# 监控
# 1.介绍
本章节介绍Ignite的监控和指标。首先会介绍可用于监控的方法,然后再深入介绍Ignite的细节,包括一个JMX指标和MBean的列表。
# 1.1.概述
Ignite中监控的基本任务涉及指标,访问指标有几种方法:
# 1.2.监控什么
可以监控:
- 单独的每个节点;
- 节点之间的连接;
- 整个集群。
注意,节点由几个层次组成:硬件、操作系统、虚拟机(JVM等)和应用,所有这些层级及其之间的网络都需要检查。
- 硬件(Hypervisor):CPU/内存/磁盘⇒系统日志/云供应商的日志;
- 操作系统;
- JVM:GC日志、JMX、Java Flight Recorder、线程转储、堆转储等;
- 应用:日志、JMX、吞吐量/延迟、测试查询;
- 对于基于日志的监控,关键是主动采取行动,观察日志中的趋势等信息,而不仅仅是等到出现问题后才检查日志。
- 网络:连通性监控、网络硬件监控、TCP转储。
对于配置硬件、操作系统和网络监控,这些就可以了。如果要监控应用层(组成内存计算解决方案的节点),则需要通过JMX/Beans或以编程方式访问指标系统来执行特定于Ignite的监控。
# 1.3.全局与节点级指标
通过不同的指标公开的信息具有不同的作用域(适用性),并且根据取得指标的节点不同,可能也会有所不同。以下列表说明了不同指标的作用域:
全局指标
通常提供有关集群的信息,例如:节点数、集群状态,该信息在集群的任何节点上都可用。
节点级指标
提供获取指标的节点的专有信息,例如:内存消耗量、数据区指标、WAL大小、队列大小等。
与缓存相关的指标可以是全局的,也可以是节点级的。例如,缓存中的条目总数是全局指标,可以在任意节点上获取。还可以获取存储在某节点上的缓存条目数,这时他就是节点级的指标。
# 2.集群ID和标签
集群ID是集群的唯一标识符,该标识符在集群首次启动时自动生成。集群标签是可以分配给集群的用户友好名称。可以使用这些值在所使用的监控系统中对集群进行标识。
集群的默认标签是自动生成的,但是可以修改,标签的长度限制为280个字符。
可以使用以下方法查看集群ID以及查看或更改集群标签:
通过控制脚本;
JMX Bean:
group=IgniteCluster,name=IgniteClusterMXBeanImpl属性 类型 描述 Id String 集群ID Tag String 集群标签 操作 描述 Tag(String) 设定新的集群标签 编程方式:
Ignite ignite = Ignition.start(); // get the cluster id java.util.UUID clusterId = ignite.cluster().id(); // change the cluster tag ignite.cluster().tag("new_tag");
# 3.集群状态
# 3.1.概述
Ignite集群有3种状态:ACTIVE、ACTIVE_READ_ONLY和INACTIVE。
首次启动纯内存集群(无持久化数据区)时,该集群处于ACTIVE状态,首次启动开启持久化数据区的集群时,该集群为INACTIVE状态。
INACTIVE:禁止所有操作;当将集群状态从
ACTIVE更改为INACTIVE(冻结)时,集群将撤销已分配的所有内存资源。ACTIVE:这是集群的正常状态,可以执行任何操作;ACTIVE_READ_ONLY:只读状态,仅允许读取操作。任何尝试创建缓存或修改现有缓存中的数据都会触发
IgniteClusterReadOnlyException异常,DDL或者修改数据的DML也是禁止的。
# 3.2.改变集群状态
可以通过多种方式更改集群状态:
控制脚本:
control.sh --set-state ACTIVE_READ_ONLY-
http://localhost:8080/ignite?cmd=setstate&state=ACTIVE_READ_ONLY 以编程方式:
Ignite ignite = Ignition.start(); ignite.cluster().state(ClusterState.ACTIVE_READ_ONLY);JMX Bean:
Mbean的对象名称:
group="Kernal",name=IgniteKernal操作 描述 clusterState()获取当前集群状态 clusterState(String,boolean)设置集群状态
# 4.指标系统
# 4.1.介绍
# 4.1.1.概述
本章节会介绍指标系统以及如何使用它来监控集群。
下面会介绍Ignite中新指标系统的基本概念。首先,有不同的指标,每个指标都有一个名称和一个返回值。返回值可以是一个简单的值,比如String、long或double,也可以表示为一个Java对象。一些指标表示直方图。
然后,有多种导出指标的方法,称为导出器。换句话说,导出器是访问指标的不同方法,每个导出器都可以访问所有的可用指标。
Ignite包括以下导出器:
- JMX(默认);
- SQL视图;
- 日志文件;
- OpenCensus。
通过实现MetricExporterSpi接口可以创建自定义的导出器。
# 4.1.2.指标注册表
指标被分为几类(称为注册表)。每个注册表都有一个名称。注册表中某个指标的全名由注册表名称,后跟一个点和指标名称组成<register_name>.<metric_name>。例如,数据存储指标的注册表为io.datastorage。返回存储大小的指标为io.datastorage.StorageSize。
所有的注册表及其包含的指标的列表在这里。
# 4.1.3.指标导出器
如果要启用指标,需要在节点配置中配置一个或多个指标导出器。这是节点级的配置,意味着可以仅在某个节点上启用指标。
下面的章节会介绍Ignite中默认可用的导出器。
# 4.1.3.1.JMX
org.apache.ignite.spi.metric.jmx.JmxMetricExporterSpi会通过JMX Beans暴露指标信息。
IgniteConfiguration cfg = new IgniteConfiguration();
// Create configured JMX metrics exporter.
JmxMetricExporterSpi jmxExporter = new JmxMetricExporterSpi();
//export cache metrics only
jmxExporter.setExportFilter(mreg -> mreg.name().startsWith("cache."));
cfg.setMetricExporterSpi(jmxExporter);
提示
如果未通过IgniteConfiguration.setMetricExporterSpi(…)进行配置,该导出器默认启用。
IgniteConfiguration cfg = new IgniteConfiguration();
// Disable default JMX metrics exporter. Also could be disabled with the system property
// '-DIGNITE_MBEANS_DISABLED=true' or by setting other metrics exporter.
cfg.setMetricExporterSpi(new NoopMetricExporterSpi());
为Ignite开启JMX
JMX默认是禁用的,可通过如下的环境变量启用JMX。
- 对于
control.sh,配置CONTROL_JVM_OPTS环境变量; - 对于
ignite.sh,配置JVM_OPTS环境变量。
示例:
JVM_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=${JMX_PORT} \
-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false"
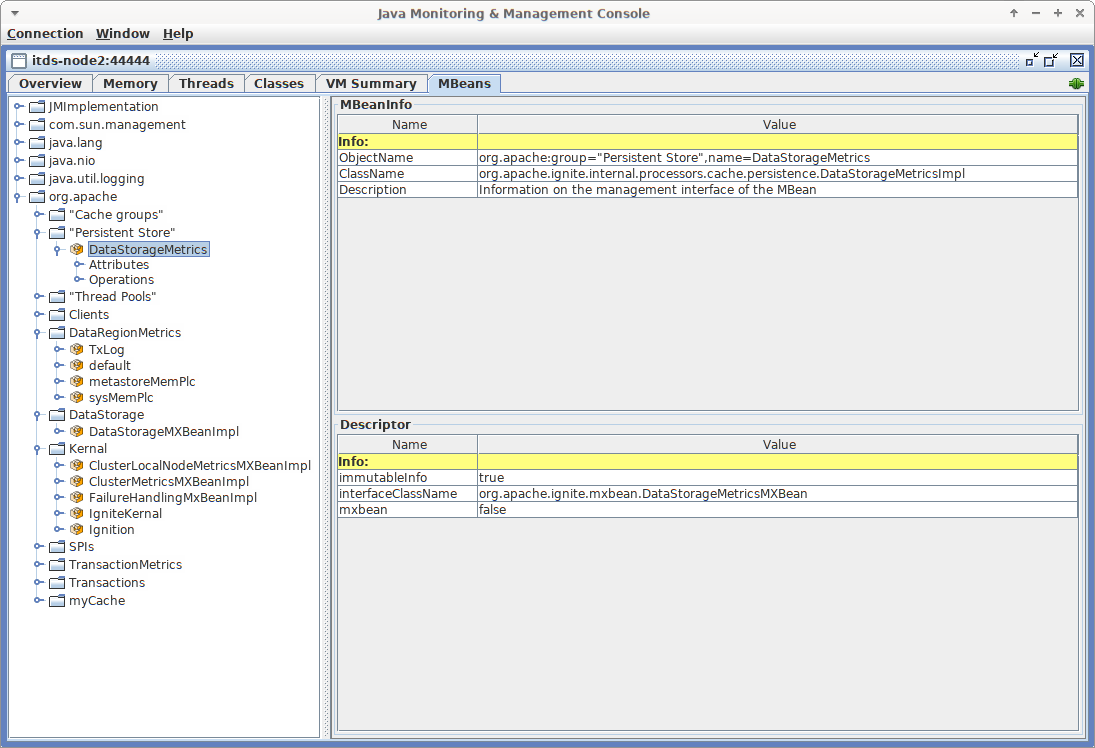
理解MBean的ObjectName
每个JMX MBean都有一个ObjectName。ObjectName用于标识bean,ObjectName由域和键属性列表组成,并且可以表示为字符串,如下所示:
domain: key1 = value1 , key2 = value2
所有Ignite指标都具有相同的域:org.apache.<classloaderId>。classloaderId是可选的(如果配置IGNITE_MBEAN_APPEND_CLASS_LOADER_ID=false,则会忽略)。此外每个指标都有两个属性:group和name,例如:
org.apache:group=SPIs,name=TcpDiscoverySpi
该MBean提供了与节点发现有关的各种指标。
MBean的ObjectName可用于在UI工具(如JConsole)中标识bean。例如,JConsole以树状结构显示MBean,其中所有Bean首先按域分组,然后按group属性分组:
# 4.1.3.2.SQL视图
SqlViewMetricExporterSpi默认是开启的,其会通过SYS.METRICS视图暴露指标信息,每个指标会显示为一行记录,可以使用任何支持SQL的工具查看指标。
> select name, value from SYS.METRICS where name LIKE 'cache.myCache.%';
+-----------------------------------+--------------------------------+
| NAME | VALUE |
+-----------------------------------+--------------------------------+
| cache.myCache.CacheTxRollbacks | 0 |
| cache.myCache.OffHeapRemovals | 0 |
| cache.myCache.QueryCompleted | 0 |
| cache.myCache.QueryFailed | 0 |
| cache.myCache.EstimatedRebalancingKeys | 0 |
| cache.myCache.CacheEvictions | 0 |
| cache.myCache.CommitTime | [J@2eb66498 |
....
# 4.1.3.3.Log
org.apache.ignite.spi.metric.log.LogExporterSpi在INFO级别以固定间隔(默认为1分钟)将指标输出到日志文件。
# 4.1.3.4.OpenCensus
org.apache.ignite.spi.metric.opencensus.OpenCensusMetricExporterSpi实现了与OpenCensus库的集成。
OpenCensus导出器使用方法:
- 启用ignite-opencensus模块;
- 将
org.apache.ignite.spi.metric.opencensus.OpenCensusMetricExporterSpi添加到节点配置的导出器列表; - 配置OpenCensus StatsCollector以导出到某个系统,具体示例请参见OpenCensusMetricsExporterExample.java以及OpenCensus的文档。
配置参数:
filter:谓词过滤指标;period:导出时间间隔;sendInstanceName:如果启用,则将Ignite实例名的标签添加到每个指标;sendNodeId:如果启用,则将具有Ignite节点ID的标签添加到每个指标;sendConsistentId:如果启用,则将具有Ignite节点一致性ID的标签添加到每个指标。
# 4.1.4.直方图
表示直方图的指标仅在JMX导出器中可用。直方图指标作为一组值导出,其中每个值对应于某个存储桶,可通过单独的JMX Bean属性使用。直方图指标的属性名称具有以下格式:
{metric_name}_{low_bound}_{high_bound}
这里:
{metric_name}:指标名称;{low_bound}:边界的起点,0是第一个界限;{high_bound}:界限的终点,inf是最后的界限;
范围为[10,100]时的指标名称示例:
histogram_0_10:小于10;histogram_10_100:10至100;histogram_100_inf:超过100。
# 4.1.5.常见监控任务
# 4.1.5.1.数据量监控
如果不使用原生持久化(即所有数据都保存在内存中),则需要监视内存使用情况。如果使用了原生持久化,则除了内存外,还应该监控磁盘上数据存储的大小。
加载到节点中的数据大小可在不同级别上聚合,可以监控以下内容:
- 节点在磁盘或内存上保存的数据总大小。此数量是每个已配置的数据区(在最简单的情况下,仅默认数据区)的大小加上系统数据区的大小;
- 该节点上某数据区的大小,数据区大小是所有缓存组的大小之和;
- 该节点上某缓存/缓存组的大小,包括备份分区。
可以分别为每个级别启用/禁用这些指标,并通过下面列出的不同JMX Bean公开这些指标。
分配空间和数据实际大小
无法获取数据的确切大小(无论是在内存中还是在磁盘上),不过有两种估算方法。
可以获得用于存储数据的已分配空间大小(这里的“空间”指的是内存或磁盘上的空间,具体取决于是否使用原生持久化)。当存储空间已满并且需要添加更多条目时,将进一步分配空间。但是从缓存中删除条目时,不会释放空间。后续写入新数据时,该空间可以重用。因此当从缓存中删除条目时,分配的大小不会减小。分配的大小在数据存储、数据区和缓存组指标级别都有效,该指标称为TotalAllocatedSize。
还可以通过将使用中的数据页数乘以填充因子来估算实际数据大小。填充因子是页面中数据大小与页面大小之比,是所有页面的平均值。正在使用的页面数和填充因子在数据区指标级别有效。
将所有数据区的估计大小加起来就可以知道节点上的估计数据总量。
监控内存使用量
| 属性 | 类型 | 描述 | 作用域 |
|---|---|---|---|
| PagesFillFactor | float | 页面中数据的平均大小与页面大小的比率。启用原生持久化后,此指标仅适用于持久化存储(即磁盘上的页面)。 | 节点 |
| TotalUsedPages | long | 当前正在使用的数据页数。启用原生持久化后,此指标仅适用于持久化存储(即磁盘上的页面)。 | 节点 |
| PhysicalMemoryPages | long | 内存中分配的页数。 | 节点 |
| PhysicalMemorySize | long | 内存中分配的空间大小(字节)。 | 节点 |
如果有多个数据区,则将所有数据区的大小加起来就可以知道节点上数据的总大小。
监控存储大小
开启持久化存储后,会将所有的应用数据保存在磁盘上。每个节点在磁盘上持有的总数据量由持久化存储(应用数据)、WAL文件和WAL存档文件组成。
持久化存储大小
| 属性 | 类型 | 描述 | 作用域 |
|---|---|---|---|
| TotalAllocatedSize | long | 磁盘上为整个数据存储分配的空间大小(字节)。注意当禁用原生持久化时,此指标将显示内存中已分配空间的总大小。 | 节点 |
| WalTotalSize | long | WAL文件的总大小(字节),包括WAL存档文件。 | 节点 |
| WalArchiveSegments | int | 存档中的WAL段数量。 | 节点 |
| 操作 | 描述 |
|---|---|
| enableMetrics | 在运行时启用与持久化存储有关的指标收集。 |
| disableMetrics | 禁用指标收集。 |
数据区大小
数据区的指标收集默认是禁用的,可以在数据区配置中启用。
节点上数据区的大小包括该数据区中所有缓存拥有的所有分区(包括备份分区)的大小。
| 属性 | 类型 | 描述 | 作用域 |
|---|---|---|---|
| TotalAllocatedSize | long | 分配给该数据区的空间大小(字节)。注意当禁用原生持久化时,此指标将显示内存中已分配空间的总大小。 | 节点 |
| PagesFillFactor | float | 页面中的平均数据量与页面大小的比率。 | 节点 |
| TotalUsedPages | long | 当前正在使用的数据页数。 | 节点 |
| PhysicalMemoryPages | long | 内存中存储的该数据区中的数据页数。 | 节点 |
| PhysicalMemorySize | long | 内存中分配的空间大小(字节)。 | 节点 |
| 操作 | 描述 |
|---|---|
| enableMetrics | 在运行时启用数据区的指标收集。 |
| disableMetrics | 禁用指标收集。 |
缓存组大小
如果不使用缓存组,则每个缓存将属于其自己的组。每个缓存组都有一个单独的JMX Bean,Bean的名称与组的名称相对应。
| 属性 | 类型 | 描述 | 作用域 |
|---|---|---|---|
| TotalAllocatedSize | long | 分配给该缓存组的空间大小(字节)。 | 节点 |
# 4.1.5.2.检查点操作监控
检查点可能会拖慢集群的操作,因此可能需要监控每个检查点操作花费多少时间,以便可以调整影响检查点的属性。可能还需要监控磁盘性能,以查看速度下降是否是由外部原因引起的。
| 属性 | 类型 | 描述 | 作用域 |
|---|---|---|---|
| DirtyPages | long | 内存中已更改但尚未同步到磁盘的页面数。这些将在下一个检查点期间写入磁盘。 | 节点 |
| LastCheckpointDuration | long | 最后一次检查点花费时间(毫秒)。 | 节点 |
| CheckpointBufferSize | long | 检查点缓冲区大小。 | 全局 |
# 4.1.5.3.再平衡监控
再平衡是在集群节点之间移动分区以使数据始终平衡分布的过程,当新节点加入或现有节点离开集群时,将触发再平衡。
如果有多个缓存,则会按顺序平衡数据,某个缓存再平衡过程的进度可以通过几个指标来监控。
在新的指标系统中,可以参见缓存指标:
| 属性 | 类型 | 描述 | 作用域 |
|---|---|---|---|
| RebalancingStartTime | long | 该指标为缓存再平衡本地分区的开始时间(毫秒)。如果本地分区不参与再平衡,则该指标将返回0。 | 节点 |
| EstimatedRebalancingFinishTime | long | 再平衡过程预计完成时间。 | 节点 |
| KeysToRebalanceLeft | long | 待平衡的键数量,可根据该指标了解再平衡过程何时结束。 | 节点 |
# 4.1.5.4.拓扑监控
拓扑是指集群中的节点集。有许多指标可以显示有关集群拓扑的信息。如果拓扑更改得太频繁或其大小与预期值不同,则可能要调查是否存在网络问题。
| 属性 | 类型 | 描述 | 作用域 |
|---|---|---|---|
| TotalServerNodes | long | 集群中服务端节点数。 | 全局 |
| TotalClientNodes | long | 集群中客户端节点数。 | 全局 |
| TotalBaselineNodes | long | 基线拓扑中的注册节点数。当一个节点故障时,它在拓扑中仍是注册状态,用户需要手动对其进行远程管理。 | 全局 |
| ActiveBaselineNodes | long | 基线拓扑中的当前在线节点数。 | 全局 |
| 属性 | 类型 | 描述 | 作用域 |
|---|---|---|---|
| Coordinator | String | 当前协调器节点的节点ID。 | 全局 |
| CoordinatorNodeFormatted | String | 有关协调器节点的详细信息。 | 全局 |
# 4.1.5.5.缓存监控
请参见新指标系统中的缓存指标。
索引创建和重建监控
要估算重建缓存索引所需的时间,可以使用下列的指标之一:
IsIndexRebuildInProgress:当前索引是否正在创建或者重建;IndexBuildCountPartitionsLeft:索引重建的剩余分区数(按分区组);
注意,IndexBuildCountPartitionsLeft指标仅允许估计要重建的大约剩余索引数。要获得更准确的估计,需使用IndexRebuildKeyProcessed缓存指标:
isIndexRebuildInProgress,该指标可以知道某缓存的索引是否正在重建;IndexRebuildKeysProcessed,该指标可以知道重建索引已处理的键数量。如果正在重建过程中,它会给出当前重建索引已处理的键数量,否则会给出重建索引的键总数。该值每次重建开始之前会被重置。
# 4.1.5.6.事务监控
注意,如果事务跨越多个节点(即如果由于事务执行而更改的键位于多个节点上),则每个节点上的计数器都会增加。例如,“TransactionsCommittedNumber”计数器将在存储受事务影响的键的每个节点上增加。
| 属性 | 类型 | 描述 | 作用域 |
|---|---|---|---|
| LockedKeysNumber | long | 该节点锁定的键数量。 | 节点 |
| TransactionsCommittedNumber | long | 该节点已提交的事务数。 | 节点 |
| TransactionsRolledBackNumber | long | 已回滚事务数。 | 节点 |
| OwnerTransactionsNumber | long | 该节点发起事务数。 | 节点 |
| TransactionsHoldingLockNumber | long | 节点上至少一个键上有锁的打开事务数。 | 节点 |
# 4.1.5.7.客户端连接监控
与JDBC/ODBC/瘦客户端连接有关的指标。
| 属性 | 类型 | 描述 | 作用域 |
|---|---|---|---|
| Connections | java.util.List<String> | 字符串列表,每个字符串都包含了和连接有关的信息。 | 节点 |
# 4.1.5.8.消息队列监控
当线程池队列不断增长时,意味着节点无法跟上负载,或者在处理队列中的消息时出错。队列大小的持续增长会导致OOM错误。
通信消息队列
出站通信消息队列包含正在等待发送到其他节点的通信消息。如果大小不断增加,则说明存在问题。
| 属性 | 类型 | 描述 | 作用域 |
|---|---|---|---|
| OutboundMessagesQueueSize | int | 出站通信消息队列大小。 | 节点 |
发现消息队列
发现消息队列。
| 属性 | 类型 | 描述 | 作用域 |
|---|---|---|---|
| MessageWorkerQueueSize | int | 等待发送到其他节点的发现消息队列的大小。 | 节点 |
| AvgMessageProcessingTime | long | 平均消息处理时间。 | 节点 |
# 4.2.配置指标
指标收集不是一项无代价操作,可能会影响应用的性能。因此默认情况下会禁用某些指标。
# 4.2.1.启用缓存指标
缓存指标显示有关缓存中存储的数据量,缓存操作的总数和频率等的统计信息,以及一些其他的缓存配置属性。
要启用缓存指标,对要监控的每个缓存使用下面介绍的一种方法:
# 4.2.2.启用数据区指标
数据区指标暴露了数据区的有关信息,包括数据区的内存和存储大小,需要收集哪个数据区的信息,就为哪个数据区开启指标收集。
数据区指标可以通过2种方式启用:
- 在数据区的配置中;
- 通过JMX Beans。
下面的示例演示了如何为默认的数据区和一个自定义数据区开启指标收集:
# 4.2.3.启用持久化相关指标
持久化相关的指标可以通过数据存储的配置启用/禁用:
# 4.3.指标
本章节介绍指标注册表(分类)以及每个注册表中的可用指标。
# 4.3.1.系统
注册表名:sys。
| 名称 | 类型 | 描述 |
|---|---|---|
CpuLoad | double | CPU负载 |
CurrentThreadCpuTime | long | ThreadMXBean#getCurrentThreadCpuTime() |
CurrentThreadUserTime | long | ThreadMXBean#getCurrentThreadUserTime() |
DaemonThreadCount | Integer | ThreadMXBean#getDaemonThreadCount() |
GcCpuLoad | double | GC的CPU负载 |
PeakThreadCount | Integer | ThreadMXBean#getPeakThreadCount() |
SystemLoadAverage | java.lang.Double | OperatingSystemMXBean#getSystemLoadAverage() |
ThreadCount | Integer | ThreadMXBean#getThreadCount() |
TotalExecutedTasks | long | 已执行任务总数 |
TotalStartedThreadCount | long | ThreadMXBean#getTotalStartedThreadCount() |
UpTime | long | RuntimeMxBean#getUptime() |
memory.heap.committed | long | MemoryUsage#getHeapMemoryUsage()#getCommitted() |
memory.heap.init | long | MemoryUsage#getHeapMemoryUsage()#getInit() |
memory.heap.used | long | MemoryUsage#getHeapMemoryUsage()#getUsed() |
memory.nonheap.committed | long | MemoryUsage#getNonHeapMemoryUsage()#getCommitted() |
memory.nonheap.init | long | MemoryUsage#getNonHeapMemoryUsage()#getInit() |
memory.nonheap.max | long | MemoryUsage#getNonHeapMemoryUsage()#getMax() |
memory.nonheap.used | long | MemoryUsage#getNonHeapMemoryUsage()#getUsed() |
# 4.3.2.缓存
注册表名:cache.{cache_name}.{near}
| 名称 | 类型 | 描述 |
|---|---|---|
CacheEvictions | long | 缓存的退出的总数 |
CacheGets | long | 缓存的读取总数 |
CacheHits | long | 缓存的命中总数 |
CacheMisses | long | 缓存的未命中总数 |
CachePuts | long | 缓存的写入总数 |
CacheRemovals | long | 缓存的删除总数 |
CacheTxCommits | long | 缓存的事务提交总数 |
CacheTxRollbacks | long | 缓存的事务回滚总数 |
CacheSize | long | 本地缓存大小 |
CommitTime | histogram | 提交时间(纳秒) |
CommitTimeTotal | long | 提交时间总数(纳秒) |
EntryProcessorHits | long | 缓存中存在的键调用总数 |
EntryProcessorInvokeTimeNanos | long | 此节点作为发起方的缓存调用总时间(纳秒) |
EntryProcessorMaxInvocationTime | long | 到目前为止此节点作为发起方的缓存调用的最长时间(纳秒) |
EntryProcessorMinInvocationTime | long | 到目前为止此节点作为发起方的缓存调用的最短时间(纳秒) |
EntryProcessorMisses | long | 缓存中不存在的键调用总数 |
EntryProcessorPuts | long | 触发更新的缓存调用总数 |
EntryProcessorReadOnlyInvocations | long | 不触发更新的缓存调用总数 |
EntryProcessorRemovals | long | 触发删除的缓存调用总数 |
EstimatedRebalancingKeys | long | 预估的再平衡键数量 |
GetAllTime | histogram | 此节点作为发起方的全部读取时间(纳秒) |
GetTime | histogram | 此节点作为发起方的读取时间(纳秒) |
GetTimeTotal | long | 此节点作为发起方的缓存读取总时间(纳秒) |
HeapEntriesCount | long | 堆内缓存数 |
IndexRebuildKeysProcessed | long | 索引重建期间已处理的键数量 |
IsIndexRebuildInProgress | boolean | 如果索引在创建或重建过程中则为true |
OffHeapBackupEntriesCount | long | 堆外备份条目总数 |
OffHeapEntriesCount | long | 堆外条目总数 |
OffHeapEvictions | long | 堆外内存退出总量 |
OffHeapGets | long | 堆外内存读取请求总数 |
OffHeapHits | long | 堆外内存读取请求命中总数 |
OffHeapMisses | long | 堆外内存读取请求未命中总数 |
OffHeapPrimaryEntriesCount | long | 堆外主条目总数 |
OffHeapPuts | long | 堆外内存写入请求总数 |
OffHeapRemovals | long | 堆外内存删除总数 |
PutAllTime | histogram | 此节点作为发起方的全部写入时间(纳秒) |
PutTime | histogram | 此节点作为发起方的写入时间(纳秒) |
PutTimeTotal | long | 此节点作为发起方的缓存写入总时间(纳秒) |
QueryCompleted | long | 查询完成数 |
QueryExecuted | long | 查询执行数 |
QueryFailed | long | 查询失败数 |
QueryMaximumTime | long | 查询最长执行时间 |
QueryMinimalTime | long | 查询最短执行时间 |
QuerySumTime | long | 查询总时间 |
RebalanceClearingPartitionsLeft | long | 再平衡实际开始前需要清理的分区数 |
RebalanceStartTime | long | 再平衡开始时间 |
RebalancedKeys | long | 已再平衡的键数量 |
RebalancingBytesRate | long | 预估的再平衡速度(字节) |
RebalancingKeysRate | long | 预估的再平衡速度(键数量) |
RemoveAllTime | histogram | 此节点作为发起方的全部删除时间(纳秒) |
RemoveTime | histogram | 此节点作为发起方的删除时间(纳秒) |
RemoveTimeTotal | long | 此节点作为发起方的缓存删除总时间(纳秒) |
RollbackTime | histogram | 回滚时间(纳秒) |
RollbackTimeTotal | long | 回滚总时间(纳秒) |
TotalRebalancedBytes | long | 已再平衡字节数 |
# 4.3.3.缓存组
注册表名:cacheGroups.{group_name}
| 名称 | 类型 | 描述 |
|---|---|---|
AffinityPartitionsAssignmentMap | java.util.Collections$EmptyMap | 映射分区分配哈希表 |
Caches | java.util.ArrayList | 缓存列表 |
IndexBuildCountPartitionsLeft | long | 完成索引创建或重建所需处理的分区数 |
LocalNodeMovingPartitionsCount | Integer | 该缓存组在本地节点上状态为MOVING的分区数 |
LocalNodeOwningPartitionsCount | Integer | 该缓存组在本地节点上状态为OWNING的分区数 |
LocalNodeRentingEntriesCount | long | 该缓存组在本地节点上的状态为RENTING的分区中要退出的数据量 |
LocalNodeRentingPartitionsCount | Integer | 该缓存组在本地节点上的状态为RENTING的分区数 |
MaximumNumberOfPartitionCopies | Integer | 该缓存组中的所有分区的最大分区副本数 |
MinimumNumberOfPartitionCopies | Integer | 该缓存组中的所有分区的最小分区副本数 |
MovingPartitionsAllocationMap | java.util.Collections$EmptyMap | 集群中状态为MOVING的分区的分配哈希表 |
OwningPartitionsAllocationMap | java.util.Collections$EmptyMap | 集群中状态为OWNING的分区的分配哈希表 |
PartitionIds | java.util.ArrayList | 本地分区ID列表 |
SparseStorageSize | long | 组分配的存储空间,针对可能的稀疏性进行了调整(字节) |
StorageSize | long | 为缓存组分配的存储空间(字节) |
TotalAllocatedPages | long | 为缓存组分配的页面总数 |
TotalAllocatedSize | long | 为缓存组分配的内存总大小(字节) |
ReencryptionBytesLeft | long | 为重新加密保留的字节数 |
ReencryptionFinished | boolean | 重新加密是否完成标志 |
# 4.3.4.事务
注册表名:tx
| 名称 | 类型 | 描述 |
|---|---|---|
AllOwnerTransactions | java.util.HashMap | 本地节点持有的事务哈希表 |
LockedKeysNumber | long | 当前节点锁定的键数量 |
OwnerTransactionsNumber | long | 当前节点发起的正在运行的事务数 |
TransactionsHoldingLockNumber | long | 至少锁定一个键的正在运行的事务数 |
LastCommitTime | long | 上次提交时间 |
nodeSystemTimeHistogram | histogram | 以直方图表示的节点事务系统时间 |
nodeUserTimeHistogram | histogram | 以直方图表示的节点事务用户时间 |
LastRollbackTime | long | 上次回滚时间 |
totalNodeSystemTime | long | 节点的事务系统总时间 |
totalNodeUserTime | long | 节点的事务用户总时间 |
txCommits | Integer | 提交事务数 |
txRollbacks | Integer | 回滚事务数 |
# 4.3.5.分区映射交换
注册表名:pme
| 名称 | 类型 | 描述 |
|---|---|---|
CacheOperationsBlockedDuration | long | 当前的PME过程缓存操作阻塞时间(毫秒) |
CacheOperationsBlockedDurationHistogram | histogram | 当前的PME过程缓存操作阻塞直方图(毫秒) |
Duration | long | 当前的PME持续时间(毫秒) |
DurationHistogram | histogram | 当前的PME持续直方图(毫秒) |
# 4.3.6.计算作业
注册表名:compute.jobs
| 名称 | 类型 | 描述 |
|---|---|---|
compute.jobs.Active | long | 当前正在执行的活动作业数 |
compute.jobs.Canceled | long | 仍在运行的已取消作业数 |
compute.jobs.ExecutionTime | long | 作业的总执行时间 |
compute.jobs.Finished | long | 已完成作业数 |
compute.jobs.Rejected | long | 在最近的冲突解决操作之后,拒绝的作业数 |
compute.jobs.Started | long | 已开始作业数 |
compute.jobs.Waiting | long | 当前等待执行的排队作业数 |
compute.jobs.WaitingTime | long | 作业在等待队列上花费的总时间 |
# 4.3.7.线程池
注册表名:threadPools.{thread_pool_name}
| 名称 | 类型 | 描述 |
|---|---|---|
ActiveCount | long | 正在执行任务的线程的近似数量 |
CompletedTaskCount | long | 已完成执行的任务近似总数 |
CorePoolSize | long | 核心线程数 |
KeepAliveTime | long | 线程保持活动时间,即超过核心线程池大小的线程在被终止之前可能保持空闲的时间 |
LargestPoolSize | long | 线程池中的并发最大线程数 |
MaximumPoolSize | long | 最大允许线程数 |
PoolSize | long | 线程池当前线程数 |
QueueSize | long | 当前执行队列大小 |
RejectedExecutionHandlerClass | String | 当前拒绝处理器类名 |
Shutdown | boolean | 如果该执行器已关闭则为true |
TaskCount | long | 已计划执行的任务近似总数 |
TaskExecutionTime | histogram | 任务执行时间(毫秒) |
Terminated | boolean | 如果关闭后所有任务都已完成则为true |
Terminating | long | 如果终止但尚未终止则为true |
ThreadFactoryClass | String | 用于创建新线程的线程工厂类名 |
# 4.3.8.缓存组IO
注册表名:io.statistics.cacheGroups.{group_name}
| 名称 | 类型 | 描述 |
|---|---|---|
LOGICAL_READS | long | 逻辑读数量 |
PHYSICAL_READS | long | 物理读数量 |
grpId | Integer | 组ID |
name | String | 索引名 |
startTime | long | 统计数据收集开始时间 |
# 4.3.9.有序索引IO统计
注册表名:io.statistics.sortedIndexes.{cache_name}.{index_name}
| 名称 | 类型 | 描述 |
|---|---|---|
LOGICAL_READS_INNER | long | 内部树节点的逻辑读取数 |
LOGICAL_READS_LEAF | long | 末端树节点的逻辑读取数 |
PHYSICAL_READS_INNER | long | 内部树节点的物理读取数 |
PHYSICAL_READS_LEAF | long | 末端树节点的物理读取数 |
indexName | String | 索引名 |
name | String | 缓存名 |
startTime | long | 统计数据收集开始时间 |
# 4.3.10.有序索引操作
包含有关有序二级索引页上的低级操作(如插入、搜索等)的指标。
注册表名:index.{schema_name}.{table_name}.{index_name}
| 名称 | 类型 | 描述 |
|---|---|---|
{opType}Count | long | 索引上{opType}操作的数量 |
{opType}Time | long | 索引上{opType}操作的总时间(纳秒) |
# 4.3.11.哈希索引IO统计
注册表名:io.statistics.hashIndexes.{cache_name}.{index_name}
| 名称 | 类型 | 描述 |
|---|---|---|
LOGICAL_READS_INNER | long | 内部树节点的逻辑读取数 |
LOGICAL_READS_LEAF | long | 末端树节点的逻辑读取数 |
PHYSICAL_READS_INNER | long | 内部树节点的物理读取数 |
PHYSICAL_READS_LEAF | long | 末端树节点的物理读取数 |
indexName | String | 索引名 |
name | String | 缓存名 |
startTime | long | 统计数据收集开始时间 |
# 4.3.12.通信IO
注册表名:io.communication
| 名称 | 类型 | 描述 |
|---|---|---|
ActiveSessionsCount | Integer | 在线TCP会话数 |
OutboundMessagesQueueSize | Integer | 出站消息队列大小 |
SentMessagesCount | Integer | 发送消息数量 |
SentBytesCount | long | 发送字节数 |
ReceivedBytesCount | long | 接收字节数 |
ReceivedMessagesCount | Integer | 接收消息数量 |
RejectedSslSessionsCount | Integer | 由于SSL错误而被拒绝的TCP会话数(仅当启用SSL时才会导出该指标) |
SslEnabled | Boolean | 是否启用SSL |
SslHandshakeDurationHistogram | histogram | SSL握手持续时间的直方图(毫秒)(仅当启用SSL时才会导出该指标) |
# 4.3.13.瘦客户端连接
注册表名:client.connector
| 名称 | 类型 | 描述 |
|---|---|---|
ActiveSessionsCount | integer | 在线TCP会话数 |
ReceivedBytesCount | long | 接收字节数 |
RejectedSslSessionsCount | integer | 由于SSL错误而被拒绝的TCP会话数(仅当启用SSL时才会导出该指标) |
RejectedSessionsTimeout | integer | 由于握手超时而被拒绝的TCP会话计数 |
RejectedSessionsAuthenticationFailed | integer | 由于身份验证失败而被拒绝的TCP会话计数 |
RejectedSessionsTotal | integer | 被拒绝的TCP连接总数 |
{clientType}.AcceptedSessions | integer | 为某客户端类型成功建立的会话数 |
{clientType}.ActiveSessions | integer | 某客户端类型的在线会话数 |
SentBytesCount | long | 发送字节数 |
SslEnabled | boolean | 是否启用SSL |
SslHandshakeDurationHistogram | histogram | SSL握手持续时间的直方图(毫秒)(仅当启用SSL时才会导出该指标) |
AffinityKeyRequestsHits | long | 发给主节点的具有分区感知的缓存数据量 |
AffinityKeyRequestsMisses | long | 未发给主节点的具有分区感知的缓存数据量 |
AffinityQueryRequestsHits | long | 发给主节点的具有分区感知的查询请求数 |
AffinityQueryRequestsMisses | long | 未发给主节点的具有分区感知的查询请求数 |
# 4.3.14.REST客户端连接
注册表名:rest.client
| 名称 | 类型 | 描述 |
|---|---|---|
ActiveSessionsCount | integer | 在线TCP会话数 |
ReceivedBytesCount | long | 接收字节数 |
RejectedSslSessionsCount | integer | 由于SSL错误而被拒绝的TCP会话数(仅当启用SSL时才会导出该指标) |
SentBytesCount | long | 发送字节数 |
SslEnabled | boolean | 是否启用SSL |
SslHandshakeDurationHistogram | histogram | SSL握手持续时间的直方图(毫秒)(仅当启用SSL时才会导出该指标) |
# 4.3.15.发现IO
注册表名:io.discovery
| 名称 | 类型 | 描述 |
|---|---|---|
CoordinatorSince | long | 从本地节点成为协调器节点开始的时间戳(仅限服务端节点) |
Coordinator | UUID | 协调器ID(仅限服务端节点) |
CurrentTopologyVersion | long | 当前拓扑版本 |
JoinedNodes | integer | 已加入节点数 |
LeftNodes | integer | 离开节点数 |
MessageWorkerQueueSize | integer | 当前消息工作节点队列大小 |
PendingMessagesRegistered | integer | 挂起的已注册消息数 |
RejectedSslConnectionsCount | integer | 由于SSL错误被拒绝的TCP发现连接数 |
SslEnabled | boolean | 是否启用SSL |
TotalProcessedMessages | integer | 已处理消息总数 |
TotalReceivedMessages | integer | 已接收消息总数 |
# 4.3.16.数据区IO
注册表名:io.dataregion.{data_region_name}
| 名称 | 类型 | 描述 |
|---|---|---|
AllocationRate | hitrate | rateTimeInternal期间的平均分配率(每秒页面数) |
CheckpointBufferSize | long | 检查点缓冲区大小(字节) |
DirtyPages | long | 内存中还没有同步到持久化存储的页面数 |
EmptyDataPages | long | 计算数据区中的空页面数,它只计算可重用的完全空闲的页面(比如包含在空闲列表的可重用桶中的页面) |
EvictionRate | hitrate | 退出率(每秒页面数) |
LargeEntriesPagesCount | long | 完全被超过页面大小的大条目占用的页面数 |
OffHeapSize | long | 堆外内存大小(字节) |
OffheapUsedSize | long | 堆外内存已使用大小(字节) |
PagesFillFactor | double | 已用空间的百分比 |
PagesRead | long | 上次重启以来的页面读取数 |
PagesReplaceAge | hitrate | 内存中的页面被持久化存储中的页面替换的平均期限(毫秒) |
PagesReplaceRate | hitrate | 内存中的页面被持久化存储中的页面替换的速率(每秒页面数) |
PagesReplaced | long | 从上次重启以来的页面替换数 |
PagesWritten | long | 从上次重启以来的页面写入数 |
PhysicalMemoryPages | long | 物理内存中驻留的页面数 |
PhysicalMemorySize | long | 加载到内存中的页面总大小(字节) |
TotalAllocatedPages | long | 分配的页面总数 |
TotalAllocatedSize | long | 数据区中分配的页面总大小(字节) |
TotalThrottlingTime | long | 限流线程总时间(毫秒),Ignite会限制在检查点执行过程中生成脏页面的线程 |
UsedCheckpointBufferSize | long | 已使用的检查点缓冲区大小(字节) |
# 4.3.17.数据存储
注册表名:io.datastorage
| 名称 | 类型 | 描述 |
|---|---|---|
CheckpointBeforeLockHistogram | histogram | 执行写锁定持续时间(毫秒)之前的检查点操作的直方图 |
CheckpointFsyncHistogram | histogram | 检查点全同步持续时间(毫秒)的直方图 |
CheckpointHistogram | histogram | 检查点持续时间(毫秒)的直方图 |
CheckpointListenersExecuteHistogram | histogram | 写锁定持续时间(毫秒)下检查点执行监听器的直方图 |
CheckpointLockHoldHistogram | histogram | 检查点锁定保持持续时间(毫秒)的直方图 |
CheckpointLockWaitHistogram | histogram | 检查点锁定等待持续时间(毫秒)的直方图 |
CheckpointMarkHistogram | histogram | 检查点标记持续时间(毫秒)的直方图 |
CheckpointPagesWriteHistogram | histogram | 检查点页面写入持续时间(毫秒)的直方图 |
CheckpointSplitAndSortPagesHistogram | histogram | 分割和排序检查点页面持续时间(毫秒)的直方图 |
CheckpointTotalTime | long | 检查点总时间 |
LastCheckpointCopiedOnWritePagesNumber | long | 上次检查点过程复制到临时检查点缓冲区的页面数 |
LastCheckpointDataPagesNumber | long | 上次检查点过程的数据页面写入数 |
LastCheckpointDuration | long | 上次检查点过程的持续时间(毫秒) |
LastCheckpointFsyncDuration | long | 上次检查点过程的同步阶段的持续时间(毫秒) |
LastCheckpointListenersExecuteDuration | long | 写锁定下检查点执行监听器的持续时间(毫秒) |
LastCheckpointLockHoldDuration | long | 检查点锁定保持的持续时间(毫秒) |
LastCheckpointLockWaitDuration | long | 上次检查点过程的锁等待时间(毫秒) |
LastCheckpointMarkDuration | long | 上次检查点过程的标记时间(毫秒) |
LastCheckpointPagesWriteDuration | long | 上次检查点过程的页面写入时间(毫秒) |
LastCheckpointTotalPagesNumber | long | 上次检查点过程的页面写入总数 |
LastCheckpointSplitAndSortPagesDuration | long | 拆分和排序上次检查点的检查点页面的持续时间(毫秒) |
LastCheckpointStart | long | 最后一个检查点的开始时间戳 |
LastCheckpointWalRecordFsyncDuration | long | 在上次检查点的开始处记录CheckpointRecord后WAL全同步的持续时间(毫秒) |
LastCheckpointWriteEntryDuration | long | 上次检查点中条目缓冲区写入文件的持续时间(毫秒) |
SparseStorageSize | long | 为可能的稀疏性而调整的已分配存储空间(字节) |
StorageSize | long | 分配的存储空间(字节) |
WalArchiveSegments | Integer | 当前WAL存档中的WAL段数量 |
WalBuffPollSpinsRate | hitrate | WAL缓冲区轮询在上一个时间间隔内的自旋数 |
WalFsyncTimeDuration | hitrate | FSYNC模式持续时间 |
WalFsyncTimeNum | long | FSYNC模式总数量 |
WalLastRollOverTime | long | 上一次WAL段翻转时间 |
WalLoggingRate | hitrate | 上一个时间间隔内WAL记录的每秒平均写入量 |
WalTotalSize | long | WAL文件存储总大小(字节) |
WalWritingRate | hitrate | 上一个时间间隔内WAL的每秒平均写入字节数 |
# 4.3.18.集群
注册表名:cluster
| 名称 | 类型 | 描述 |
|---|---|---|
ActiveBaselineNodes | Integer | 在线基线节点总数 |
Rebalanced | boolean | 如果集群已完全达到平衡状态,则为True。注意无论实际分区状态如何,非激活集群的此度量值始终为False |
TotalBaselineNodes | Integer | 基线节点总数 |
TotalClientNodes | Integer | 客户端节点总数 |
TotalServerNodes | Integer | 服务端节点总数 |
# 4.3.19.缓存处理器
注册表名:cache
| 名称 | 类型 | 描述 |
|---|---|---|
LastDataVer | long | 节点的最新数据版本 |
DataVersionClusterId | integer | 数据版本集群ID |
# 4.3.20.SQL解析器
注册表名:sql.parser.cache
| 名称 | 类型 | 描述 |
|---|---|---|
hits | long | 在解析器缓存中找到的SQL查询数(执行前不需要解析和计划) |
misses | long | 执行解析和计划的SQL查询数量 |
# 4.3.21.SQL执行器
注册表名:sql.queries.user
| 名称 | 类型 | 描述 |
|---|---|---|
success | long | 执行成功的SQL查询数 |
failed | long | 执行失败的SQL查询数(包括取消的数量) |
canceled | long | 取消的SQL查询数 |
# 5.系统视图
警告
系统视图是一个试验性特性,未来的版本可能会发生变更。
Ignite提供了许多内置SQL视图,他们包含有关集群节点和节点指标的信息。这些视图在SYS模式中。有关如何访问非默认模式的信息,请参见理解模式章节的内容。
限制
- 无法在SYS模式中创建对象;
- SYS模式中的系统视图无法与用户表相关联。
# 5.1.查询系统视图
使用SQLLine工具可以查询系统视图。
./sqlline.sh -u jdbc:ignite:thin://127.0.0.1/SYS
如果节点运行在远程服务器上,需要将127.0.0.1改成实际的服务器地址。
执行一个查询:
-- get the list of nodes
select * from NODES;
-- view the CPU load as a percentage for a specific node
select CUR_CPU_LOAD * 100 from NODE_METRICS where NODE_ID = 'a1b77663-b37f-4ddf-87a6-1e2d684f3bae'
使用Java瘦客户端的同一个示例:
ClientConfiguration cfg = new ClientConfiguration().setAddresses("127.0.0.1:10800");
try (IgniteClient igniteClient = Ignition.startClient(cfg)) {
// getting the id of the first node
UUID nodeId = (UUID) igniteClient.query(new SqlFieldsQuery("SELECT * from NODES").setSchema("IGNITE"))
.getAll().iterator().next().get(0);
double cpu_load = (Double) igniteClient
.query(new SqlFieldsQuery("select CUR_CPU_LOAD * 100 from NODE_METRICS where NODE_ID = ? ")
.setSchema("IGNITE").setArgs(nodeId.toString()))
.getAll().iterator().next().get(0);
System.out.println("node's cpu load = " + cpu_load);
} catch (ClientException e) {
System.err.println(e.getMessage());
} catch (Exception e) {
System.err.format("Unexpected failure: %s\n", e);
}
系统视图也可以通过控制脚本的系统视图命令进行查询,注意该命令结果包含请求的系统视图的所有列。如果需要过滤,则应手动执行,示例如下:
# 5.2.CACHES
| 列名 | 类型 | 描述 |
|---|---|---|
CACHE_NAME | String | 缓存名 |
CACHE_ID | int | 缓存ID |
CACHE_TYPE | String | 缓存类型 |
CACHE_MODE | String | 缓存模式 |
ATOMICITY_MODE | String | 原子化模式 |
CACHE_GROUP_NAME | String | 缓存组名 |
AFFINITY | String | 关联函数的toString表示 |
AFFINITY_MAPPER | String | 关联映射器的toString表示 |
BACKUPS | int | 备份数 |
CACHE_GROUP_ID | int | 缓存组ID |
CACHE_LOADER_FACTORY | String | 缓存加载器工厂的toString表示 |
CACHE_STORE_FACTORY | String | 缓存存储器工厂的toString表示 |
CACHE_WRITER_FACTORY | String | 缓存写入器工厂的toString表示 |
DATA_REGION_NAME | String | 数据区名 |
DEFAULT_LOCK_TIMEOUT | long | 锁超时(毫秒) |
EVICTION_FILTER | String | 退出过滤器的toString表示 |
EVICTION_POLICY_FACTORY | String | 退出策略工厂的toString表示 |
EXPIRY_POLICY_FACTORY | String | 过期策略工厂的toString表示 |
CONFLICT_RESOLVER | String | 缓存冲突解析器的toString表示 |
INTERCEPTOR | String | 拦截器的toString表示 |
IS_COPY_ON_READ | boolean | 缓存值副本是否保存在堆内的标志 |
IS_EAGER_TTL | boolean | 是否立即从缓存中删除过期数据的标志 |
IS_ENCRYPTION_ENABLED | boolean | 缓存数据开启加密则为true |
IS_EVENTS_DISABLED | boolean | 缓存事件禁用则为true |
IS_INVALIDATE | boolean | 如果值在近缓存中提交时无效(为空),则为true |
IS_LOAD_PREVIOUS_VALUE | boolean | 如果值在缓存中不存在时应该从存储中加载,则为true |
IS_MANAGEMENT_ENABLED | boolean | |
IS_NEAR_CACHE_ENABLED | boolean | 开启近缓存则为true |
IS_ONHEAP_CACHE_ENABLED | boolean | 开启堆内缓存则为true |
IS_READ_FROM_BACKUP | boolean | 如果开启从备份读则为true |
IS_READ_THROUGH | boolean | 如果开启通读则为true |
IS_SQL_ESCAPE_ALL | boolean | 如果所有的表名和字段名都用双引号转义则为true |
IS_SQL_ONHEAP_CACHE_ENABLED | boolean | 如果堆内缓存SQL开启则为true,开启时,查询引擎可以访问缓存的SQL数据,当相关的缓存数据发生变更或者退出时,这些数据也会失效退出 |
IS_STATISTICS_ENABLED | boolean | |
IS_STORE_KEEP_BINARY | boolean | 缓存存储实现处理二进制对象而不是Java对象的标志 |
IS_WRITE_BEHIND_ENABLED | boolean | 缓存存储开启后写模式标志 |
IS_WRITE_THROUGH | boolean | 如果开启通写则为true |
MAX_CONCURRENT_ASYNC_OPERATIONS | int | 允许的最大并发异步操作数,如果为0,则不受限制 |
MAX_QUERY_ITERATORS_COUNT | int | 可以存储的查询迭代器的最大值,当每页数据按需发给用户端时,存储迭代器用于支持查询分页 |
NEAR_CACHE_EVICTION_POLICY_FACTORY | String | 近缓存退出策略工厂的toString表示 |
NEAR_CACHE_START_SIZE | int | 启动后将用于预创建内部哈希表的近缓存初始缓存大小 |
NODE_FILTER | String | 节点过滤器NodeFilter实现的toString表示 |
PARTITION_LOSS_POLICY | String | 分区丢失策略的toString表示 |
QUERY_DETAIL_METRICS_SIZE | int | 用于监控目的在内存中存储的查询详细指标的大小,如果为0则不会收集历史记录 |
QUERY_PARALLELISM | int | 单节点查询并行度的查询执行引擎提示 |
REBALANCE_BATCH_SIZE | int | 单次再平衡消息大小(字节) |
REBALANCE_BATCHES_PREFETCH_COUNT | int | 再平衡开始时节点生成的批次数 |
REBALANCE_DELAY | long | 再平衡延迟时间(毫秒) |
REBALANCE_MODE | String | 再平衡模式 |
REBALANCE_ORDER | int | 再平衡顺序 |
REBALANCE_THROTTLE | long | 为了避免CPU和网络的过载,再平衡消息之间的等待时间(毫秒) |
REBALANCE_TIMEOUT | long | 再平衡超时(毫米) |
SQL_INDEX_MAX_INLINE_SIZE | int | 索引内联大小(字节) |
SQL_ONHEAP_CACHE_MAX_SIZE | int | SQL堆内缓存最大值,以行数计算,当到达最大值时最早的数据会被退出 |
SQL_SCHEMA | String | 模式名 |
TOPOLOGY_VALIDATOR | String | 拓扑验证器的toString表示 |
WRITE_BEHIND_BATCH_SIZE | int | 后写缓存的缓存操作批次大小 |
WRITE_BEHIND_COALESCING | boolean | 后写缓存存储操作的写合并标志。将具有相同键的存储操作(get或remove)组合或合并为单个操作,从而减少对底层缓存存储的压力 |
WRITE_BEHIND_FLUSH_FREQUENCY | long | 后写缓存将数据刷新到底层存储的频率(毫秒) |
WRITE_BEHIND_FLUSH_SIZE | int | 后写缓存刷新数据大小,如果缓存数据量达到该值,所有的后写缓存数据都会刷新到底层存储,然后后写缓存会被清空 |
WRITE_BEHIND_FLUSH_THREAD_COUNT | int | 执行后写缓存刷新的线程数 |
WRITE_SYNCHRONIZATION_MODE | String | 写同步模式 |
# 5.3.CACHE_GROUPS
| 列名 | 数据类型 | 描述 |
|---|---|---|
CACHE_GROUP_NAME | String | 缓存组名 |
CACHE_COUNT | int | 缓存组中的缓存数 |
DATA_REGION_NAME | String | 存储缓存组中数据的数据区 |
CACHE_MODE | String | 默认缓存模式 |
ATOMICITY_MODE | String | 默认原子化模式 |
AFFINITY | String | 关联函数的toString表示 |
BACKUPS | int | 备份数 |
CACHE_GROUP_ID | int | 缓存组ID |
IS_SHARED | boolean | 缓存组为共享模式则为true |
NODE_FILTER | String | 节点过滤器NodeFilter的toString表示 |
PARTITION_LOSS_POLICY | String | 分区丢失策略的toString表示 |
PARTITIONS_COUNT | int | 分区数 |
REBALANCE_DELAY | long | 再平衡延迟时间(毫秒) |
REBALANCE_MODE | String | 再平衡模式 |
REBALANCE_ORDER | int | 再平衡组顺序 |
TOPOLOGY_VALIDATOR | String | 拓扑验证器的toString表示 |
# 5.4.TASKS
| 列名 | 数据类型 | 描述 |
|---|---|---|
AFFINITY_CACHE_NAME | String | 映射缓存名 |
AFFINITY_PARTITION_ID | int | 映射分区ID |
END_TIME | long | 结束时间 |
EXEC_NAME | String | 执行任务的线程池名 |
INTERNAL | boolean | 如果是内部任务则为true |
JOB_ID | UUID | 计算作业ID |
START_TIME | long | 启动时间 |
TASK_CLASS_NAME | String | 任务类名 |
TASK_NAME | String | 任务名 |
TASK_NODE_ID | UUID | 发起任务的节点ID |
USER_VERSION | String | 任务版本 |
# 5.5.JOBS
| 列名 | 数据类型 | 描述 |
|---|---|---|
ID | UUID | 作业ID |
SESSION_ID | UUID | 作业的会话ID,注意,对于作业所属的任务,SESSION_ID等于TASKS.SESSION_ID |
ORIGIN_NODE_ID | UUID | 发起作业的节点ID |
TASK_NAME | String | 任务名 |
TASK_CLASSNAME | String | 任务类名 |
AFFINITY_CACHE_IDS | String | 如果使用IgniteCompute.affinity...方法执行作业,则为一个或多个缓存的ID,如果使用的IgniteCompute API未关联某个缓存,则为空 |
AFFINITY_PARTITION_ID | int | 如果使用IgniteCompute.affinity...方法执行作业,则为一个或多个分区的ID,如果使用的IgniteCompute API未关联某分区,则为空 |
CREATE_TIME | long | 作业创建时间 |
START_TIME | long | 作业开始时间 |
FINISH_TIME | long | 作业完成时间 |
EXECUTOR_NAME | String | 任务执行器名 |
IS_FINISHING | boolean | 作业已完成则为true |
IS_INTERNAL | boolean | 如果为内部作业则为true |
IS_STARTED | boolean | 如果作业已启动则为true |
IS_TIMEDOUT | boolean | 如果作业在完成之前超时则为true |
STATE | String | 可能值:ACTIVE:作业正在执行;PASSIVE:将作业添加到执行队列;CANCELED:作业被取消 |
# 5.6.SERVICES
| 列名 | 数据类型 | 描述 |
|---|---|---|
SERVICE_ID | UUID | 服务ID |
NAME | String | 服务名 |
SERVICE_CLASS | String | 服务类名 |
CACHE_NAME | String | 缓存名 |
ORIGIN_NODE_ID | UUID | 发起方节点ID |
TOTAL_COUNT | int | 服务实例总数 |
MAX_PER_NODE_COUNT | int | 每节点最大服务数 |
AFFINITY_KEY | String | 服务的关联键值 |
NODE_FILTER | String | 节点过滤器NodeFilter的toString表示 |
STATICALLY_CONFIGURED | boolean | 服务配置为静态则为true |
# 5.7.TRANSACTIONS
| 列名 | 数据类型 | 描述 |
|---|---|---|
ORIGINATING_NODE_ID | UUID | |
STATE | String | |
XID | UUID | |
LABEL | String | |
START_TIME | long | |
ISOLATION | String | |
CONCURRENCY | String | |
KEYS_COUNT | int | |
CACHE_IDS | String | |
COLOCATED | boolean | |
DHT | boolean | |
DURATION | long | |
IMPLICIT | boolean | |
IMPLICIT_SINGLE | boolean | |
INTERNAL | boolean | |
LOCAL | boolean | |
LOCAL_NODE_ID | UUID | |
NEAR | boolean | |
ONE_PHASE_COMMIT | boolean | |
OTHER_NODE_ID | UUID | |
SUBJECT_ID | UUID | |
SYSTEM | boolean | |
THREAD_ID | long | |
TIMEOUT | long | |
TOP_VER | String |
# 5.8.NODES
| 列名 | 数据类型 | 描述 |
|---|---|---|
NODE_ID | UUID | 节点ID |
CONSISTENT_ID | String | 节点的一致性ID |
VERSION | String | 节点的版本 |
IS_CLIENT | boolean | 节点是否为客户端节点 |
NODE_ORDER | long | 节点在拓扑中的顺序 |
ADDRESSES | String | 节点的地址 |
HOSTNAMES | String | 节点的主机名 |
IS_LOCAL | boolean | 节点是否为本地节点 |
# 5.9.NODE_ATTRIBUTES
| 列名 | 数据类型 | 描述 |
|---|---|---|
NODE_ID | UUID | 节点ID |
NAME | String | 属性名 |
VALUE | String | 属性值 |
# 5.10.BASELINE_NODES
| 列名 | 数据类型 | 描述 |
|---|---|---|
CONSISTENT_ID | String | 节点一致性ID |
ONLINE | boolean | 节点的运行状态 |
# 5.11.BASELINE_NODE_ATTRIBUTES
| 列名 | 数据类型 | 描述 |
|---|---|---|
NODE_CONSISTENT_ID | VARCHAR | 节点一致性ID |
NAME | VARCHAR | 属性名 |
VALUE | VARCHAR | 属性值 |
# 5.12.CLIENT_CONNECTIONS
| 列名 | 数据类型 | 描述 |
|---|---|---|
CONNECTION_ID | long | 连接ID |
LOCAL_ADDRESS | IP地址 | 本地节点的IP地址 |
REMOTE_ADDRESS | IP地址 | 远程节点的IP地址 |
TYPE | String | 连接类型 |
USER | String | 用户名 |
VERSION | String | 协议版本 |
# 5.13.STRIPED_THREADPOOL_QUEUE
| 列名 | 数据类型 | 描述 |
|---|---|---|
STRIPE_INDEX | int | 平行线程的索引值 |
DESCRIPTION | String | 任务的toString表示 |
THREAD_NAME | String | 平行线程名 |
TASK_NAME | String | 任务类名 |
# 5.14.DATASTREAM_THREADPOOL_QUEUE
| 列名 | 数据类型 | 描述 |
|---|---|---|
STRIPE_INDEX | int | 平行线程索引值 |
DESCRIPTION | String | 任务的toString表示 |
THREAD_NAME | String | 平行线程名 |
TASK_NAME | String | 任务类名 |
# 5.15.SCAN_QUERIES
| 列名 | 数据类型 | 描述 |
|---|---|---|
ORIGIN_NODE_ID | UUID | 发起查询的节点ID |
QUERY_ID | long | 查询ID |
CACHE_NAME | String | 缓存名 |
CACHE_ID | int | 缓存ID |
CACHE_GROUP_ID | int | 缓存组ID |
CACHE_GROUP_NAME | String | 缓存组名 |
START_TIME | long | 查询开始时间 |
DURATION | long | 查询期限 |
CANCELED | boolean | 如果取消了则为true |
FILTER | String | 过滤器的toString表示 |
KEEP_BINARY | boolean | 如果开启了keepBinary则为true |
LOCAL | boolean | 如果仅为本地查询则为true |
PAGE_SIZE | int | 页面大小 |
PARTITION | int | 查询分区ID |
SUBJECT_ID | UUID | 发起查询的用户ID |
TASK_NAME | String | 任务名 |
TOPOLOGY | String | 拓扑版本 |
TRANSFORMER | String | 转换器的toString表示 |
# 5.16.CONTINUOUS_QUERIES
| 列名 | 数据类型 | 描述 |
|---|---|---|
CACHE_NAME | String | 缓存名 |
LOCAL_LISTENER | String | 本地监听器的toString表示 |
REMOTE_FILTER | String | 远程过滤器的toString表示 |
REMOTE_TRANSFORMER | String | 远程转换器的toString表示 |
LOCAL_TRANSFORMED_LISTENER | String | 本地转换监听器的toString表示 |
LAST_SEND_TIME | long | 事件批次上次发给持续查询发起节点的时间 |
AUTO_UNSUBSCRIBE | boolean | 当节点断开或发起节点离开时,如果持续查询应该停止,则为true |
BUFFER_SIZE | int | 事件批次缓冲区大小 |
DELAYED_REGISTER | boolean | 如果在相应缓存启动时就启动持续查询,则为true |
INTERVAL | long | 通知间隔时间 |
IS_EVENTS | boolean | 如果用于订阅远程事件则为true |
IS_MESSAGING | boolean | 如果用于订阅消息则为true |
IS_QUERY | boolean | 如果用户启动了持续查询则为true |
KEEP_BINARY | boolean | 如果开启了keepBinary则为true |
NODE_ID | UUID | 发起节点ID |
NOTIFY_EXISTING | boolean | 如果监听器应通知现有条目则为true |
OLD_VALUE_REQUIRED | boolean | 如果事件中应包含条目的旧值则为true |
ROUTINE_ID | UUID | 查询ID |
TOPIC | String | 查询主题名 |
# 5.17.SQL_QUERIES
| 列名 | 数据类型 | 描述 |
|---|---|---|
QUERY_ID | UUID | 查询ID |
SQL | String | 查询文本 |
ORIGIN_NODE_ID | UUID | 发起查询的节点ID |
START_TIME | date | 查询开始时间 |
DURATION | long | 查询执行期限 |
INITIATOR_ID | String | 用户定义的查询发起方ID |
LOCAL | boolean | 如果仅为本地查询则为true |
SCHEMA_NAME | String | 模式名 |
SUBJECT_ID | UUID | 发起查询的实体的主体ID |
# 5.18.SQL_QUERIES_HISTORY
| 列名 | 数据类型 | 描述 |
|---|---|---|
SCHEMA_NAME | String | 模式名 |
SQL | String | SQL文本 |
LOCAL | boolean | 如果仅为本地查询则为true |
EXECUTIONS | long | 执行次数 |
FAILURES | long | 失败次数 |
DURATION_MIN | long | 最短执行期限 |
DURATION_MAX | long | 最长执行期限 |
LAST_START_TIME | date | 上次执行时间 |
# 5.19.SCHEMAS
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | String | 模式名 |
PREDEFINED | boolean | 如果是预定义模式则为true |
# 5.20.NODE_METRICS
| 列名 | 数据类型 | 描述 |
|---|---|---|
NODE_ID | UUID | 节点ID |
LAST_UPDATE_TIME | TIMESTAMP | 指标数据上次更新的时间 |
MAX_ACTIVE_JOBS | INT | 节点曾经的最大并发作业数 |
CUR_ACTIVE_JOBS | INT | 节点当前正在运行的活跃作业数 |
AVG_ACTIVE_JOBS | FLOAT | 节点并发执行的平均活跃作业数 |
MAX_WAITING_JOBS | INT | 节点曾经的最大等待作业数 |
CUR_WAITING_JOBS | INT | 节点当前正在等待执行的作业数 |
AVG_WAITING_JOBS | FLOAT | 节点的平均等待作业数 |
MAX_REJECTED_JOBS | INT | 在一次冲突解决操作期间一次性的最大拒绝作业数 |
CUR_REJECTED_JOBS | INT | 最近一次冲突解决操作中的拒绝作业数 |
AVG_REJECTED_JOBS | FLOAT | 在冲突解决操作期间的平均拒绝作业数 |
TOTAL_REJECTED_JOBS | INT | 节点启动后在冲突解决期间的拒绝作业总数 |
MAX_CANCELED_JOBS | INT | 节点的并发最大取消作业数 |
CUR_CANCELED_JOBS | INT | 节点仍在运行的已取消作业数 |
AVG_CANCELED_JOBS | FLOAT | 节点的并发平均取消作业数 |
TOTAL_CANCELED_JOBS | INT | 节点启动后取消作业总数 |
MAX_JOBS_WAIT_TIME | TIME | 节点中的作业执行前在队列中的最大等待时间 |
CUR_JOBS_WAIT_TIME | TIME | 节点当前正在等待执行的作业的最长等待时间 |
AVG_JOBS_WAIT_TIME | TIME | 节点中的作业执行前在队列中的平均等待时间 |
MAX_JOBS_EXECUTE_TIME | TIME | 节点作业的最长执行时间 |
CUR_JOBS_EXECUTE_TIME | TIME | 节点当前正在执行的作业的执行时间 |
AVG_JOBS_EXECUTE_TIME | TIME | 节点作业的平均执行时间 |
TOTAL_JOBS_EXECUTE_TIME | TIME | 节点启动后已完成的作业的执行总时间 |
TOTAL_EXECUTED_JOBS | INT | 节点启动后处理的作业总数 |
TOTAL_EXECUTED_TASKS | INT | 节点处理过的任务总数 |
TOTAL_BUSY_TIME | TIME | 节点处理作业花费的总时间 |
TOTAL_IDLE_TIME | TIME | 节点的总空闲(未执行任何作业)时间 |
CUR_IDLE_TIME | TIME | 节点执行最近的作业后的空闲时间 |
BUSY_TIME_PERCENTAGE | FLOAT | 节点执行作业和空闲的时间占比 |
IDLE_TIME_PERCENTAGE | FLOAT | 节点空闲和执行作业的时间占比 |
TOTAL_CPU | INT | JVM的可用CPU数量 |
CUR_CPU_LOAD | DOUBLE | 在范围(0, 1)中以分数表示的CPU使用率 |
AVG_CPU_LOAD | DOUBLE | 在范围(0, 1)中以分数表示的CPU平均使用率 |
CUR_GC_CPU_LOAD | DOUBLE | 上次指标更新后花费在GC上的平均时间,指标默认2秒更新一次 |
HEAP_MEMORY_INIT | LONG | JVM最初从操作系统申请用于内存管理的堆内存量(字节)。如果初始内存大小未定义,则显示-1 |
HEAP_MEMORY_USED | LONG | 当前用于对象分配的堆大小,堆由一个或多个内存池组成,该值为所有堆内存池中使用的堆内存总数 |
HEAP_MEMORY_COMMITED | LONG | JVM使用的堆内存量(字节),这个内存量保证由JVM使用,堆由一个或多个内存池组成,该值为所有堆内存池中JVM使用的堆内存总数 |
HEAP_MEMORY_MAX | LONG | 用于内存管理的最大堆内存量(字节),如果最大内存量未指定,则显示-1 |
HEAP_MEMORY_TOTAL | LONG | 堆内存总量(字节),如果总内存量未指定,则显示-1 |
NONHEAP_MEMORY_INIT | LONG | JVM最初从操作系统申请用于内存管理的非堆内存量(字节)。如果初始内存大小未定义,则显示-1 |
NONHEAP_MEMORY_USED | LONG | JVM当前使用的非堆内存量,非堆内存由一个或多个内存池组成,该值为所有非堆内存池中使用的非堆内存总数 |
NONHEAP_MEMORY_COMMITED | LONG | JVM使用的非堆内存量(字节),这个内存量保证由JVM使用。非堆内存由一个或多个内存池组成,该值为所有非堆内存池中使用的非堆内存总数 |
NONHEAP_MEMORY_MAX | LONG | 可用于内存管理的最大非堆内存量(字节),如果最大内存量未指定,则显示-1 |
NONHEAP_MEMORY_TOTAL | LONG | 可用于内存管理的非堆内存总量(字节),如果总内存量未指定,则显示-1 |
UPTIME | TIME | JVM的正常运行时间 |
JVM_START_TIME | TIMESTAMP | JVM的启动时间 |
NODE_START_TIME | TIMESTAMP | 节点的启动时间 |
LAST_DATA_VERSION | LONG | 数据网格为所有缓存操作赋予的不断增长的版本数,该值为节点的最新数据版本 |
CUR_THREAD_COUNT | INT | 包括守护和非守护线程在内的所有有效线程总数 |
MAX_THREAD_COUNT | INT | JVM启动或峰值重置后的最大有效线程数 |
TOTAL_THREAD_COUNT | LONG | JVM启动后启动的线程总数 |
CUR_DAEMON_THREAD_COUNT | INT | 当前的有效守护线程数 |
SENT_MESSAGES_COUNT | INT | 节点发送的通信消息总量 |
SENT_BYTES_COUNT | LONG | 发送的字节量 |
RECEIVED_MESSAGES_COUNT | INT | 节点接收的通信消息总量 |
RECEIVED_BYTES_COUNT | LONG | 接收的字节量 |
OUTBOUND_MESSAGES_QUEUE | INT | 出站消息队列大小 |
# 5.21.TABLES
| 列名 | 数据类型 | 描述 |
|---|---|---|
TABLE_NAME | String | 表名 |
SCHEMA_NAME | String | 表所属模式名 |
CACHE_NAME | String | 表对应的缓存名 |
CACHE_ID | int | 表对应的缓存ID |
AFFINITY_KEY_COLUMN | String | 关联键列名 |
KEY_ALIAS | String | 主键列别名 |
VALUE_ALIAS | String | 值列别名 |
KEY_TYPE_NAME | String | 主键类型名 |
VALUE_TYPE_NAME | String | 值类型名 |
IS_INDEX_REBUILD_IN_PROGRESS | boolean | 如果表索引正在重建过程中则为true |
# 5.22.TABLE_COLUMNS
| 列名 | 数据类型 | 描述 |
|---|---|---|
COLUMN_NAME | String | 列名 |
TABLE_NAME | String | 表名 |
SCHEMA_NAME | String | 模式名 |
AFFINITY_COLUMN | boolean | 如果该列为关联键则为true |
AUTO_INCREMENT | boolean | 如果是自增字段则为true |
DEFAULT_VALUE | String | 默认值 |
NULLABLE | boolean | 如果允许为空则为true |
PK | boolean | 如果是主键则为true |
PRECISION | int | 列精度 |
SCALE | int | 列标度 |
TYPE | String | 列类型 |
# 5.23.VIEWS
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | String | 视图名 |
SCHEMA | String | 模式名 |
DESCRIPTION | String | 描述 |
# 5.24.VIEW_COLUMNS
| 列名 | 数据类型 | 描述 |
|---|---|---|
COLUMN_NAME | String | 列名 |
VIEW_NAME | String | 视图名 |
SCHEMA_NAME | String | 模式名 |
DEFAULT_VALUE | String | 默认值 |
NULLABLE | boolean | 如果允许为空则为true |
PRECISION | int | 列精度 |
SCALE | int | 列标度 |
TYPE | String | 列类型 |
# 5.25.INDEXES
| 列名 | 数据类型 | 描述 |
|---|---|---|
INDEX_NAME | String | 索引名 |
INDEX_TYPE | String | 索引类型 |
COLUMNS | String | 索引中的列名 |
SCHEMA_NAME | String | 模式名 |
TABLE_NAME | String | 表名 |
CACHE_NAME | String | 缓存名 |
CACHE_ID | int | 缓存ID |
INLINE_SIZE | int | 内联大小(字节) |
IS_PK | boolean | 是否为主键索引 |
IS_UNIQUE | boolean | 是否为唯一索引 |
# 5.26.PAGE_LISTS
页面列表是一种数据结构,用于存储部分空闲的数据页面(空闲列表)和完全空闲的已分配页面(重用列表)的列表。空闲列表和重用列表的目的是快速找到具有足够可用空间来保存条目的页面,或者确定不存在这样的页面然后分配新页面。页面列表按存储桶进行组织。每个存储桶组都引用具有大约相同的可用空间大小的页面。
如果启用了原生持久化,则将为每个缓存组的每个分区创建页面列表。要查看此类页面列表,请使用CACHE_GROUP_PAGE_LISTS系统视图。如果禁用了原生持久化,则会为每个数据区创建页面列表,这时应使用DATA_REGION_PAGE_LISTS系统视图。这些视图包含有关每个页面列表的每个存储区的信息,这些信息对于了解可以在不分配新页面的情况下将多少数据插入到缓存中也很有用,还有助于监测页面列表利用率的偏差。
# 5.26.1.CACHE_GROUP_PAGE_LISTS
| 列名 | 数据类型 | 描述 |
|---|---|---|
CACHE_GROUP_ID | int | 缓存组ID |
PARTITION_ID | int | 分区ID |
NAME | String | 页面列表名 |
BUCKET_NUMBER | int | 存储桶号 |
BUCKET_SIZE | long | 存储桶中页面数 |
STRIPES_COUNT | int | 存储桶使用的平行线程数,平行线程用于避免争用 |
CACHED_PAGES_COUNT | int | 此存储桶的堆内页面列表缓存中的页面数 |
PAGE_FREE_SPACE | int | 可用于此存储桶中每个页面的可用空间(字节) |
# 5.26.2.DATA_REGION_PAGE_LISTS
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | String | 页面列表名 |
BUCKET_NUMBER | int | 存储桶号 |
BUCKET_SIZE | long | 存储桶中页面数 |
STRIPES_COUNT | int | 存储桶使用的平行线程数,平行线程用于避免争用 |
CACHED_PAGES_COUNT | int | 此存储桶的堆内页面列表缓存中的页面数 |
PAGE_FREE_SPACE | int | 可用于此存储桶中每个页面的可用空间(字节) |
# 5.27.PARTITION_STATES
| 列名 | 数据类型 | 描述 |
|---|---|---|
CACHE_GROUP_ID | int | 缓存组ID |
PARTITION_ID | int | 分区ID |
NODE_ID | UUID | 节点ID |
STATE | String | 分区状态。可能值:MOVING:分区正在从另一个节点加载到该节点;OWNING:该节点是主/备所有者;RENTING:此节点不是主/备所有者(当前正在被驱逐);EVICTED:分区已被驱逐;LOST:分区状态无效,不应使用该分区 |
IS_PRIMARY | boolean | 主分区标志 |
# 5.28.BINARY_METADATA
| 列名 | 数据类型 | 描述 |
|---|---|---|
TYPE_ID | int | 类型ID |
TYPE_NAME | String | 类型名字 |
AFF_KEY_FIELD_NAME | String | 关联键字段名 |
FIELDS_COUNT | int | 字段数量 |
FIELDS | String | 记录对象字段 |
SCHEMAS_IDS | String | 该类型注册的模式ID |
IS_ENUM | boolean | 是否为枚举类型 |
# 5.29.METASTORAGE
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | String | 名称 |
VALUE | String | 元素的字符串或原始二进制(如果由于某种原因无法反序列化数据)表示形式 |
# 5.30.DS_QUEUES
| 列名 | 数据类型 | 描述 |
|---|---|---|
ID | UUID | ID |
NAME | string | 数据结构名 |
CAPACITY | int | 容量 |
SIZE | int | 当前值 |
BOUNDED | boolean | 如果队列容量有界则为true |
COLLOCATED | boolean | 并置模式则为true |
GROUP_NAME | string | 存储数据结构的缓存组名 |
GROUP_ID | int | 存储数据结构的缓存组ID |
REMOVED | boolean | 已删除则为true |
# 5.31.DS_SETS
| 列名 | 数据类型 | 描述 |
|---|---|---|
ID | UUID | ID |
NAME | string | 数据结构名 |
SIZE | int | 当前值 |
COLLOCATED | boolean | 并置模式则为true |
GROUP_NAME | string | 存储数据结构的缓存组名 |
GROUP_ID | int | 存储数据结构的缓存组ID |
REMOVED | boolean | 已删除则为true |
# 5.32.DS_ATOMICSEQUENCES
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | string | 数据结构名 |
VALUE | long | 当前序列值 |
BATCH_SIZE | long | 本地批次大小 |
GROUP_NAME | string | 存储数据结构的缓存组名 |
GROUP_ID | int | 存储数据结构的缓存组ID |
REMOVED | boolean | 已删除则为true |
# 5.33.DS_ATOMICLONGS
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | string | 数据结构名 |
VALUE | long | 当前序列值 |
GROUP_NAME | string | 存储数据结构的缓存组名 |
GROUP_ID | int | 存储数据结构的缓存组ID |
REMOVED | boolean | 已删除则为true |
# 5.34.DS_ATOMICREFERENCES
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | string | 数据结构名 |
VALUE | long | 当前序列值 |
GROUP_NAME | string | 存储数据结构的缓存组名 |
GROUP_ID | int | 存储数据结构的缓存组ID |
REMOVED | boolean | 已删除则为true |
# 5.35.DS_ATOMICSTAMPED
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | string | 数据结构名 |
VALUE | long | 当前序列值 |
STAMP | string | 当前戳记值 |
GROUP_NAME | string | 存储数据结构的缓存组名 |
GROUP_ID | int | 存储数据结构的缓存组ID |
REMOVED | boolean | 已删除则为true |
# 5.36.DS_COUNTDOWNLATCHES
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | string | 数据结构名 |
COUNT | int | 当前计数值 |
INITIAL_COUT | int | 初始计数值 |
AUTO_DELETE | boolean | 如果在闩锁计数为零时自动从缓存中删除闩锁,则为true |
GROUP_NAME | string | 存储数据结构的缓存组名 |
GROUP_ID | int | 存储数据结构的缓存组ID |
REMOVED | boolean | 已删除则为true |
# 5.37.DS_SEMAPHORES
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | string | 数据结构名 |
AVAILABLE_PERMITS | long | 可用许可数 |
HAS_QUEUED_THREADS | boolean | 如果可能还有其他线程等待获取锁,则为true |
QUEUE_LENGTH | int | 等待此锁的估计节点数 |
FAILOVER_SAFE | boolean | 如果故障转移安全,则为true |
BROKEN | boolean | 如果节点在此信号量上失败并且故障转移安全标志设置为false,则为true,否则为false |
GROUP_NAME | string | 存储数据结构的缓存组名 |
GROUP_ID | int | 存储数据结构的缓存组ID |
REMOVED | boolean | 已删除则为true |
# 5.38.DS_REENTRANTLOCKS
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | string | 数据结构名 |
LOCKED | boolean | 如果锁定则为true |
HAS_QUEUED_THREADS | boolean | 如果可能还有其他线程等待获取锁,则为true |
FAILOVER_SAFE | boolean | 如果故障转移安全,则为true |
FAIR | boolean | 如果锁是公平的,则为true |
BROKEN | boolean | 如果节点在此信号量上失败并且故障转移安全标志设置为false,则为true,否则为false |
GROUP_NAME | string | 存储数据结构的缓存组名 |
GROUP_ID | int | 存储数据结构的缓存组ID |
REMOVED | boolean | 已删除则为true |
# 5.39.STATISTICS_CONFIGURATION
| 列名 | 数据类型 | 描述 |
|---|---|---|
SCHEMA | VARCHAR | 模式名 |
TYPE | VARCHAR | 对象类型 |
NAME | VARCHAR | 对象名 |
COLUMN | VARCHAR | 列名 |
MAX_PARTITION_OBSOLESCENCE_PERCENT | TINYINT | 统计中过时行的最大百分比 |
MANUAL_NULLS | BIGINT | 如果不为空 - 覆盖的空值数 |
MANUAL_DISTINCT | BIGINT | 如果不为空 - 覆盖的不同值的数量 |
MANUAL_TOTAL | BIGINT | 如果不为空 - 覆盖值的总数 |
MANUAL_SIZE | INT | 如果不为空 - 覆盖列中非空值的平均大小 |
VERSION | BIGINT | 配置版本 |
# 5.40.STATISTICS_LOCAL_DATA
| 列名 | 数据类型 | 描述 |
|---|---|---|
SCHEMA | VARCHAR | 模式名 |
TYPE | VARCHAR | 对象类型 |
NAME | VARCHAR | 对象名 |
COLUMN | VARCHAR | 列名 |
ROWS_COUNT | BIGINT | 行数 |
DISTINCT | BIGINT | 唯一非空值的数量 |
NULLS | BIGINT | 空值数量 |
TOTAL | BIGINT | 总数量 |
SIZE | INTEGER | 平均值大小(字节) |
VERSION | BIGINT | 统计版本 |
LAST_UPDATE_TIME | VARCHAR | 用于生成本地分区统计信息的所有分区统计信息的最长时间 |
# 5.41.STATISTICS_PARTITION_DATA
| 列名 | 数据类型 | 描述 |
|---|---|---|
SCHEMA | VARCHAR | 模式名 |
TYPE | VARCHAR | 对象类型 |
NAME | VARCHAR | 对象名 |
COLUMN | VARCHAR | 列名 |
PARTITION | INTEGER | 分区号 |
ROWS_COUNT | BIGINT | 行数 |
UPDATE_COUNTER | BIGINT | 统计信息收集后的分区更新计数器 |
DISTINCT | BIGINT | 唯一非空值的数量 |
NULLS | BIGINT | 空值数量 |
TOTAL | BIGINT | 总数量 |
SIZE | INTEGER | 平均值大小(字节) |
VERSION | BIGINT | 统计版本 |
LAST_UPDATE_TIME | VARCHAR | 用于生成本地分区统计信息的所有分区统计信息的最长时间 |
# 5.42.SNAPSHOT
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | VARCHAR | 快照名 |
CONSISTENT_ID | VARCHAR | 快照数据所属节点的一致性ID |
BASELINE_NODES | VARCHAR | 快照涉及的基线节点 |
CACHE_GROUPS | VARCHAR | 快照中包含的缓存组名 |
SNAPSHOT_RECORD_SEGMENT | BIGINT | 包含快照WAL记录的WAL段索引值 |
INCREMENT_INDEX | INTEGER | 增量快照索引值 |
TYPE | VARCHAR | 快照类型,全部或者增量 |
# 5.43.CONFIGURATION
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | VARCHAR | 配置属性名 |
VALUE | VARCHAR | 配置属性值 |
# 5.44.DISTRIBUTED_METASTORAGE
| 列名 | 数据类型 | 描述 |
|---|---|---|
NAME | VARCHAR | 属性名 |
VALUE | VARCHAR | 元素的字符串或者原始二进制表示(如果无法反序列化) |
# 5.45.CLIENT_CONNECTION_ATTRIBUTES
该视图暴露了客户端连接(瘦客户端、JDBC、ODBC)的用户定义属性,这些连接的属性由客户端提供。例如,可以使用ClientConfiguration.setUserAttributes方法指定Java瘦客户端的属性。
| 列名 | 数据类型 | 描述 |
|---|---|---|
CONNECTION_ID | LONG | 连接的ID |
NAME | VARCHAR | 属性名 |
VALUE | VARCHAR | 属性值 |
# 6.追踪
警告
这是一个试验性API。
Ignite中的许多API都可以通过OpenCensus进行追踪。可以收集在集群中执行的各种任务的分布式追踪,来诊断各种问题。
建议在阅读本章节之前先熟悉OpenCensus。
下列Ignite API支持追踪:
- 发现;
- 通信;
- 交换;
- 事务;
- SQL查询。
要查看追踪信息,必须将其导出到外部系统。可以使用OpenCensus的导出器,也可以自己开发导出器,但是不管怎样,导出器都必须在Ignite中注册,具体请参考导出追踪。
# 6.1.配置追踪
启用OpenCensus追踪是在节点的配置中进行的,集群中的所有节点必须使用相同的追踪配置。
# 6.2.启用追踪采样
使用以上配置启动集群后,Ignite不会收集追踪信息,必须在运行时为某API启用追踪采样。追踪采样可以随意打开和关闭,例如仅在遇到问题时才打开。
可以通过2种方式执行此操作:
- 通过命令行的控制脚本;
- 通过编程方式。
追踪信息是以一定的概率采样率采集的,速率是介于0.0和1.0之间的一个值(包括0和1.0):0表示不采样,1表示始终采样。
当采样率为大于0的值时,Ignite就会收集追踪信息。要禁用追踪收集,可以将采样率设为0。
以下章节介绍了启用追踪采样的两种方式:
# 6.2.1.通过控制脚本
转到Ignite安装目录的{IGNITE_HOME}/bin,在控制脚本中启用实验性命令:
export IGNITE_ENABLE_EXPERIMENTAL_COMMAND=true
启用对某API的追踪:
./control.sh --tracing-configuration set --scope TX --sampling-rate 1
参考控制脚本章节的内容,可以了解所有参数的列表。
# 6.2.2.通过编程方式
启动节点后,可以按以下方式启用追踪采样:
Ignite ignite = Ignition.start();
ignite.tracingConfiguration().set(
new TracingConfigurationCoordinates.Builder(Scope.TX).build(),
new TracingConfigurationParameters.Builder().withSamplingRate(1).build());
--scope参数指定要追踪的API,下列API支持追踪:
DISCOVERY:发现事件;EXCHANGE:交换事件;COMMUNICATION:通信事件;TX:事务;SQL:SQL查询。
--sampling-rate是概率采样率,值在数字0和1之间:
0:表示没有采样;1:表示始终采样。
# 6.3.导出追踪
要查看追踪信息,需要使用导出器将其导出到外部系统。OpenCensus直接支持很多导出器,也可以编写自定义的导出器。具体可参考OpenCensus导出器。
本章节中将介绍如何将追踪信息导出到Zipkin。
- 按照本文档在主机上启动Zipkin;
- 在启动Ignite的应用中注册
ZipkinTraceExporter:
//register Zipkin exporter
ZipkinTraceExporter.createAndRegister(
ZipkinExporterConfiguration.builder().setV2Url("http://localhost:9411/api/v2/spans")
.setServiceName("ignite-cluster").build());
IgniteConfiguration cfg = new IgniteConfiguration().setClientMode(true)
.setTracingSpi(new org.apache.ignite.spi.tracing.opencensus.OpenCensusTracingSpi());
Ignite ignite = Ignition.start(cfg);
//enable trace sampling for transactions with 100% sampling rate
ignite.tracingConfiguration().set(
new TracingConfigurationCoordinates.Builder(Scope.TX).build(),
new TracingConfigurationParameters.Builder().withSamplingRate(1).build());
//create a transactional cache
IgniteCache<Integer, String> cache = ignite
.getOrCreateCache(new CacheConfiguration<Integer, String>("myCache")
.setAtomicityMode(CacheAtomicityMode.TRANSACTIONAL));
IgniteTransactions transactions = ignite.transactions();
// start a transaction
try (Transaction tx = transactions.txStart()) {
//do some operations
cache.put(1, "test value");
System.out.println(cache.get(1));
cache.put(1, "second value");
tx.commit();
}
try {
//This code here is to wait until the trace is exported to Zipkin.
//If your application doesn't stop here, you don't need this piece of code.
Thread.sleep(5_000);
} catch (InterruptedException e) {
e.printStackTrace();
}
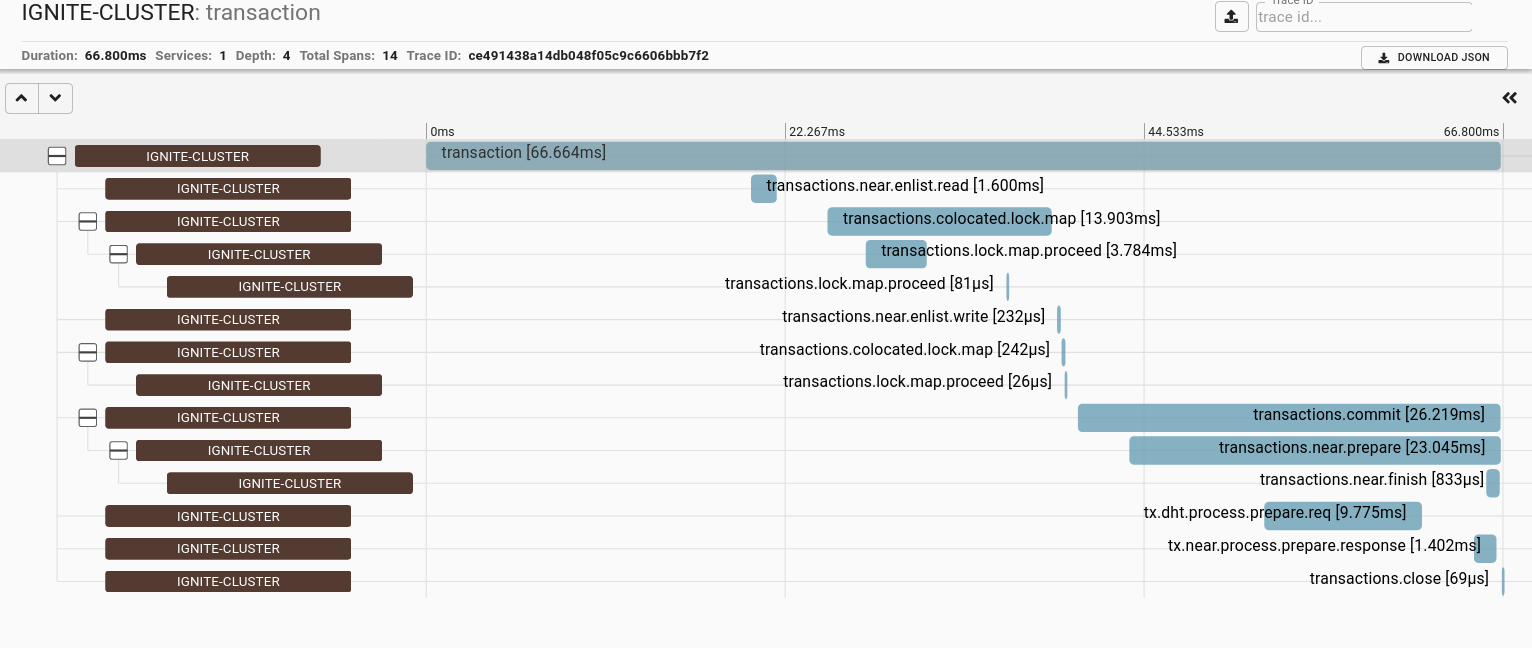
- 在浏览器中打开http://localhost:9411/zipkin,然后点击搜索图标,事务追踪如下图所示:
# 6.4.分析追踪数据
追踪记录了某事件执行的信息,每条追踪信息都由一棵跨度树组成,跨度是系统为了处理事件而执行的单个工作单元。
由于Ignite的分布式特性,一个操作通常涉及多个节点,因此追踪信息可以包括来自多个节点的跨度,每个跨度始终包含有关执行相应操作的节点的信息。
在上面显示的事务追踪图中,可以看到该追踪包含与以下操作关联的跨度:
- 获取锁(
transactions.colocated.lock.map); - 读(
transactions.near.enlist.read); - 写(
transactions.near.enlist.write); - 提交(
transactions.commit); - 关闭(
transactions.close)。
提交操作又包括两个操作:准备和完成。
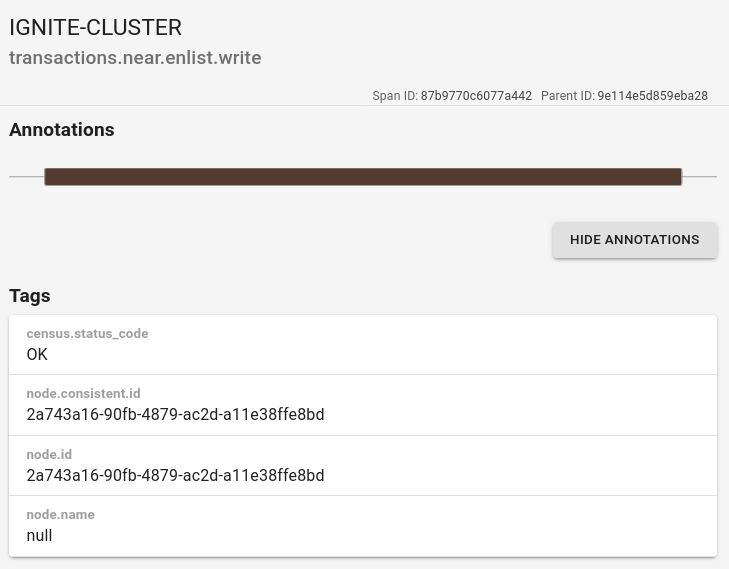
可以单击每个跨度以查看附加到其上的注释和标签:
# 6.5.追踪SQL查询
在追踪采样配置中将scope参数值配置为SQL,可以开启SQL查询的追踪功能,开启该功能之后,在任何集群节点上执行的每个SQL查询都会产生单独的追踪。
警告
对SQL查询启用追踪会严重降低SQL引擎的性能。
下表列出了可以作为SQL查询追踪树一部分的每个跨度的说明、标签列表和注释。
提示
根据SQL查询类型及其执行计划,SQL查询跨度树中可能不存在某些跨度。
| 跨度名 | 描述 | 标签和注释 |
|---|---|---|
| sql.query | 在释放查询发起节点上的已用资源之前,从注册时刻开始执行的SQL查询 | sql.query.text:SQL查询文本,sql.schema:SQL模式 |
| sql.cursor.open | SQL查询游标打开 | |
| sql.cursor.close | SQL查询游标关闭 | |
| sql.cursor.cancel | SQL查询游标取消 | |
| sql.query.parse | SQL查询解析 | sql.parser.cache.hit:是否由于缓存结果而跳过了对SQL查询的解析 |
| sql.query.execute.request | SQL查询执行请求的处理 | sql.query.text:SQL查询文本 |
| sql.next.page.request | 获取本地SQL查询执行结果下一页请求的处理 | |
| sql.page.response | 节点本地SQL查询执行结果页面消息的处理 | |
| sql.query.execute | 通过H2 SQL引擎执行查询 | sql.query.text:SQL查询文本 |
| sql.page.prepare | 从游标读取行并准备结果页 | sql.page.rows:结果页面包含的行数 |
| sql.fail.response | SQL查询执行失败消息的处理 | |
| sql.dml.query.execute.request | SQL DML查询执行请求的处理 | sql.query.text:SQL查询文本 |
| sql.dml.query.response | 查询发起节点对SQL DML查询执行结果的处理 | |
| sql.query.cancel.request | SQL查询取消请求的处理 | |
| sql.iterator.open | SQL查询迭代器打开 | |
| sql.iterator.close | SQL查询迭代器关闭 | |
| sql.page.fetch | 获取SQL查询结果页面 | sql.page.rows:结果页面包含的行数 |
| sql.page.wait | 等待从远程节点接收SQL查询结果页面 | |
| sql.index.range.request | SQL索引范围请求的处理 | sql.index:SQL索引名,sql.table:SQL表名,sql.index.range.rows:索引范围请求结果包含的行数 |
| sql.index.range.response | SQL索引范围响应的处理 | |
| sql.dml.query.execute | SQL DML查询的执行 | |
| sql.command.query.execute | SQL命令查询的执行,可能是DDL查询或者Ignite原生命令 | |
| sql.partitions.reserve | 保留用于执行查询的数据分区 | 显示为某缓存保留数据分区的注释消息:Cache partitions were reserved [cache=<name of the cache>, partitions=[<partitions numbers>] |
| sql.cache.update | 由于执行SQL DML查询而导致的缓存更新 | sql.cache.updates:由于DML查询而要更新的缓存条目数 |
| sql.batch.process | SQL批处理更新的处理 |
# 7.性能统计
警告
该功能是试验性的,未来的版本中可能会修改。
# 7.1.概述
Ignite内置了用于分析集群的工具,可以从集群中收集性能统计然后生成性能报告。
# 7.2.收集统计数据
每个节点都以二进制文件的形式收集性能统计信息,该文件位于Ignite_work_directory/perf_stat/目录下,名称是node-{nodeId}-{index}.prf。
性能统计文件用于离线构建报告。
节点使用堆外循环缓冲区临时存储序列化的统计信息。当达到刷新大小时,写入线程会将缓冲区刷新到文件。如果缓冲区由于磁盘速度慢而溢出,则会跳过某些统计信息,其行为可通过如下参数进行自定义。
每个统计信息收集过程都会在节点上创建一个新文件,下一个文件具有相同的名称和相应的索引,示例如下:
node-faedc6c9-3542-4610-ae10-4ff7e0600000.prf;node-faedc6c9-3542-4610-ae10-4ff7e0600000-1.prf;node-faedc6c9-3542-4610-ae10-4ff7e0600000-2.prf。
# 7.3.生成报告
Ignite提供了通过性能统计文件生成报告的工具,该工具发布于ignite-extensions仓库的performance-statistics-ext扩展。
遵循下面的步骤可以生成性能报告:
- 停止收集统计信息并将文件从所有节点放在某空目录下。例如:
/path_to_files/ ├── node-162c7147-fef8-4ea2-bd25-8653c41fc7fa.prf ├── node-7b8a7c5c-f3b7-46c3-90da-e66103c00001.prf └── node-faedc6c9-3542-4610-ae10-4ff7e0600000.prf - 在工具的二进制包中执行如下的命令:
performance-statistics-tool/build-report.sh path_to_files
性能报告位于性能统计文件路径下的一个新文件夹中:path_to_files/report_yyyy-MM-dd_HH-mm-ss/,在浏览器中打开report_yyyy-MM-dd_HH-mm-ss/index.html可以看到报告。
# 7.4.管理
下面的章节介绍了与JMX接口、控制脚本和系统属性有关的信息。
# 7.4.1.JMX
可以通过PerformanceStatisticsMBean接口来管理性能统计收集:
| 方法 | 描述 |
|---|---|
| start() | 在集群中启动性能统计收集 |
| stop() | 在集群中停止性能统计收集 |
| started() | 性能统计收集已启动则为true |
# 7.4.2.控制脚本
可以通过控制脚本来控制性能统计的收集。
参数:
| 参数 | 描述 |
|---|---|
start | 在集群中开始收集性能统计数据 |
stop | 在集群中停止收集性能统计数据 |
rotate | 轮流收集集群中的性能统计数据 |
status | 取得集群中收集性能统计数据的状态 |
# 7.4.3.系统属性
| 属性 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| IGNITE_PERF_STAT_FILE_MAX_SIZE | Long | 32Gb | 最大性能统计文件大小(字节)。当超出文件大小时,性能统计信息收集将停止 |
| IGNITE_PERF_STAT_BUFFER_SIZE | Integer | 32Mb | 性能统计信息堆外缓冲区大小(字节) |
| IGNITE_PERF_STAT_FLUSH_SIZE | Integer | 8Mb | 要刷新的最小性能统计批次大小(字节) |
| IGNITE_PERF_STAT_CACHED_STRINGS_THRESHOLD | Integer | 1024 | 最大性能统计缓存字符串阈值。超过阈值时,将停止字符串缓存 |
18624049226

← Ignite C++ 处理事件 →