{DATE-TIME}中生成日志。
# 8.3.在远程运行Ignite的基准测试
如果要在若干远程主机上进行测试,需要按照如下步骤进行:
- 打开
config/ignite-remote-config.xml文件,然后将<value>127.0.0.1:47500..47509</value>替换为实际的所有远程主机IP列表,如果要使用其它类型的IP探测器,可以参照相关的集群配置文档; - 打开
config/benchmark-remote-sample.properties文件,然后将下列位置的localhost替换为实际的所有远程主机IP列表:SERVERS=localhost,localhost和DRIVERS=localhost,localhost,DRIVER是实际执行测试逻辑的主机(通常是Ignite客户端节点),SERVERS是被测试的节点,如果要进行所有测试,则需要替换config/benchmark-remote.properties文件中的相同内容; - 将Yardstick测试上传到
DRIVERS主机之一的工作目录; - 登录
DRIVER所在的主机,然后执行如下命令:./bin/benchmark-run-all.sh config/benchmark-remote-sample.properties
所有必要的文件默认会被自动地从执行上面命令的主机上传到所有其它主机的相同目录,如果要手工做,则需要将配置文件中的AUTO_COPY变量设为false。
上面的命令会测试一个分布式原子化缓存的put操作,测试结果会被添加到一个自动生成的output/results-{DATE-TIME}目录中。
如果要在远程节点执行所有的测试,那么需要在DRIVER端执行如下的命令:
/bin/benchmark-run-all.sh config/benchmark-remote.properties
# 8.4.已有的测试点
目前默认提供的测试点如下:
GetBenchmark:测试分布式原子化缓存的get操作;PutBenchmark:测试分布式原子化缓存的put操作;PutGetBenchmark:一起测试分布式原子化缓存的get和put操作;PutTxBenchmark:测试分布式事务化缓存的put操作;PutGetTxBenchmark:一起测试分布式事务化缓存的get和put操作;SqlQueryBenchmark:测试在缓存数据上执行分布式SQL查询;SqlQueryJoinBenchmark:测试在缓存数据上执行带关联的分布式SQL查询;SqlQueryPutBenchmark:测试在执行分布式SQL查询的时候同时进行缓存的更新;AffinityCallBenchmark:测试关联调用操作;ApplyBenchmark:测试apply操作;BroadcastBenchmark:测试broadcast操作;ExecuteBenchmark:测试execute操作;RunBenchmark:测试任务的执行操作;PutGetOffHeapBenchmark:测试在有堆外内存的情况下,分布式原子化缓存的put和get操作;PutGetOffHeapValuesBenchmark:测试在有堆外内存的情况下,分布式原子化缓存的put值操作;PutOffHeapBenchmark:测试在有堆外内存的情况下,分布式原子化缓存的put操作;PutOffHeapValuesBenchmark:测试在有堆外内存的情况下,分布式原子化缓存的put值操作;PutTxOffHeapBenchmark:测试在有堆外内存的情况下,分布式事务化缓存的put操作;PutTxOffHeapValuesBenchmark:测试在有堆外内存的情况下,分布式事务化缓存的put值操作;SqlQueryOffHeapBenchmark:测试在堆外的缓存数据上执行分布式SQL查询操作;SqlQueryJoinOffHeapBenchmark:测试在堆外的缓存数据上执行带关联的分布式SQL查询操作;SqlQueryPutOffHeapBenchmark:测试在堆外的缓存数据上执行分布式SQL查询的同时进行缓存的更新操作;PutAllBenchmark:测试在分布式原子化缓存中进行批量put操作;PutAllTxBenchmark:测试在分布式事务化缓存中进行批量put操作。
# 8.5.属性文件和命令行参数
本章节只会描述和Ignite测试有关的配置参数,并不是Yardstick框架的所有参数。如果要进行Ignite测试并且生成结果,需要使用bin文件夹中的Yardstick框架脚本执行测试用例。
在Yardstick文档中有Yardstick框架的配置参数和命令行参数的详细说明。
下面的Ignite测试属性可以在测试配置中进行定义:
-b <num>或者--backups <num>:每个键的备份数量;-cfg <path>或者--Config <path:Ignite配置文件的路径;-cs或者--cacheStore:打开或者关闭缓存存储的通读和通写;-cl或者--client:客户端标志,如果有多个DRIVER时需要使用这个标志,除了这个以外的其它DRIVER的行为类似于SERVER;-nc或者--nearCache:近缓存标志;-nn <num>或者--nodeNumber <num>:在benchmark.properties中自动配置的节点数量,用于等待启动指定数量的节点;-sm <mode>或者-syncMode <mode>:同步模式(定义于CacheWriteSynchronizationMode);-r <num>或者--range:为缓存操作随机生成的键的范围;-rd或者--restartdelay:重启延迟(秒);-rs或者--restartsleep:重启睡眠(秒);-rth <host>或者--restHost <host>:REST TCP主机;-rtp <num>或者--restPort <num>:REST TCP端口;-ss或者--syncSend:表示TcpCommunicationSpi中是否同步发送消息的标志;-txc <value>或者--txConcurrency <value>:缓存事务的并发控制,PESSIMISTIC或者OPTIMISTIC(由CacheTxConcurrency进行定义);-txi <value>或者--txIsolation <value>:缓存事务隔离级别(由CacheTxIsolation定义);-wb或者--writeBehind:打开/关闭缓存存储的后写;
比如,要在本地启动两个节点进行PutBenchmark测试,备份数为1,同步模式为PRIMARY_SYNC,那么需要在benchmark.properties文件中指定如下的配置:
SERVER_HOSTS=localhost,localhost
...
# Note that -dn and -sn, which stand for data node and server node,
# are native Yardstick parameters and are documented in
# Yardstick framework.
CONFIGS="-b 1 -sm PRIMARY_SYNC -dn PutBenchmark`IgniteNode"
# 8.6.从源代码构建
在Ignite的根目录中执行:./mvnw clean package -Pyardstick -pl modules/yardstick -am -DskipTests。
这个命令会对工程进行编译,还会从yardstick-resources.zip文件中解压脚本到modules/yardstick/target/assembly/bin目录。
构件位于modules/yardstick/target/assembly目录。
# 8.7.自定义Ignite测试
所有的测试用例都需要继承AbstractBenchmark类,并且实现test方法(这个方法实际执行性能测试)。
18624049226
