
SQL入门
本章节将介绍通过命令行使用 Apache Ignite 3 的 SQL 功能。这里将设置分布式 Ignite 集群,创建和操作 Chinook 数据库(代表数字媒体存储的示例数据库),并学习如何利用 Ignite 强大的 SQL 功能。
1.前提条件
- 系统上安装了 Docker 和 Docker Compose;
- 对 SQL 有基本的了解;
- 可以操作命令行终端;
- 8GB+ 可用内存用于运行容器;
- 下载了包含 Chinook 数据库文件的 SQL 目录。
2.开始之前
本章节使用事先准备好的文件来简化演示,所以需下载下列文件:
将压缩包解压缩到一个新文件夹中,并将其和docker-compose.yml文件放在将运行 Docker 命令的同一目录中,本章节假定这些 SQL 文件可用并挂载到容器。
提示
如果没有这些文件,将无法加载练习所需的示例数据。
3.设置 Apache Ignite 3 集群
使用 SQL 之前需要有一个 Ignite 集群,这里会使用 Docker Compose 创建一个三节点集群。
3.1.启动集群
打开终端,转到包含docker-compose.yml文件的目录,然后使用 Docker 启动集群:
docker compose up -d该命令以分离模式启动集群,会看到来自所有三个节点的启动消息。当准备好时,可以看到服务端已成功启动的消息:
docker compose up -d
[+] Running 4
✔ Network ignite3_default Created
✔ Container ignite3-node2-1 Started
✔ Container ignite3-node3-1 Started
✔ Container ignite3-node1-1 Started也可以使用以下命令检查所有容器是否正在运行:
docker compose ps应该会看到所有三个节点都处于running状态。
提示
在继续之前,请验证所有三个节点是否都在运行。
4.使用 Ignite 命令行工具接入集群
这里将使用 Ignite 命令行工具接入正在运行的集群。
4.1.启动命令行工具
在终端中,运行:
docker run --rm -it --network=host -e LANG=C.UTF-8 -e LC_ALL=C.UTF-8 -v ./sql/:/opt/ignite/downloads/ apacheignite/ignite:3.1.0 cli这将启动一个接入到与集群相同的 Docker 网络的交互式命令行容器,并挂载一个包含 Chinook 数据库 sql 文件的卷。出现提示时,会接入默认节点。如果连接被拒绝,可以使用以下命令手动执行:
connect http://localhost:10300这里会看到一条已连接到http://localhost:10300的消息,以及一条说明集群未初始化的注释。
提示
命令行容器与集群节点分开运行,但通过 Docker 网络连接到集群节点。
4.2.初始化集群
在使用集群之前,需要对其进行初始化:
cluster init --name=ignite3 # ___ __
### / | ____ ____ _ _____ / /_ ___
# ##### / /| | / __ \ / __ `// ___// __ \ / _ \
### ###### / ___ | / /_/ // /_/ // /__ / / / // ___/
##### ####### /_/ |_|/ .___/ \__,_/ \___//_/ /_/ \___/
####### ###### /_/
######## #### ____ _ __ _____
# ######## ## / _/____ _ ____ (_)/ /_ ___ |__ /
#### ####### # / / / __ `// __ \ / // __// _ \ /_ <
##### ##### _/ / / /_/ // / / // // /_ / ___/ ___/ /
#### ## /___/ \__, //_/ /_//_/ \__/ \___/ /____/
## /____/
Apache Ignite CLI version 3.1.0
You appear to have not connected to any node yet. Do you want to connect to the default node http://localhost:10300? [Y/n] y
Connected to http://localhost:10300
The cluster is not initialized. Run cluster init command to initialize it.
[node1]> cluster init --name=ignite3
Cluster was initialized successfully
[node1]>5.创建 Chinook 数据库模式
现在集群已经运行并初始化,可以使用 SQL 在 Ignite 中创建和处理数据。Chinook 数据库是一个数字音乐商店数据集,包含艺术家、专辑、曲目、客户和销售的表。
5.1.进入 SQL 模式
要使用 SQL,需在命令行中进入 SQL 模式:
sql提示应变为sql-cli>,表示当前处于 SQL 模式。
[node1]> sql
sql-cli>5.2.创建分布区
在创建表之前,需要配置分布区来控制数据在集群中的分布和复制方式:
CREATE ZONE IF NOT EXISTS Chinook WITH replicas=2, storage_profiles='default';
CREATE ZONE IF NOT EXISTS ChinookReplicated WITH replicas=3, partitions=25, storage_profiles='default';这些命令创建两个分布区:
Chinook:标准分区区,大多数表有 2 个副本;ChinookReplicated:具有 3 个副本的分布区,用于经常访问的数据。
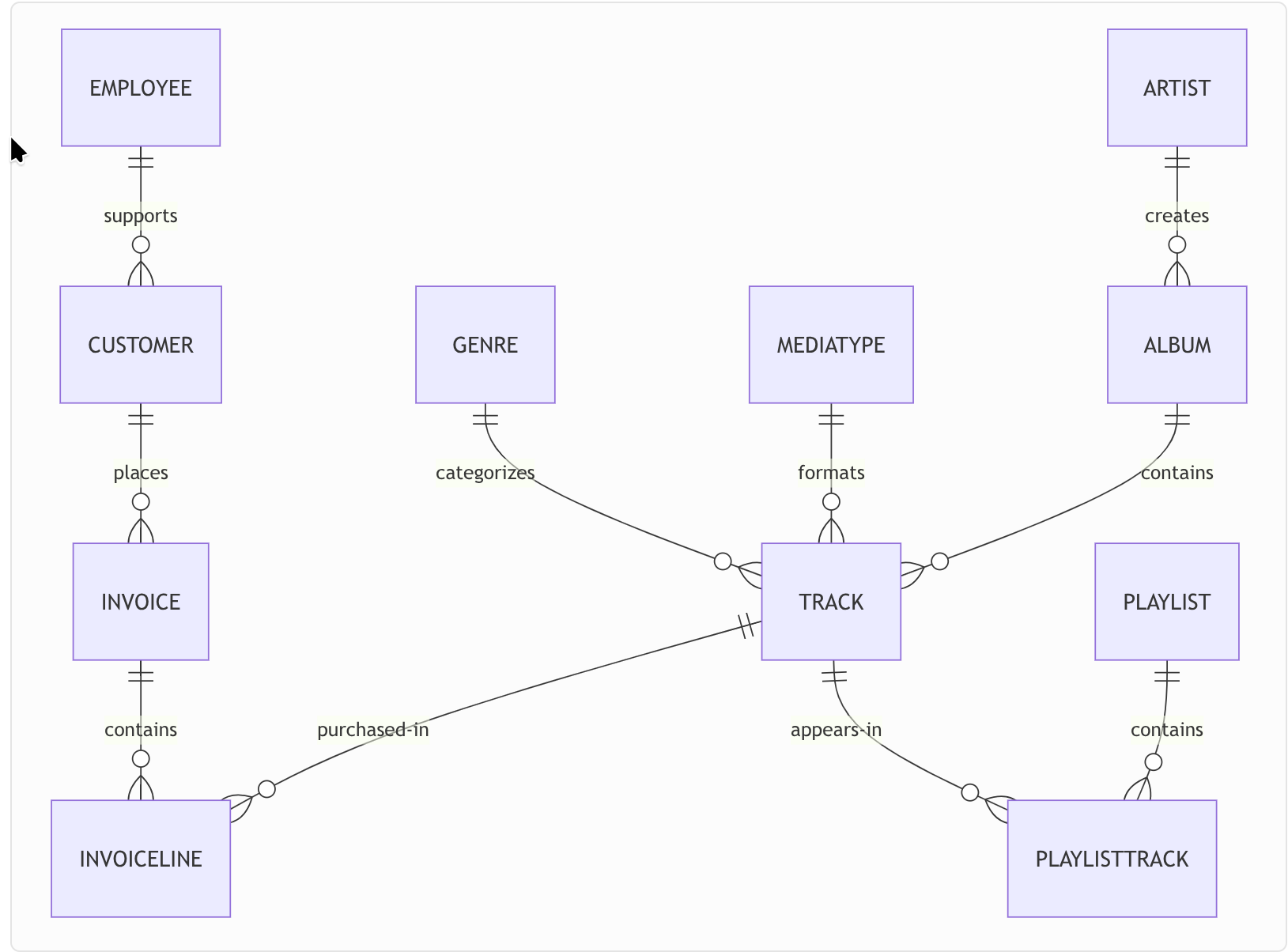
5.3.数据库实体关系
下面是 Chinook 数据库的实体关系图:
5.4.创建核心表
现在为 Chinook 数据库创建主表,这里将从艺术家和专辑表开始。
提示
在sql-cli>提示符处复制并粘贴以下 SQL 块,然后执行。
CREATE TABLE Artist (
ArtistId INT NOT NULL,
Name VARCHAR(120),
PRIMARY KEY (ArtistId)
) ZONE Chinook;
CREATE TABLE Album (
AlbumId INT NOT NULL,
Title VARCHAR(160) NOT NULL,
ArtistId INT NOT NULL,
ReleaseYear INT,
PRIMARY KEY (AlbumId, ArtistId)
) COLOCATE BY (ArtistId) ZONE Chinook;Album 表中的COLOCATE BY子句表示同一艺术家的专辑存储在同一节点上,当需要在艺术家表和专辑表之间做联接时,通过避免不必要的网络传输,可以优化查询的性能。
接下来,让我们创建 Genre 和 MediaType 对照表:
CREATE TABLE Genre (
GenreId INT NOT NULL,
Name VARCHAR(120),
PRIMARY KEY (GenreId)
) ZONE ChinookReplicated;
CREATE TABLE MediaType (
MediaTypeId INT NOT NULL,
Name VARCHAR(120),
PRIMARY KEY (MediaTypeId)
) ZONE ChinookReplicated;这些对照表放置在有 3 个副本的ChinookReplicated分布区中,因为它们包含经常与其他表联接的静态数据,在每个节点上都有一个副本可以提高读取性能。
下面创建 Track 表,该表引用 Album、Genre 和 MediaType 表:
CREATE TABLE Track (
TrackId INT NOT NULL,
Name VARCHAR(200) NOT NULL,
AlbumId INT,
MediaTypeId INT NOT NULL,
GenreId INT,
Composer VARCHAR(220),
Milliseconds INT NOT NULL,
Bytes INT,
UnitPrice NUMERIC(10,2) NOT NULL,
PRIMARY KEY (TrackId, AlbumId)
) COLOCATE BY (AlbumId) ZONE Chinook;Track 表由 AlbumId 而不是 TrackId 并置,因为多数查询将Track表与Album表联接,这优化了这些常见的联接模式。
下面会创建表来管理客户、员工和销售:
CREATE TABLE Employee (
EmployeeId INT NOT NULL,
LastName VARCHAR(20) NOT NULL,
FirstName VARCHAR(20) NOT NULL,
Title VARCHAR(30),
ReportsTo INT,
BirthDate DATE,
HireDate DATE,
Address VARCHAR(70),
City VARCHAR(40),
State VARCHAR(40),
Country VARCHAR(40),
PostalCode VARCHAR(10),
Phone VARCHAR(24),
Fax VARCHAR(24),
Email VARCHAR(60),
PRIMARY KEY (EmployeeId)
) ZONE Chinook;
CREATE TABLE Customer (
CustomerId INT NOT NULL,
FirstName VARCHAR(40) NOT NULL,
LastName VARCHAR(20) NOT NULL,
Company VARCHAR(80),
Address VARCHAR(70),
City VARCHAR(40),
State VARCHAR(40),
Country VARCHAR(40),
PostalCode VARCHAR(10),
Phone VARCHAR(24),
Fax VARCHAR(24),
Email VARCHAR(60) NOT NULL,
SupportRepId INT,
PRIMARY KEY (CustomerId)
) ZONE Chinook;
CREATE TABLE Invoice (
InvoiceId INT NOT NULL,
CustomerId INT NOT NULL,
InvoiceDate DATE NOT NULL,
BillingAddress VARCHAR(70),
BillingCity VARCHAR(40),
BillingState VARCHAR(40),
BillingCountry VARCHAR(40),
BillingPostalCode VARCHAR(10),
Total NUMERIC(10,2) NOT NULL,
PRIMARY KEY (InvoiceId, CustomerId)
) COLOCATE BY (CustomerId) ZONE Chinook;
CREATE TABLE InvoiceLine (
InvoiceLineId INT NOT NULL,
InvoiceId INT NOT NULL,
TrackId INT NOT NULL,
UnitPrice NUMERIC(10,2) NOT NULL,
Quantity INT NOT NULL,
PRIMARY KEY (InvoiceLineId, TrackId)
) COLOCATE BY (TrackId) ZONE Chinook;Invoice表由CustomerId并置,InvoiceLine表由TrackId并置,这创建了一个高效的本地链:Customer→Invoice→ InvoiceLine,可以优化分析客户购买历史记录的查询。
最后创建与播放列表相关的表:
CREATE TABLE Playlist (
PlaylistId INT NOT NULL,
Name VARCHAR(120),
PRIMARY KEY (PlaylistId)
) ZONE Chinook;
CREATE TABLE PlaylistTrack (
PlaylistId INT NOT NULL,
TrackId INT NOT NULL,
PRIMARY KEY (PlaylistId, TrackId)
) ZONE Chinook;注意,PlaylistTrack 不与 Track 并置,这是一个设计决策,优先考虑播放列表操作而不是加入曲目详细信息。在实际场景中,可能会根据最常见的查询模式做出不同的并置选择。
5.5.验证创建的表
下面需要确认所有表都已成功创建:
SELECT * FROM system.tables WHERE schema = 'PUBLIC';该SQL会查询系统表以验证已创建的表是否存在,这里会看到已创建的所有表的列表。
sql-cli> SELECT * FROM system.tables WHERE schema = 'PUBLIC';
╔════════╤═══════════════╤════╤═════════════╤═══════════════════╤═════════════════╤══════════════════════╗
║ SCHEMA │ NAME │ ID │ PK_INDEX_ID │ ZONE │ STORAGE_PROFILE │ COLOCATION_KEY_INDEX ║
╠════════╪═══════════════╪════╪═════════════╪═══════════════════╪═════════════════╪══════════════════════╣
║ PUBLIC │ ALBUM │ 20 │ 21 │ CHINOOK │ default │ ARTISTID ║
╟────────┼───────────────┼────┼─────────────┼───────────────────┼─────────────────┼──────────────────────╢
║ PUBLIC │ GENRE │ 22 │ 23 │ CHINOOKREPLICATED │ default │ GENREID ║
╟────────┼───────────────┼────┼─────────────┼───────────────────┼─────────────────┼──────────────────────╢
║ PUBLIC │ ARTIST │ 18 │ 19 │ CHINOOK │ default │ ARTISTID ║
╟────────┼───────────────┼────┼─────────────┼───────────────────┼─────────────────┼──────────────────────╢
║ PUBLIC │ TRACK │ 26 │ 27 │ CHINOOK │ default │ ALBUMID ║
╟────────┼───────────────┼────┼─────────────┼───────────────────┼─────────────────┼──────────────────────╢
║ PUBLIC │ PLAYLIST │ 36 │ 37 │ CHINOOK │ default │ PLAYLISTID ║
╟────────┼───────────────┼────┼─────────────┼───────────────────┼─────────────────┼──────────────────────╢
║ PUBLIC │ PLAYLISTTRACK │ 38 │ 39 │ CHINOOK │ default │ PLAYLISTID, TRACKID ║
╟────────┼───────────────┼────┼─────────────┼───────────────────┼─────────────────┼──────────────────────╢
║ PUBLIC │ MEDIATYPE │ 24 │ 25 │ CHINOOKREPLICATED │ default │ MEDIATYPEID ║
╟────────┼───────────────┼────┼─────────────┼───────────────────┼─────────────────┼──────────────────────╢
║ PUBLIC │ INVOICELINE │ 34 │ 35 │ CHINOOK │ default │ TRACKID ║
╟────────┼───────────────┼────┼─────────────┼───────────────────┼─────────────────┼──────────────────────╢
║ PUBLIC │ EMPLOYEE │ 28 │ 29 │ CHINOOK │ default │ EMPLOYEEID ║
╟────────┼───────────────┼────┼─────────────┼───────────────────┼─────────────────┼──────────────────────╢
║ PUBLIC │ CUSTOMER │ 30 │ 31 │ CHINOOK │ default │ CUSTOMERID ║
╟────────┼───────────────┼────┼─────────────┼───────────────────┼─────────────────┼──────────────────────╢
║ PUBLIC │ INVOICE │ 32 │ 33 │ CHINOOK │ default │ CUSTOMERID ║
╚════════╧═══════════════╧════╧═════════════╧═══════════════════╧═════════════════╧══════════════════════╝注意
检查点:在继续下一步之前,需验证所有system.tables中的表是否显示在输出中,并具有正确的分布区和并置设置。
6.插入示例数据
表建好之后,下面会插入一些示例数据。
6.1.添加艺术家和专辑
下面从添加一些艺术家开始。
- 执行
exit退出交互式 SQL 模式; - 然后从 sql 数据文件加载数据。
sql --file=/opt/ignite/downloads/current_catalog.sqlsql-cli> exit;
[node1]> sql --file=/opt/ignite/downloads/current_catalog.sql
Updated 275 rows.
Updated 347 rows.6.2.添加流派和媒体类型
下面以同样的方式加载对照表:
sql --file=/opt/ignite/downloads/media_and_genre.sql[node1]> sql --file=/opt/ignite/downloads/media_and_genre.sql
Updated 25 rows.
Updated 5 rows.6.3.添加曲目
下面在专辑中添加一些曲目:
sql --file=/opt/ignite/downloads/tracks.sql[node1]> sql --file=/opt/ignite/downloads/tracks.sql
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 503 rows.6.4.添加员工和客户
下面添加一些员工和客户数据:
sql --file=/opt/ignite/downloads/ee_and_cust.sql[node1]> sql --file=/opt/ignite/downloads/ee_and_cust.sql
Updated 8 rows.
Updated 59 rows.6.5.添加发票和发票行
最后再添加一些销售数据:
sql --file=/opt/ignite/downloads/invoices.sql[node1]> sql --file=/opt/ignite/downloads/invoices.sql
Updated 412 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 240 rows.
Updated 18 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 715 rows.提示
检查点:通过Updated X rows消息来确认是否与每个文件的预期行计数匹配,验证所有数据是否已成功加载。
7.在 Ignite SQL 中查询数据
现在表中已经有了数据,就可以执行一些 SQL 查询来探索 Chinook 数据库。
7.1.基本查询
下面回到sql-cli>并从一些简单的 SELECT 查询开始:
sql-- Get all artists
SELECT * FROM Artist;
-- Get all albums for a specific artist
SELECT * FROM Album WHERE ArtistId = 3;
-- Get all tracks for a specific album
SELECT * FROM Track WHERE AlbumId = 133;7.2.联接
现在会尝试一些更复杂的联接查询:
-- Get all tracks with artist and album information
SELECT
t.Name AS TrackName,
a.Title AS AlbumTitle,
ar.Name AS ArtistName
FROM
Track t
JOIN Album a ON t.AlbumId = a.AlbumId
JOIN Artist ar ON a.ArtistId = ar.ArtistId
LIMIT 10;8.Ignite SQL 中的数据操作
下面会介绍如何在 Ignite 中使用 SQL 修改数据。
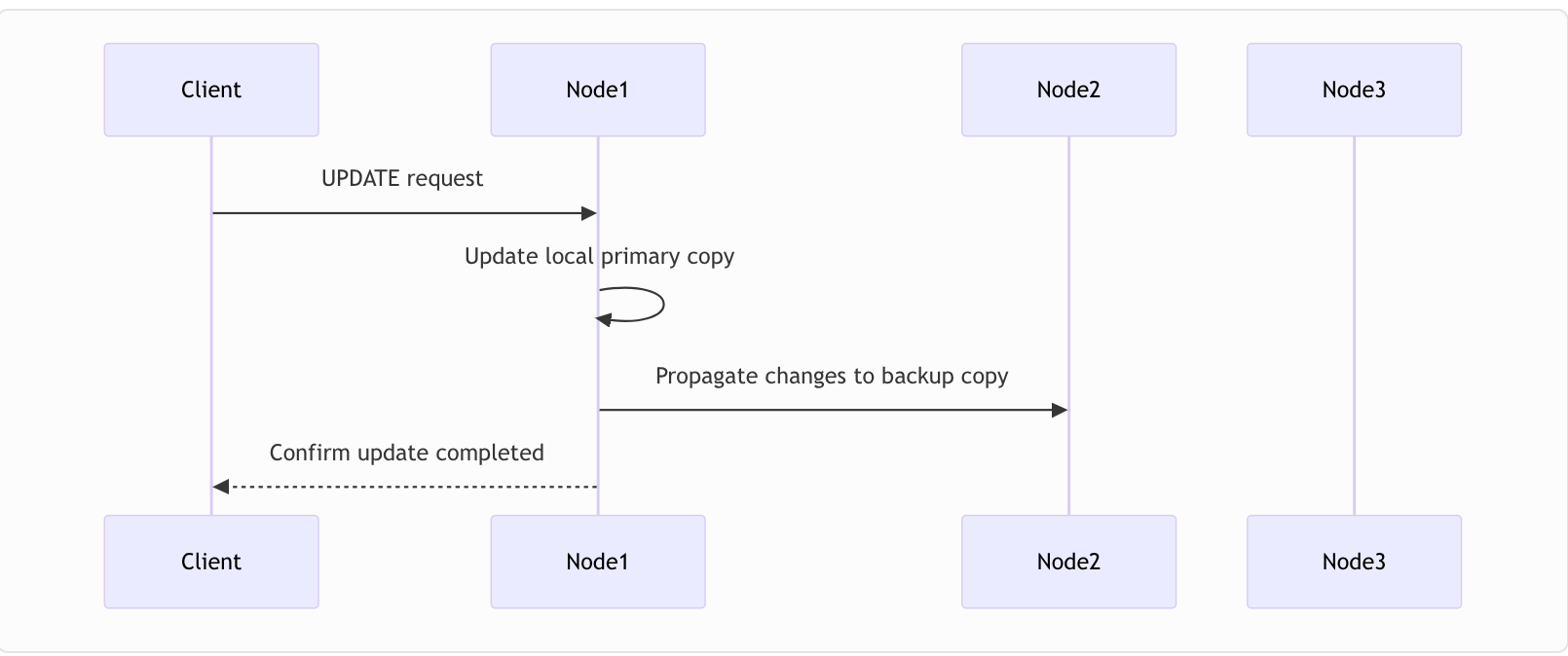
8.1.了解分布式更新
更新分布式数据库中的数据时,需要跨多个节点协调更改:
8.2.插入新数据
下面添加一个新的艺术家和专辑:
-- Insert a new artist
INSERT INTO Artist (ArtistId, Name)
VALUES (276, 'New Discovery Band');
-- Insert a new album for this artist
INSERT INTO Album (AlbumId, Title, ArtistId, ReleaseYear)
VALUES (348, 'First Light', 276, 2023);
-- Verify the insertions
SELECT * FROM Artist WHERE ArtistId = 276;
SELECT * FROM Album WHERE AlbumId = 348;8.3.更新现有数据
下面更新一些现有数据:
-- Update the album release year
UPDATE Album
SET ReleaseYear = 2024
WHERE AlbumId = 348;
-- Update the artist name
UPDATE Artist
SET Name = 'New Discovery Ensemble'
WHERE ArtistId = 276;
-- Verify the updates
SELECT * FROM Artist WHERE ArtistId = 276;
SELECT * FROM Album WHERE AlbumId = 348;在像 Ignite 这样的分布式数据库中,这些更新会自动传播到所有副本。首先更新主副本,然后将更改发送到其他节点上的备份副本。
8.4.删除数据
最后,通过删除刚添加的数据来清理:
-- Delete the album
DELETE FROM Album WHERE AlbumId = 348;
-- Delete the artist
DELETE FROM Artist WHERE ArtistId = 276;
-- Verify the deletions
SELECT * FROM Artist WHERE ArtistId = 276;
SELECT * FROM Album WHERE AlbumId = 348;9.高级 SQL 功能
下面看下 Ignite 的一些更高级的 SQL 功能。
9.1.查询系统视图
Ignite 提供系统视图,可以查询集群元数据:
-- View all tables in the cluster
SELECT * FROM system.tables;
-- View all zones
SELECT * FROM system.zones;
-- View all columns for a specific table
SELECT * FROM system.table_columns WHERE TABLE_NAME = 'TRACK';系统视图提供有关集群配置的重要元数据信息,它们对于生产环境中的监控和故障排除至关重要。
9.2.创建索引以提高性能
下面创建一些索引来提高查询性能:
-- Create an index on the Name column of the Track table
CREATE INDEX idx_track_name ON Track (Name);
-- Create a composite index on Artist and Album
CREATE INDEX idx_album_artist ON Album (ArtistId, Title);
-- Create a composite index on Track's AlbumId and Name columns to optimize joins with Album table
-- and to improve performance when filtering or sorting by track name within an album
CREATE INDEX idx_track_albumid_name ON Track(AlbumId, Name);
-- Create an index on Album Title to speed up searches and sorts by album title
CREATE INDEX idx_album_title ON Album(Title);
-- Create a composite index on InvoiceLine connecting TrackId and InvoiceId
-- This supports efficient queries that join InvoiceLine with Track while filtering by InvoiceId
CREATE INDEX idx_invoiceline_trackid_invoiceid ON InvoiceLine(TrackId, InvoiceId);
-- Create a hash index for lookups by email
CREATE INDEX idx_customer_email ON Customer USING HASH (Email);
-- Check index information
SELECT * FROM system.indexes;索引可以提高查询性能,但会产生维护成本,每个写入操作还必须更新所有索引。所以要为最常见的查询模式维护索引,而不是为所有列创建索引。
10.使用 SQL 创建仪表板
下面是可用于音乐商店仪表板的 SQL 查询,可以保存这些查询并定期运行以生成报告。
10.1.月度销售汇总
-- Monthly sales summary for the last 12 months
SELECT
CAST(EXTRACT(YEAR FROM i.InvoiceDate) AS VARCHAR) || '-' ||
CASE
WHEN EXTRACT(MONTH FROM i.InvoiceDate) < 10
THEN '0' || CAST(EXTRACT(MONTH FROM i.InvoiceDate) AS VARCHAR)
ELSE CAST(EXTRACT(MONTH FROM i.InvoiceDate) AS VARCHAR)
END AS YearMonth,
COUNT(DISTINCT i.InvoiceId) AS InvoiceCount,
COUNT(DISTINCT i.CustomerId) AS CustomerCount,
SUM(i.Total) AS MonthlyRevenue,
AVG(i.Total) AS AverageOrderValue
FROM
Invoice i
GROUP BY
EXTRACT(YEAR FROM i.InvoiceDate), EXTRACT(MONTH FROM i.InvoiceDate)
ORDER BY
YearMonth DESC;该查询将年份和月份格式化为可排序字符串(YYYY-MM),同时计算几个关键业务指标。
10.2.最畅销的流派
-- Top selling genres by revenue
SELECT
g.Name AS Genre,
SUM(il.UnitPrice * il.Quantity) AS Revenue
FROM
InvoiceLine il
JOIN Track t ON il.TrackId = t.TrackId
JOIN Genre g ON t.GenreId = g.GenreId
GROUP BY
g.Name
ORDER BY
Revenue DESC;10.3.按员工划分的销售业绩
-- Sales performance by employee
SELECT
e.EmployeeId,
e.FirstName || ' ' || e.LastName AS EmployeeName,
COUNT(DISTINCT i.InvoiceId) AS TotalInvoices,
COUNT(DISTINCT i.CustomerId) AS UniqueCustomers,
SUM(i.Total) AS TotalSales
FROM
Employee e
JOIN Customer c ON e.EmployeeId = c.SupportRepId
JOIN Invoice i ON c.CustomerId = i.CustomerId
GROUP BY
e.EmployeeId, e.FirstName, e.LastName
ORDER BY
TotalSales DESC;10.4.前20首最长的歌曲流派
-- Top 20 longest tracks with genre information
SELECT
t.trackid,
t.name AS track_name,
g.name AS genre_name,
ROUND(t.milliseconds / (1000 * 60), 2) AS duration_minutes
FROM
track t
JOIN genre g ON t.genreId = g.genreId
WHERE
t.genreId < 17
ORDER BY
duration_minutes DESC
LIMIT
20;10.5.按月划分的客户购买模式
-- Customer purchase patterns by month
SELECT
c.CustomerId,
c.FirstName || ' ' || c.LastName AS CustomerName,
CAST(EXTRACT(YEAR FROM i.InvoiceDate) AS VARCHAR) || '-' ||
CASE
WHEN EXTRACT(MONTH FROM i.InvoiceDate) < 10
THEN '0' || CAST(EXTRACT(MONTH FROM i.InvoiceDate) AS VARCHAR)
ELSE CAST(EXTRACT(MONTH FROM i.InvoiceDate) AS VARCHAR)
END AS YearMonth,
COUNT(DISTINCT i.InvoiceId) AS NumberOfPurchases,
SUM(i.Total) AS TotalSpent,
SUM(i.Total) / COUNT(DISTINCT i.InvoiceId) AS AveragePurchaseValue
FROM
Customer c
JOIN Invoice i ON c.CustomerId = i.CustomerId
GROUP BY
c.CustomerId, c.FirstName, c.LastName,
EXTRACT(YEAR FROM i.InvoiceDate), EXTRACT(MONTH FROM i.InvoiceDate)
ORDER BY
c.CustomerId, YearMonth;11.使用并置表进行性能调整
Ignite 的主要优势之一是它能够通过数据并置优化联接,下面使用现有的并置表来演示这一点。
11.1.并置查询
先看下不匹配并置策略的查询。
--This is an example of a poorly created table.
CREATE TABLE InvoiceLine (
InvoiceLineId INT NOT NULL,
InvoiceId INT NOT NULL,
TrackId INT NOT NULL,
UnitPrice NUMERIC(10,2) NOT NULL,
Quantity INT NOT NULL,
PRIMARY KEY (InvoiceLineId, InvoiceId)
) COLOCATE BY (InvoiceId) ZONE Chinook;如果创建的InvoiceLine表由InvoiceId并置,则最终会导致查询不匹配。
Album由ArtistId并置;Track由AlbumId并置;InvoiceLine由InvoiceId并置。
这时当执行联接 InvoiceLine、Track 和 Album 的查询时,因为并置键不同,数据可能会分布在不同的节点上。查询是查找InvoiceId为 1,然后与 Track 和 Album 联接,但这些表位于不同的并置键上。
EXPLAIN PLAN FOR
SELECT
il.InvoiceId,
COUNT(il.InvoiceLineId) AS LineItemCount,
SUM(il.UnitPrice * il.Quantity) AS InvoiceTotal,
t.Name AS TrackName,
a.Title AS AlbumTitle
FROM
InvoiceLine il
JOIN Track t ON il.TrackId = t.TrackId
JOIN Album a ON t.AlbumId = a.AlbumId
WHERE
il.InvoiceId = 1
GROUP BY
il.InvoiceId, t.Name, a.Title;╔═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╗
║ PLAN ║
╠═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╣
║ Project(INVOICEID=[$0], LINEITEMCOUNT=[$3], INVOICETOTAL=[$4], TRACKNAME=[$1], ALBUMTITLE=[$2]): rowcount = 4484471.100479999, cumulative cost = IgniteCost [rowCount=2.3054813220479995E7, cpu=2.3643376967575923E7, memory=9.866772781055996E7, io=2.0, network=50190.0], id = 23843 ║
║ ColocatedHashAggregate(group=[{0, 1, 2}], LINEITEMCOUNT=[COUNT()], INVOICETOTAL=[SUM($3)]): rowcount = 4484471.100479999, cumulative cost = IgniteCost [rowCount=1.8570341119999997E7, cpu=1.9158904867095925E7, memory=9.866772681055996E7, io=1.0, network=50189.0], id = 23842 ║
║ Project(INVOICEID=[$3], TRACKNAME=[$1], ALBUMTITLE=[$8], $f4=[*($5, $6)]): rowcount = 9189489.959999999, cumulative cost = IgniteCost [rowCount=9380851.159999998, cpu=9969414.907095924, memory=9362.6, io=1.0, network=50189.0], id = 23841 ║
║ MergeJoin(condition=[=($2, $7)], joinType=[inner], leftCollation=[[2]], rightCollation=[[0]]): rowcount = 9189489.959999999, cumulative cost = IgniteCost [rowCount=191360.19999999998, cpu=779923.9470959246, memory=9361.6, io=0.0, network=50188.0], id = 23840 ║
║ HashJoin(condition=[=($4, $0)], joinType=[inner]): rowcount = 176551.19999999998, cumulative cost = IgniteCost [rowCount=13421.0, cpu=65201.0, memory=6585.6, io=0.0, network=47412.0], id = 23836 ║
║ Exchange(distribution=[single]): rowcount = 3503.0, cumulative cost = IgniteCost [rowCount=7006.0, cpu=17515.0, memory=0.0, io=0.0, network=42036.0], id = 23833 ║
║ IndexScan(table=[[PUBLIC, TRACK]], tableId=[26], index=[IDX_TRACK_ALBUMID_NAME], type=[SORTED], requiredColumns=[{0, 1, 2}], collation=[[2, 1]]): rowcount = 3503.0, cumulative cost = IgniteCost [rowCount=3503.0, cpu=14012.0, memory=0.0, io=0.0, network=0.0], id = 23832 ║
║ Exchange(distribution=[single]): rowcount = 336.0, cumulative cost = IgniteCost [rowCount=2576.0, cpu=9296.0, memory=0.0, io=0.0, network=5376.0], id = 23835 ║
║ TableScan(table=[[PUBLIC, INVOICELINE]], tableId=[34], filters=[=($t0, 1)], requiredColumns=[{1, 2, 3, 4}]): rowcount = 336.0, cumulative cost = IgniteCost [rowCount=2240.0, cpu=8960.0, memory=0.0, io=0.0, network=0.0], id = 23834 ║
║ Exchange(distribution=[single]): rowcount = 347.0, cumulative cost = IgniteCost [rowCount=1041.0, cpu=7130.147095924681, memory=2776.0, io=0.0, network=2776.0], id = 23839 ║
║ Sort(sort0=[$0], dir0=[ASC]): rowcount = 347.0, cumulative cost = IgniteCost [rowCount=694.0, cpu=6783.147095924681, memory=2776.0, io=0.0, network=0.0], id = 23838 ║
║ TableScan(table=[[PUBLIC, ALBUM]], tableId=[20], requiredColumns=[{0, 1}]): rowcount = 347.0, cumulative cost = IgniteCost [rowCount=347.0, cpu=347.0, memory=0.0, io=0.0, network=0.0], id = 23837 ║
╚═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╝11.1.1.执行计划中的关键点
并置哈希聚合操作:该计划使用一个ColocatedHashAggregate操作,该操作表示 Ignite 识别出在合并结果之前,聚合的部分可能会发生在并置数据上,这减少了GROUP BY操作期间的网络传输。
交换操作:计划中出现多个Exchange(distribution=[single])操作,表明仍然需要在节点之间移动数据,这些操作应用于Album表、Track表和InvoiceLine。
联接实现:该计划显示了哈希联接和合并联接操作的组合,而不是嵌套循环联接。优化器已确定该连接类型对于所涉及的数据量更有效:
Track和Album的联接使用哈希联接;- 上述结果与
InvoiceLine的联接使用合并联接。
高效的数据访问:查询使用名为IDX_INVOICELINE_INVOICE_TRACK的索引扫描,而不是 InvoiceLine 上的全表扫描,这提供了如下的能力:
- 针对
InvoiceId = 1,使用searchBounds: [ExactBounds [bound=1], null]进行高效筛选; - 使用
collation: [INVOICEID ASC, TRACKID ASC]对结果进行预排序。
行数估计:联接后的估计行数似乎有显著增加:
- 初始
InvoiceLine筛选行数:746 - 与
Album哈希联接后:182,331 - 与
Track合并联接后:20,400,668
11.2.改进的并置策略
如果创建的InvoiceLine表由TrackId并置,则会极大地优化前述查询。
--This table was already created on an earlier step.
CREATE TABLE InvoiceLine (
InvoiceLineId INT NOT NULL,
InvoiceId INT NOT NULL,
TrackId INT NOT NULL,
UnitPrice NUMERIC(10,2) NOT NULL,
Quantity INT NOT NULL,
PRIMARY KEY (InvoiceLineId, TrackId)
) COLOCATE BY (TrackId) ZONE Chinook;然后再执行一次EXPLAIN PLAN FOR:
EXPLAIN PLAN FOR
SELECT
il.InvoiceId,
COUNT(il.InvoiceLineId) AS LineItemCount,
SUM(il.UnitPrice * il.Quantity) AS InvoiceTotal,
t.Name AS TrackName,
a.Title AS AlbumTitle
FROM
Track t
JOIN Album a ON t.AlbumId = a.AlbumId
JOIN InvoiceLine il ON t.TrackId = il.TrackId
WHERE
il.InvoiceId = 1
GROUP BY
il.InvoiceId, t.Name, a.Title;╔════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╗
║ PLAN ║
╠════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╣
║ Project(INVOICEID=[$0], LINEITEMCOUNT=[$3], INVOICETOTAL=[$4], TRACKNAME=[$1], ALBUMTITLE=[$2]): rowcount = 2.0019960269999995E9, cumulative cost = IgniteCost [rowCount=1.020839200715E10, cpu=1.0214411135647097E10, memory=4.404685537199999E10, io=2.0, network=2444814.0], id = 25112 ║
║ ColocatedHashAggregate(group=[{0, 1, 2}], LINEITEMCOUNT=[COUNT()], INVOICETOTAL=[SUM($3)]): rowcount = 2.0019960269999995E9, cumulative cost = IgniteCost [rowCount=8.20639597915E9, cpu=8.212415107647097E9, memory=4.404685537099999E10, io=1.0, network=2444813.0], id = 25111 ║
║ Project(INVOICEID=[$5], TRACKNAME=[$1], ALBUMTITLE=[$4], $f4=[*($7, $8)]): rowcount = 4.102450875E9, cumulative cost = IgniteCost [rowCount=4.10394510415E9, cpu=4.109964232647096E9, memory=2942777.0, io=1.0, network=2444813.0], id = 25110 ║
║ HashJoin(condition=[=($0, $6)], joinType=[inner]): rowcount = 4.102450875E9, cumulative cost = IgniteCost [rowCount=1494228.15, cpu=7513356.647095924, memory=2942776.0, io=0.0, network=2444812.0], id = 25109 ║
║ MergeJoin(condition=[=($2, $3)], joinType=[inner], leftCollation=[[2, 1]], rightCollation=[[0]]): rowcount = 182331.15, cumulative cost = IgniteCost [rowCount=11897.0, cpu=40045.14709592468, memory=2776.0, io=0.0, network=44812.0], id = 25106 ║
║ Exchange(distribution=[single]): rowcount = 3503.0, cumulative cost = IgniteCost [rowCount=7006.0, cpu=17515.0, memory=0.0, io=0.0, network=42036.0], id = 25102 ║
║ IndexScan(table=[[PUBLIC, TRACK]], tableId=[26], index=[IDX_TRACK_ALBUMID_NAME], type=[SORTED], requiredColumns=[{0, 1, 2}], collation=[[2, 1]]): rowcount = 3503.0, cumulative cost = IgniteCost [rowCount=3503.0, cpu=14012.0, memory=0.0, io=0.0, network=0.0], id = 25101 ║
║ Exchange(distribution=[single]): rowcount = 347.0, cumulative cost = IgniteCost [rowCount=1041.0, cpu=7130.147095924681, memory=2776.0, io=0.0, network=2776.0], id = 25105 ║
║ Sort(sort0=[$0], dir0=[ASC]): rowcount = 347.0, cumulative cost = IgniteCost [rowCount=694.0, cpu=6783.147095924681, memory=2776.0, io=0.0, network=0.0], id = 25104 ║
║ TableScan(table=[[PUBLIC, ALBUM]], tableId=[20], requiredColumns=[{0, 1}]): rowcount = 347.0, cumulative cost = IgniteCost [rowCount=347.0, cpu=347.0, memory=0.0, io=0.0, network=0.0], id = 25103 ║
║ Exchange(distribution=[single]): rowcount = 150000.0, cumulative cost = IgniteCost [rowCount=1150000.0, cpu=4150000.0, memory=0.0, io=0.0, network=2400000.0], id = 25108 ║
║ TableScan(table=[[PUBLIC, INVOICELINE]], tableId=[46], filters=[=($t0, 1)], requiredColumns=[{1, 2, 3, 4}]): rowcount = 150000.0, cumulative cost = IgniteCost [rowCount=1000000.0, cpu=4000000.0, memory=0.0, io=0.0, network=0.0], id = 25107 ║
╚════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╝11.2.1.执行计划中的关键点
并置哈希聚合操作:该计划使用一个ColocatedHashAggregate操作,该操作表示 Ignite 识别出在合并结果之前,聚合的部分可能会发生在并置数据上,这减少了GROUP BY操作期间的网络传输。
改进的行数估计值:注意行数估计值的显著改进,现在每个步骤仅显示 1 行。这表明与估计数百万行的原始计划相比,优化器对实际数据分布的统计信息和理解要好得多。
联接实现:该计划显示了哈希联接和合并联接操作的组合:
Track和InvoiceLine的联接使用哈希联接;- 上述结果与
Album的联接使用合并联接。
高效的索引使用:查询现在使用 Track 表上的IDX_TRACK_ALBUMID_NAME复合索引,这提供了如下的能力:
- 按
AlbumId和Name进行高效排序访问; - 直接访问联接和选择操作所需的字段。
交换操作:虽然交换操作仍显示在计划中,但估计的行数现在很少(每个交换只有 1 行)。这表明与估计要传输数百万行的原始计划相比,节点之间的数据移动要少得多。
11.2.2.并置影响
该执行计划的实质性改进证明了 Ignite 中适当数据并置的强大功能,体现在:
- 优化查询以按最佳顺序联接表(
Track→Album→InvoiceLine); - 创建适当的索引;
- 确保相关表之间的正确并置。
这里大幅减少了估计的行数和数据移动。执行计划现在显示简化的操作,每个步骤的行估计数最少,这体现了利用数据局部性的一个高效执行路径。
该优化方法突出显示了分布式 SQL 数据库中实现最佳性能的三个关键原则:
- 相关数据的正确并置;
- 支持与联接模式对齐的索引;
- 遵循并置模型的查询结构。
12.清理
用完 Ignite SQL 命令行后,可以通过输入以下命令退出:
exit;这将返回到 Ignite 命令行,要退出 Ignite 命令行,可以再次输入:
exit要停止 Ignite 集群,可以在终端中执行以下命令:
docker compose down这将停止并删除 Ignite 集群的 Docker 容器。
13.Ignite SQL 的最佳实践
要充分利用 Ignite SQL,请遵循以下最佳实践:
13.1.模式设计
- 对频繁联接的表使用适当的并置策略;
- 选择在集群中均匀分布数据的主键;
- 在设计时要考虑查询模式,尤其是对于大规模部署。
13.2.查询优化
- 为
WHERE、JOIN、ORDER BY子句中使用的列创建索引; - 使用
EXPLAIN语句分析和优化查询; - 避免使用笛卡尔积和低效的联接条件。
13.3.事务管理
- 保持事务尽可能短;
- 不要在用户思考时间保持事务打开;
- 将相关操作分组到单个事务中以实现原子性。
13.4.资源管理
- 监控生产中的查询性能;
- 考虑非常大的表的分区策略;
- 使用适当的数据类型来最大程度地减少存储要求。
14.下一步
Ignite 的 SQL 功能使其成为构建需要高吞吐量、低延迟和强一致性的分布式应用的强大平台。通过遵循本章节中的模式和实践,就可以利用 Ignite SQL 构建可扩展、有弹性的系统。
请注意,Ignite 不仅仅是一个 SQL 数据库,它还是一个全面的分布式计算平台,其功能超出了这里介绍的范围。随着对 Ignite SQL 的熟悉程度越来越高,用户可能需要探索其他功能,例如计算网格、机器学习和流处理。
18624049226
